บทนำ
เอกสารนี้อธิบายวิธีสร้างโซลูชันการเลือกสถานที่ตั้งโดยการรวมชุดข้อมูล ข้อมูลเชิงลึกเกี่ยวกับสถานที่ ข้อมูลเชิงพื้นที่สาธารณะใน BigQuery และ Place Details API
โดยอิงตามการสาธิตที่ Google Cloud Next 2025 ซึ่งพร้อมให้รับชมบน YouTube นอกจากนี้ยังมี Colab Notebook ตัวอย่าง ซึ่งมีโค้ดสำหรับกระบวนการที่อธิบายไว้ในเอกสารในรูปแบบที่พร้อม เรียกใช้
ความท้าทายทางธุรกิจ
สมมติว่าคุณเป็นเจ้าของเครือข่ายร้านกาแฟที่ประสบความสำเร็จและต้องการขยายธุรกิจไปยังรัฐใหม่ เช่น รัฐเนวาดา ซึ่งคุณไม่มีสาขาอยู่ การเปิดสาขาใหม่เป็นการลงทุนที่สำคัญ และการตัดสินใจโดยอิงตามข้อมูลเป็นสิ่งสำคัญต่อความสำเร็จ คุณควรเริ่มจากตรงไหน
คู่มือนี้จะแนะนําการวิเคราะห์หลายชั้นเพื่อระบุตําแหน่งที่เหมาะสมที่สุด สําหรับร้านกาแฟใหม่ เราจะเริ่มจากมุมมองระดับรัฐ ค่อยๆ จำกัดการค้นหาให้แคบลงไปที่เขตและเขตการค้าที่เฉพาะเจาะจง และ สุดท้ายคือทำการวิเคราะห์แบบเฉพาะเจาะจงเพื่อให้คะแนนแต่ละพื้นที่และระบุ ช่องว่างทางการตลาดด้วยการทำแผนที่คู่แข่ง
เวิร์กโฟลว์ของโซลูชัน
กระบวนการนี้เป็นไปตาม Funnel ที่สมเหตุสมผล โดยเริ่มจากวงกว้างและค่อยๆ ละเอียดขึ้นเรื่อยๆ เพื่อปรับแต่งพื้นที่ค้นหาและเพิ่มความมั่นใจในการเลือกเว็บไซต์สุดท้าย
ข้อกำหนดเบื้องต้นและการตั้งค่าสภาพแวดล้อม
ก่อนที่จะเจาะลึกการวิเคราะห์ คุณต้องมีสภาพแวดล้อมที่มีความสามารถหลักๆ 2-3 อย่าง แม้ว่าคู่มือนี้จะอธิบายการติดตั้งใช้งานโดยใช้ SQL และ Python แต่หลักการทั่วไปก็สามารถนำไปใช้กับเทคโนโลยีอื่นๆ ได้
โปรดตรวจสอบว่าสภาพแวดล้อมของคุณทำสิ่งต่อไปนี้ได้
- เรียกใช้การค้นหาใน BigQuery
- เข้าถึงข้อมูลเชิงลึกของสถานที่ โปรดดูข้อมูลเพิ่มเติมที่ตั้งค่าข้อมูลเชิงลึกของสถานที่
- ติดตามชุดข้อมูลสาธารณะจาก
bigquery-public-dataและข้อมูลประชากรในแต่ละเคาน์ตีของสำนักสำรวจสำมะโนประชากรสหรัฐอเมริกา
นอกจากนี้ คุณยังต้องแสดงภาพข้อมูลเชิงพื้นที่บนแผนที่ได้ด้วย ซึ่งเป็นสิ่งสำคัญในการตีความผลลัพธ์ของแต่ละขั้นตอนการวิเคราะห์ การดำเนินการดังกล่าวทำได้หลายวิธี คุณสามารถใช้เครื่องมือ BI เช่น Looker Studio ซึ่งเชื่อมต่อกับ BigQuery โดยตรง หรือจะใช้ภาษาทางวิทยาศาสตร์ข้อมูล เช่น Python ก็ได้
การวิเคราะห์ระดับรัฐ: ค้นหาเคาน์ตีที่ดีที่สุด
ขั้นตอนแรกของเราคือการวิเคราะห์ในวงกว้างเพื่อระบุเขตที่น่าสนใจที่สุดในเนวาดา เราจะกำหนดมีแนวโน้มดีว่าเป็นการผสมผสานระหว่างประชากรจำนวนมากและความหนาแน่นสูงของร้านอาหารที่มีอยู่ ซึ่งบ่งบอกถึงวัฒนธรรมด้านอาหารและเครื่องดื่มที่แข็งแกร่ง
การค้นหา BigQuery ของเราทําให้สิ่งนี้สําเร็จได้โดยใช้ประโยชน์จาก address
components ในตัวที่มีอยู่ในชุดข้อมูลข้อมูลเชิงลึกเกี่ยวกับสถานที่ การค้นหาจะนับ
ร้านอาหารโดยกรองข้อมูลก่อนเพื่อให้รวมเฉพาะสถานที่ภายในรัฐ
เนวาดา โดยใช้ฟิลด์ administrative_area_level_1_name จากนั้นจะปรับแต่งชุดข้อมูลนี้เพิ่มเติม
เพื่อรวมเฉพาะสถานที่ที่อาร์เรย์ประเภทมี
'restaurant' สุดท้ายจะจัดกลุ่มผลลัพธ์เหล่านี้ตามชื่อเขต
(administrative_area_level_2_name) เพื่อสร้างจำนวนสำหรับแต่ละเขต วิธีนี้
ใช้โครงสร้างที่อยู่ที่มีการจัดทำดัชนีล่วงหน้าและมีอยู่แล้วในชุดข้อมูล
ข้อมูลที่ตัดตอนมานี้แสดงวิธีที่เราผสานรูปทรงเรขาคณิตของเขตกับข้อมูลเชิงลึกเกี่ยวกับสถานที่และกรอง
ประเภทสถานที่ที่เฉพาะเจาะจง restaurant:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
การนับร้านอาหารแบบดิบๆ ไม่เพียงพอ เราต้องปรับสมดุลด้วยข้อมูลประชากร เพื่อให้ทราบถึงการอิ่มตัวและโอกาสทางการตลาดอย่างแท้จริง เราจะใช้ข้อมูลประชากรจากข้อมูลประชากรระดับเคาน์ตีของสำนักงานสำมะโนประชากรของสหรัฐอเมริกา
เราใช้การปรับให้เป็นมาตรฐานแบบ Min-Max เพื่อเปรียบเทียบเมตริก 2 รายการที่แตกต่างกันมาก (จำนวนสถานที่เทียบกับจำนวนประชากรจำนวนมาก) เทคนิคนี้จะปรับขนาดทั้ง 2 เมตริก
ให้อยู่ในช่วงเดียวกัน (0 ถึง 1) จากนั้นเราจะรวมเมตริกเหล่านั้นไว้ในnormalized_scoreเดียว โดยให้น้ำหนัก 50% แก่แต่ละเมตริกเพื่อการเปรียบเทียบที่สมดุล
ข้อมูลที่ตัดตอนมานี้แสดงตรรกะหลักในการคำนวณคะแนน โดยจะรวม จำนวนประชากรและร้านอาหารที่ปรับให้เป็นมาตรฐาน
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
หลังจากเรียกใช้การค้นหาแบบเต็มแล้ว ระบบจะแสดงรายการเขต จำนวนร้านอาหาร
ประชากร และคะแนนที่ปรับให้เป็นมาตรฐาน การจัดเรียงตาม normalized_score
DESC แสดงให้เห็นว่า Clark County เป็นผู้ชนะอย่างชัดเจนสำหรับการตรวจสอบเพิ่มเติมในฐานะ
คู่แข่งอันดับต้นๆ
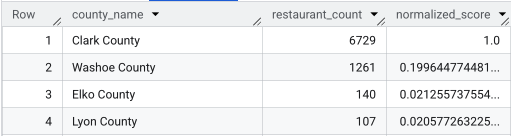
ภาพหน้าจอนี้แสดง 4 จังหวัดแรกตามคะแนนที่ปรับแล้ว ระบบจงใจละเว้นจำนวนประชากรดิบในตัวอย่างนี้
การวิเคราะห์ระดับเขต: ค้นหาย่านการค้าที่มีผู้คนพลุกพล่านที่สุด
เมื่อระบุคลาร์กเคาน์ตีแล้ว ขั้นตอนถัดไปคือการซูมเข้าเพื่อค้นหา รหัสไปรษณีย์ที่มีกิจกรรมเชิงพาณิชย์สูงสุด จากข้อมูลของร้านกาแฟที่มีอยู่ เราทราบว่าประสิทธิภาพจะดีขึ้นเมื่อตั้งอยู่ใกล้กับแบรนด์ใหญ่ๆ ที่มี ความหนาแน่นสูง ดังนั้นเราจะใช้ข้อมูลนี้เป็นตัวแทนของการเข้าชมสูง
คําค้นหานี้ใช้brandsตารางภายในข้อมูลเชิงลึกเกี่ยวกับสถานที่ ซึ่งมีข้อมูลเกี่ยวกับแบรนด์ที่เฉพาะเจาะจง คุณสามารถส่งคำค้นหาในตารางนี้เพื่อดูรายการ
แบรนด์ที่รองรับ</0x0A> ก่อนอื่นเราจะกำหนดรายชื่อแบรนด์เป้าหมาย จากนั้นจึงรวมรายชื่อนี้
กับชุดข้อมูลข้อมูลเชิงลึกเกี่ยวกับสถานที่หลักเพื่อดูว่าร้านค้าที่เฉพาะเจาะจงเหล่านี้
อยู่ในรหัสไปรษณีย์ใดบ้างในคลาร์กเคาน์ตี
วิธีที่มีประสิทธิภาพมากที่สุดในการดำเนินการนี้คือการใช้แนวทาง 2 ขั้นตอน ดังนี้
- ก่อนอื่น เราจะทำการรวบรวมข้อมูลแบบรวดเร็วที่ไม่ใช่เชิงพื้นที่เพื่อนับแบรนด์ ภายในรหัสไปรษณีย์แต่ละรหัส
- จากนั้นเราจะรวมผลลัพธ์เหล่านั้นกับชุดข้อมูลสาธารณะ เพื่อรับขอบเขตของแผนที่สำหรับการแสดงภาพ
นับแบรนด์โดยใช้ฟิลด์ postal_code_names
คําค้นหาแรกนี้จะทําตรรกะการนับหลัก โดยจะกรองสถานที่ใน
Clark County แล้วยกเลิกการซ้อนpostal_code_namesอาร์เรย์เพื่อจัดกลุ่มจำนวน
แบรนด์ตามรหัสไปรษณีย์
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
เอาต์พุตคือตารางรหัสไปรษณีย์และจำนวนแบรนด์ที่เกี่ยวข้อง

แนบรูปเรขาคณิตของรหัสไปรษณีย์สำหรับการทำแผนที่
เมื่อได้จำนวนแล้ว เราก็สามารถรับรูปร่างรูปหลายเหลี่ยมที่จำเป็นสำหรับการแสดงภาพได้
การค้นหาที่ 2 นี้ใช้การค้นหาแรกของเรา ห่อหุ้มไว้ในนิพจน์ของตารางทั่วไป (CTE) ที่ชื่อ brand_counts_by_zip และรวมผลลัพธ์เข้ากับ geo_us_boundaries.zip_codes table สาธารณะ ซึ่งจะแนบรูปทรงกับจำนวนที่คำนวณไว้ล่วงหน้าได้อย่างมีประสิทธิภาพ
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
เอาต์พุตคือตารางรหัสไปรษณีย์ จำนวนแบรนด์ที่เกี่ยวข้อง และ รูปเรขาคณิตของรหัสไปรษณีย์

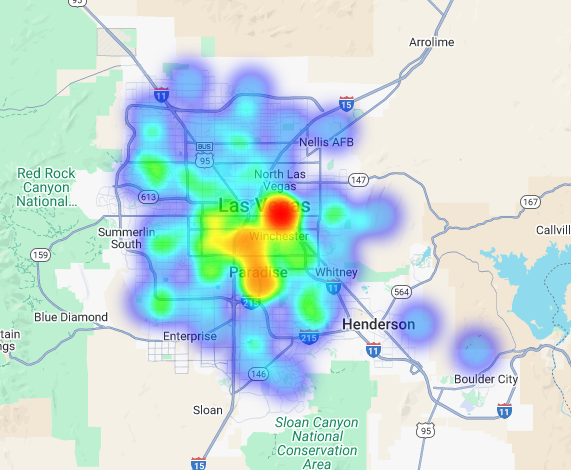
เราสามารถแสดงข้อมูลนี้เป็นภาพ ในรูปแบบแผนที่ความหนาแน่น พื้นที่สีแดงเข้มแสดงถึงความหนาแน่นของแบรนด์เป้าหมายที่สูงขึ้น ซึ่งชี้ให้เห็นถึงโซนที่มีความหนาแน่นเชิงพาณิชย์มากที่สุดในลาสเวกัส
การวิเคราะห์แบบเฉพาะเจาะจง: ให้คะแนนพื้นที่กริดแต่ละแห่ง
เมื่อระบุพื้นที่ทั่วไปของลาสเวกัสแล้ว ก็ถึงเวลาวิเคราะห์แบบละเอียด ซึ่งเป็นจุดที่เรานำความรู้ทางธุรกิจที่เฉพาะเจาะจงมาใช้ เราทราบว่า ร้านกาแฟที่ยอดเยี่ยมจะเติบโตได้ดีเมื่ออยู่ใกล้กับธุรกิจอื่นๆ ที่มีลูกค้าจำนวนมากในช่วงเวลาที่มีการสั่งซื้อสูงสุด เช่น ช่วงสายและช่วงพักกลางวัน
คำค้นหาถัดไปของเราจะมีความเฉพาะเจาะจงมาก โดยเริ่มจากการสร้างตารางกริดหกเหลี่ยมแบบละเอียด เหนือพื้นที่มหานครลาสเวกัสโดยใช้ดัชนีเชิงพื้นที่ H3 มาตรฐาน (ที่ความละเอียด 8) เพื่อวิเคราะห์พื้นที่ในระดับไมโคร คําค้นหาจะระบุธุรกิจเสริมทั้งหมดที่เปิดทําการในช่วงเวลาที่มีการเข้าชมสูงสุด (วันจันทร์ เวลา 10:00-14:00 น.) ก่อน
จากนั้นเราจะใช้คะแนนถ่วงน้ำหนักกับสถานที่แต่ละประเภท ร้านอาหารที่อยู่ใกล้เคียงมี
คุณค่ามากกว่าร้านสะดวกซื้อ เราจึงให้ตัวคูณที่สูงกว่า ซึ่งจะช่วยให้เรามี suitability_score ที่กำหนดเองสำหรับแต่ละพื้นที่ขนาดเล็ก
ข้อมูลที่ตัดตอนมานี้ไฮไลต์ตรรกะการให้คะแนนแบบถ่วงน้ำหนัก ซึ่งอ้างอิงถึง
แฟล็กที่คำนวณไว้ล่วงหน้า (is_open_monday_window) สำหรับการตรวจสอบเวลาทำการ
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
ขยายเพื่อดูคำค้นหาแบบเต็ม
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
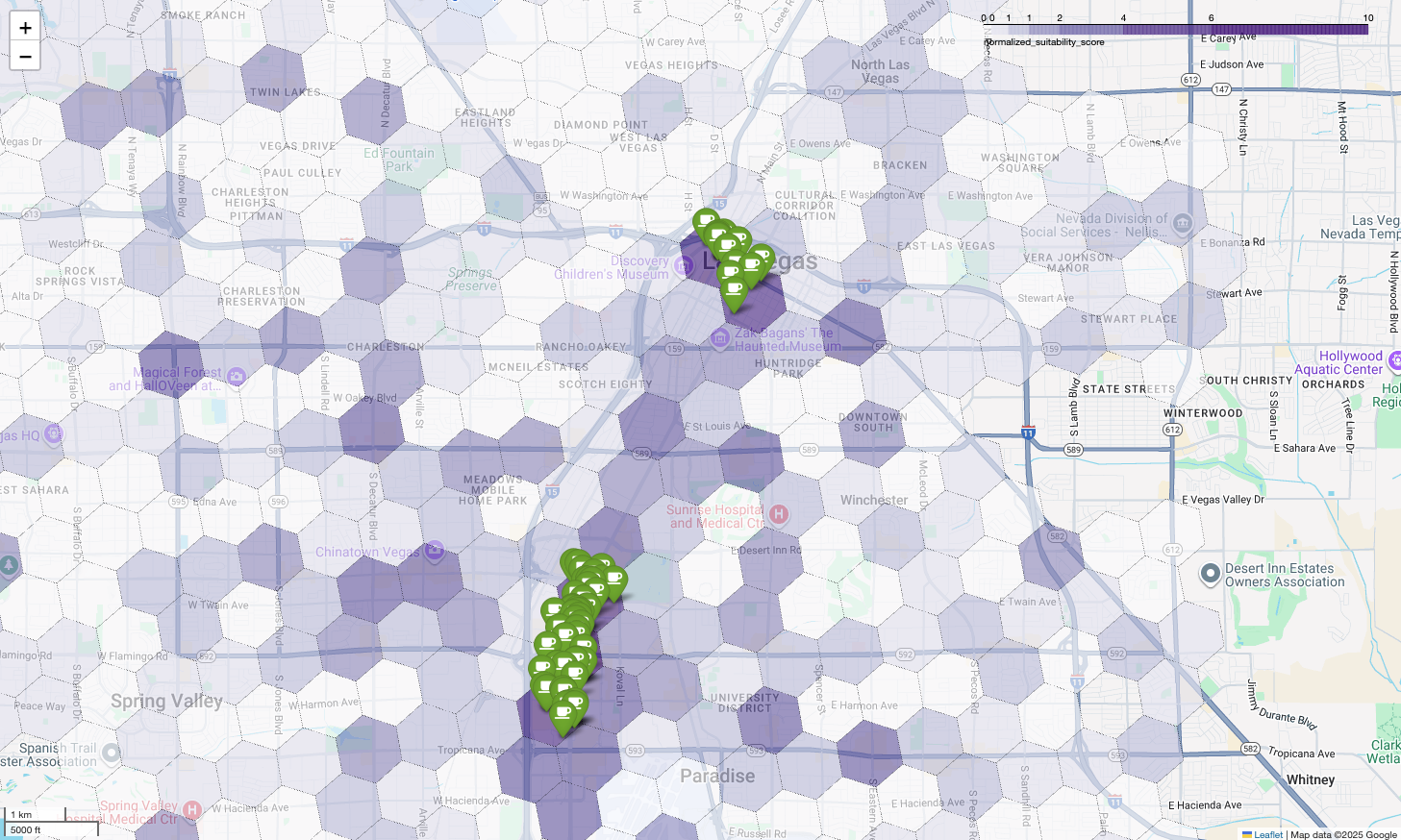
การแสดงคะแนนเหล่านี้บนแผนที่จะเผยให้เห็นตำแหน่งที่ชนะอย่างชัดเจน ส่วนกระเบื้องสีม่วงเข้มที่สุด ซึ่งส่วนใหญ่อยู่ใกล้กับลาสเวกัสสตริปและดาวน์ทาวน์ เป็นพื้นที่ที่มีศักยภาพสูงสุดสำหรับร้านกาแฟใหม่ของเรา

การวิเคราะห์คู่แข่ง: ระบุร้านกาแฟที่มีอยู่
โมเดลความเหมาะสมของเราได้ระบุโซนที่มีแนวโน้มมากที่สุดได้สำเร็จ แต่ คะแนนสูงเพียงอย่างเดียวไม่ได้รับประกันความสำเร็จ ตอนนี้เราต้องซ้อนทับข้อมูลนี้กับ ข้อมูลคู่แข่ง ทำเลที่ตั้งในอุดมคติคือพื้นที่ที่มีศักยภาพสูงและมีร้านกาแฟอยู่ไม่หนาแน่น เนื่องจากเรากำลังมองหาช่องว่างทางการตลาดที่ชัดเจน
เราใช้ฟังก์ชัน
PLACES_COUNT_PER_H3
เพื่อให้บรรลุเป้าหมายนี้ ฟังก์ชันนี้ออกแบบมาเพื่อแสดงผลจำนวนสถานที่ภายในภูมิศาสตร์ที่ระบุอย่างมีประสิทธิภาพตามเซลล์ H3
ก่อนอื่น เราจะกำหนดภูมิศาสตร์แบบไดนามิกสำหรับพื้นที่ในเมืองใหญ่ทั้งหมดของลาสเวกัส
เราจะค้นหาชุดข้อมูล Overture Maps สาธารณะเพื่อรับขอบเขตของลาสเวกัสและพื้นที่โดยรอบที่สำคัญแทนที่จะอาศัยเพียงพื้นที่เดียว
แล้วรวมขอบเขตเหล่านั้นเป็นรูปหลายเหลี่ยมเดียวที่มี ST_UNION_AGG จากนั้นเราจะส่งพื้นที่นี้
ไปยังฟังก์ชันเพื่อขอให้ฟังก์ชันนับร้านกาแฟที่เปิดดำเนินการทั้งหมด
การค้นหานี้จะกำหนดพื้นที่เมโทรและเรียกใช้ฟังก์ชันเพื่อรับจำนวนร้านกาแฟ ในเซลล์ H3
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
ฟังก์ชันจะแสดงผลตารางที่มีดัชนีเซลล์ H3, เรขาคณิต, จำนวนร้านกาแฟทั้งหมด และตัวอย่างรหัสสถานที่

แม้ว่าจำนวนรวมจะมีประโยชน์ แต่การดูคู่แข่งที่แท้จริงก็เป็นสิ่งจำเป็น
ในส่วนนี้ เราจะเปลี่ยนจากชุดข้อมูลข้อมูลเชิงลึกของสถานที่ไปยัง Places
API การดึงsample_place_idsจากเซลล์ที่มีคะแนนความเหมาะสมที่ปรับให้เป็นมาตรฐานสูงสุด
ช่วยให้เราเรียกใช้ Place Details
API เพื่อดึงรายละเอียดที่สมบูรณ์
สำหรับคู่แข่งแต่ละรายได้ เช่น ชื่อ ที่อยู่ คะแนน และสถานที่ตั้ง
ซึ่งต้องเปรียบเทียบผลลัพธ์ของคำค้นหาก่อนหน้าซึ่งมีการสร้างคะแนนความเหมาะสม
และคำค้นหา PLACES_COUNT_PER_H3 ดัชนีเซลล์ H3 สามารถใช้เพื่อรับจำนวนและรหัสร้านกาแฟจากเซลล์ที่มีคะแนนความเหมาะสมที่ปรับให้เป็นมาตรฐานสูงสุด
โค้ด Python นี้แสดงให้เห็นวิธีเปรียบเทียบ
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
ตอนนี้เรามีรายการรหัสสถานที่สำหรับร้านกาแฟที่มีอยู่แล้วภายใน เซลล์ H3 ที่มีคะแนนความเหมาะสมสูงสุดแล้ว และสามารถขอรายละเอียดเพิ่มเติมเกี่ยวกับแต่ละสถานที่ได้
ซึ่งทำได้โดยส่งคำขอไปยัง Place Details
API โดยตรงสำหรับ
Place ID แต่ละรายการ หรือใช้ไลบรารี
ไคลเอ็นต์เพื่อทำการเรียก อย่าลืมตั้งค่าพารามิเตอร์
FieldMask
เพื่อขอเฉพาะข้อมูลที่ต้องการ
สุดท้าย เราจะรวมทุกอย่างไว้ในการแสดงภาพเดียวที่มีประสิทธิภาพ เราจะวางแผนที่ฮอโรเพลทความเหมาะสมสีม่วงเป็นเลเยอร์ฐาน แล้วเพิ่มหมุดสำหรับ ร้านกาแฟแต่ละร้านที่ดึงมาจาก Places API แผนที่สุดท้ายนี้ แสดงภาพรวมที่สังเคราะห์การวิเคราะห์ทั้งหมดของเรา โดยพื้นที่สีม่วงเข้ม แสดงถึงศักยภาพ และหมุดสีเขียวแสดงถึงความเป็นจริงของ ตลาดปัจจุบัน
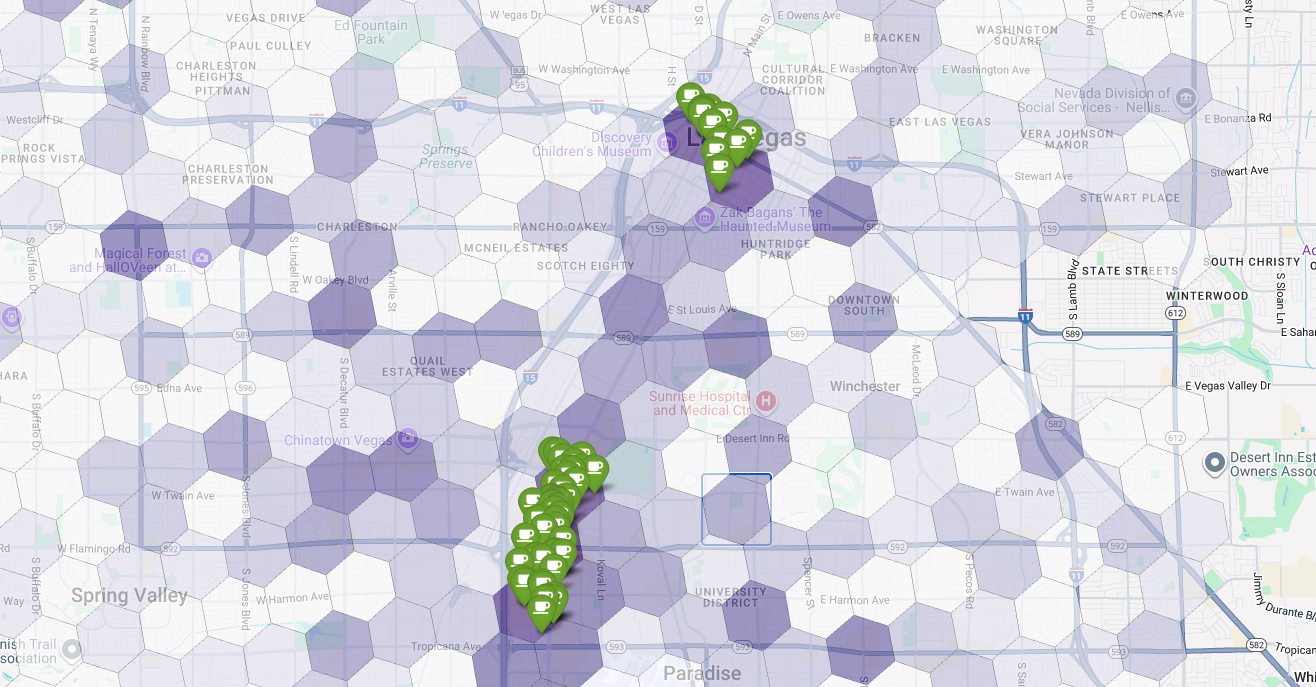
การมองหาเซลล์สีม่วงเข้มที่มีหมุดน้อยหรือไม่มีเลยช่วยให้เรามั่นใจได้ว่า จะระบุพื้นที่ที่แน่นอนซึ่งเป็นโอกาสที่ดีที่สุดสำหรับ สถานที่ตั้งใหม่ของเรา

ทั้ง 2 เซลล์ด้านบนมีคะแนนความเหมาะสมสูง แต่ก็มีช่องว่างที่ชัดเจน ซึ่งอาจเป็นทำเลที่ตั้งใหม่สำหรับร้านกาแฟของเรา
บทสรุป
ในเอกสารนี้ เราได้เปลี่ยนจากคำถามระดับรัฐว่าจะขยายบริการไปที่ไหน เป็นคำตอบในระดับท้องถิ่นที่อิงตามข้อมูล การซ้อนทับชุดข้อมูลต่างๆ และการใช้ตรรกะทางธุรกิจที่กำหนดเองจะช่วยให้คุณลดความเสี่ยงที่เกี่ยวข้องกับการตัดสินใจทางธุรกิจที่สำคัญได้อย่างเป็นระบบ เวิร์กโฟลว์นี้ซึ่งรวมความสามารถในการปรับขนาดของ BigQuery, ความสมบูรณ์ของข้อมูลเชิงลึกเกี่ยวกับสถานที่ และรายละเอียดแบบเรียลไทม์ของ Places API เข้าด้วยกัน จะเป็นเทมเพลตที่มีประสิทธิภาพสำหรับองค์กรที่ต้องการใช้ข้อมูลเชิงลึกด้านตำแหน่งเพื่อการเติบโตเชิงกลยุทธ์
ขั้นตอนถัดไป
- ปรับเวิร์กโฟลว์นี้ให้สอดคล้องกับตรรกะทางธุรกิจ ภูมิศาสตร์เป้าหมาย และชุดข้อมูลที่เป็นกรรมสิทธิ์ของคุณ
- สํารวจฟิลด์ข้อมูลอื่นๆ ในชุดข้อมูลข้อมูลเชิงลึกของสถานที่ เช่น จํานวนรีวิว ระดับราคา และคะแนนของผู้ใช้ เพื่อเพิ่มคุณค่าให้กับโมเดลของคุณ
- ทําให้กระบวนการนี้เป็นแบบอัตโนมัติเพื่อสร้างแดชบอร์ดการเลือกเว็บไซต์ภายในที่ใช้ประเมินตลาดใหม่แบบไดนามิกได้
ดูข้อมูลเพิ่มเติมในเอกสารประกอบ
- ภาพรวมข้อมูลเชิงลึกของสถานที่
- ฟังก์ชันข้อมูลเชิงลึกของสถานที่
- ข้อมูลวิเคราะห์เชิงพื้นที่ของ BigQuery
- Places API
ผู้ร่วมให้ข้อมูล
Henrik Valve | DevX Engineer