
このドキュメントでは、Places Insights のサンプル Place IDs データと、ターゲット設定された Place Details のルックアップを Place Count Functions とともに使用して、結果の信頼性を高める方法について説明します。
このパターンの詳細なリファレンス実装については、次の説明用ノートブックをご覧ください。
 GitHub 上のソースを見る
GitHub 上のソースを見る

アーキテクチャ パターン
このアーキテクチャ パターンは、高度な統計分析とグラウンド トゥルースの検証のギャップを埋めるための再現可能なワークフローを提供します。BigQuery のスケールと Places API の精度を組み合わせることで、分析結果を確実に検証できます。これは、データの信頼性が最も重要なサイト選定、競合他社の分析、市場調査で特に役立ちます。
このパターンのコアには、次の 4 つの主要なステップが含まれます。
- 大規模な分析を実行する: BigQuery の Places Insights の場所数関数を使用して、都市や地域全体など、広範囲の地理情報にわたる場所データを分析します。
- サンプルを分離して抽出する: 集計結果から関心のある領域(高密度の「ホットスポット」など)を特定し、関数によって提供される
sample_place_idsを抽出します。 - グラウンド トゥルースの詳細を取得する: 抽出したプレイス ID を使用して、Place Details API にターゲットを絞った呼び出しを行い、各場所の豊富な現実世界の詳細を取得します。
- 複合ビジュアリゼーションを作成する: 最初の概要レベルの統計マップの上に詳細なプレイスデータを重ねて、集計されたカウントが実際の状況を反映していることを視覚的に検証します。
ソリューションのワークフロー
このワークフローを使用すると、マクロレベルの傾向とミクロレベルの事実の間のギャップを埋めることができます。まず、広範な統計ビューから始め、具体的な実際の例に戦略的にドリルダウンしてデータを検証します。
Places Insights を使用して場所の密度を大規模に分析する
まず、状況を大まかに把握します。数千もの個々のスポット(POI)を取得する代わりに、1 回のクエリを実行して統計概要を取得できます。
この場合は、Places Insights の PLACES_COUNT_PER_H3 関数が最適です。POI の数を六角形グリッド システム(H3)に集計することで、特定の条件(高評価の営業中のレストランなど)に基づいて、密度が高いエリアと低いエリアをすばやく特定できます。
クエリの例を次に示します。検索エリアの地理情報を指定する必要があります。Overture Maps Data BigQuery 一般公開データセットなどのオープン データセットを使用して、地理的境界データを取得できます。
頻繁に使用されるオープン データセットの境界については、独自のプロジェクトのテーブルに具体化することをおすすめします。これにより、BigQuery の費用が大幅に削減され、クエリのパフォーマンスが向上します。
-- This query counts all highly-rated, operational restaurants
-- across a large geography, grouping them into H3 cells.
SELECT *
FROM
`places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'types', ['restaurant'],
'business_status', ['OPERATIONAL'],
'min_rating', 3.5
)
);
このクエリの出力は、H3 セルのテーブルと各セル内の場所の数を示します。これは、密度ヒートマップの基礎となります。
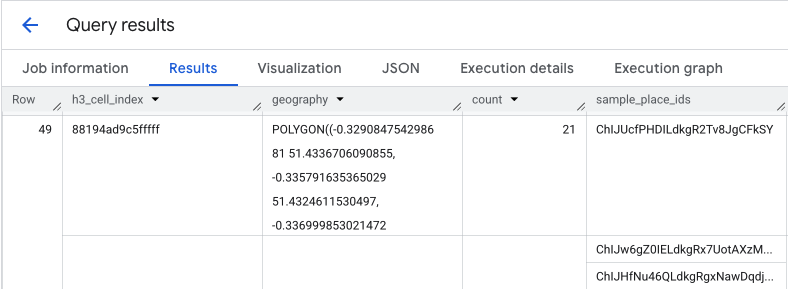
ホットスポットを分離してサンプル プレイス ID を抽出する
PLACES_COUNT_PER_H3 関数の結果も sample_place_ids の配列を返します。レスポンスの要素ごとに最大 250 個のプレイス ID が返されます。これらの ID は、集計された統計情報から、その統計情報に貢献した個々の場所へのリンクです。
システムは、まず最初のクエリから最も関連性の高いセルを特定します。たとえば、カウントが最も多い上位 20 個のセルを選択できます。次に、これらのホットスポットから sample_place_ids を 1 つのリストに統合します。このリストは、最も関連性の高いエリアから最も興味深いスポットを厳選したサンプルであり、ターゲットを絞った確認の準備に役立ちます。
pandas DataFrame を使用して Python で BigQuery の結果を処理している場合、これらの ID を抽出するロジックは簡単です。
# Assume 'results_df' is a pandas DataFrame from your BigQuery query.
# 1. Identify the 20 busiest H3 cells by sorting and taking the top results.
top_hotspots_df = results_df.sort_values(by='count', ascending=False).head(20)
# 2. Extract and flatten the lists of sample_place_ids from these hotspots.
# The .explode() function creates a new row for each ID in the lists.
all_sample_ids = top_hotspots_df['sample_place_ids'].explode()
# 3. Create a final list of unique Place IDs to verify.
place_ids_to_verify = all_sample_ids.unique().tolist()
print(f"Consolidated {len(place_ids_to_verify)} unique Place IDs for spot-checking.")
他のプログラミング言語を使用する場合も、同様のロジックを適用できます。
Places API でグラウンド トゥルースの詳細を取得する
プレイス ID の統合リストが作成されたら、大規模な分析から特定のデータ取得に移行します。これらの ID を使用して、各サンプル ロケーションの詳細情報を Place Details API にクエリします。
これは重要な検証ステップです。Places Insights では、あるエリアに何軒のレストランがあるかを知ることができますが、Places API では、どのレストランがあるかを知ることができます。レストランの名前、正確な住所、緯度/経度、ユーザーの評価、さらには Google マップ上の場所への直接リンクも提供されます。これにより、サンプルデータが拡充され、抽象的な ID が具体的な検証可能な場所に変換されます。
Place Details API から利用できるデータの完全なリストと、取得に関連する費用については、API ドキュメントをご覧ください。
Python クライアント ライブラリを使用して特定の ID の Places API にリクエストを送信すると、次のようになります。詳しくは、Places API(新版)のクライアント ライブラリの例をご覧ください。
# A request to fetch details for a single Place ID.
request = {"name": f"places/{place_id}"}
# Define the fields you want returned in the response as a comma-separated string.
fields_to_request = "formattedAddress,location,displayName,googleMapsUri"
# The response contains ground truth data.
response = places_client.get_place(
request=request,
metadata=[("x-goog-fieldmask", fields_to_request)]
)
このリクエストのフィールドは、2 つの異なる課金 SKU からデータを取得します。
formattedAddressとlocationは、Place Details Essentials SKU の一部です。displayNameとgoogleMapsUriは、Place Details Pro SKU の一部です。
1 件の Place Details リクエストに複数の SKU のフィールドが含まれている場合、リクエスト全体が最上位の SKU のレートで課金されます。そのため、この特定の呼び出しは Place Details Pro リクエストとして課金されます。
費用を制御するには、常に FieldMask を使用して、アプリケーションに必要なフィールドのみをリクエストします。
検証用の複合可視化を作成する
最後のステップは、両方のデータセットを 1 つのビューにまとめることです。これにより、初期分析を直感的かつ迅速に確認できます。ビジュアリゼーションには次の 2 つのレイヤが必要です。
- ベースレイヤ: 最初の
PLACES_COUNT_PER_H3の結果から生成された等値地図またはヒートマップ。地理全体にわたる場所の全体的な密度を示します。 - 最上位レイヤ: 各サンプル スポットの個々のマーカーのセット。前の手順で Places API から取得した正確な座標を使用してプロットされます。
この結合ビューを構築するロジックは、次の疑似コードの例で表されます。
# Assume 'h3_density_data' is your aggregated data from Step 1.
# Assume 'detailed_places_data' is your list of place objects from Step 3.
# Create the base choropleth map from the H3 density data.
# The 'count' column determines the color of each hexagon.
combined_map = create_choropleth_map(
data=h3_density_data,
color_by_column='count'
)
# Iterate through the detailed place data to add individual markers.
for place in detailed_places_data:
# Construct the popup information with key details and a link.
popup_html = f"""
<b>{place.name}</b><br>
Address: {place.address}<br>
<a href="{place.google_maps_uri}" target="_blank">View on Maps</a>
"""
# Add a marker for the current place to the base map.
combined_map.add_marker(
location=[place.latitude, place.longitude],
popup=popup_html,
tooltip=place.name
)
# Display the final map with both layers.
display(combined_map)
特定のグラウンド トゥルース マーカーを高レベルの密度マップに重ね合わせることで、ホットスポットとして特定されたエリアに、分析対象の場所が実際に高密度で含まれていることをすぐに確認できます。この視覚的な確認により、データドリブンな結論に対する信頼性が大幅に高まります。
まとめ
このアーキテクチャ パターンは、大規模な地理空間インサイトを検証するための堅牢で効率的な方法を提供します。Places Insights を活用して広範でスケーラブルな分析を行い、Place Details API を活用してターゲットを絞ったグラウンド トゥルースの検証を行うことで、強力なフィードバック ループを作成できます。これにより、小売店の立地選定やロジスティクス計画などの戦略的決定が、統計的に有意であるだけでなく、検証可能な正確なデータに基づいて行われるようになります。
次のステップ
- 他のプレイス カウント関数を調べて、それらがさまざまな分析の質問にどのように回答できるかを確認します。
- Places API のドキュメントを確認して、分析をさらに充実させるためにリクエストできる他のフィールドを見つけてください。
寄稿者
DevX エンジニア | Henrik Valve