AlphaEarth Foundations de Google es un modelo de incorporación geoespacial entrenado con una variedad de conjuntos de datos de observación de la Tierra (EO). El modelo se ejecutó en series temporales anuales de imágenes, y las incorporaciones resultantes están disponibles como un conjunto de datos listos para el análisis en Earth Engine. Este conjunto de datos permite a los usuarios crear cualquier cantidad de aplicaciones de ajuste o realizar otras tareas sin ejecutar modelos de aprendizaje profundo que requieren muchos recursos de procesamiento. El resultado es un conjunto de datos de uso general que se puede utilizar para una serie de diferentes tareas posteriores, como las siguientes:
- Clasificación
- Regresión
- Detección de cambios
- Búsqueda de similitud
En este instructivo, comprenderemos cómo funcionan los embeddings y aprenderemos a acceder al conjunto de datos de Satellite Embedding y a visualizarlo.
Información sobre las incorporaciones
Los embeddings son una forma de comprimir grandes cantidades de información en un conjunto más pequeño de atributos que representan una semántica significativa. El modelo AlphaEarth Foundations toma series temporales de imágenes de sensores, incluidos Sentinel-2, Sentinel-1 y Landsat, y aprende a representar de forma única la información mutua entre fuentes y objetivos con solo 64 números (obtén más información en el documento aquí). El flujo de datos de entrada contiene miles de bandas de imágenes de varios sensores, y el modelo toma esta entrada de alta dimensión y la convierte en una representación de menor dimensión.
Un buen modelo mental para comprender cómo funciona AlphaEarth Foundations es una técnica llamada análisis de componentes principales (PCA). El PCA también ayuda a reducir la dimensionalidad de los datos para las aplicaciones de aprendizaje automático. Si bien el PCA es una técnica estadística y puede comprimir decenas de bandas de entrada en unos pocos componentes principales, AlphaEarth Foundations es un modelo de aprendizaje profundo que puede tomar miles de dimensiones de entrada de conjuntos de datos de series temporales de varios sensores y aprende a crear una representación de 64 bandas que captura de forma única la variabilidad espacial y temporal de ese píxel.
Un campo de incorporación es el array continuo o “campo” de las incorporaciones aprendidas. Las imágenes de las colecciones de campos de embedding representan trayectorias espacio-temporales que abarcan un año completo y tienen 64 bandas (una para cada dimensión de embedding).
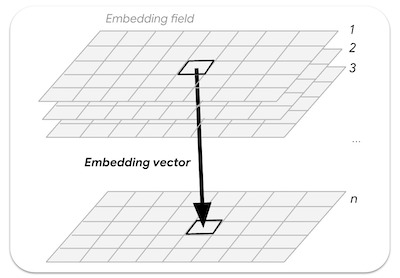
Figura: Vector de embedding de n dimensiones muestreado a partir de un campo de embedding
Accede al conjunto de datos de Satellite Embedding
El conjunto de datos de Satellite Embedding es una colección de imágenes que contiene imágenes anuales desde el año 2017 en adelante (p.ej., 2017, 2018, 2019…). Cada imagen tiene 64 bandas en las que cada píxel es el vector de incorporación que representa la serie temporal de varios sensores para el año determinado.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
Selecciona una región
Comencemos por definir una región de interés. En este instructivo, elegiremos una región alrededor del embalse Krishna Raja Sagara (KRS) en la India y definiremos un polígono como la variable de geometría. Como alternativa, puedes usar las herramientas de dibujo en el editor de código para dibujar un polígono alrededor de la región de interés que se guardará como la variable geometry en las importaciones.
// Use the satellite basemap
Map.setOptions('SATELLITE');
var geometry = ee.Geometry.Polygon([[
[76.3978, 12.5521],
[76.3978, 12.3550],
[76.6519, 12.3550],
[76.6519, 12.5521]
]]);
Map.centerObject(geometry, 12);
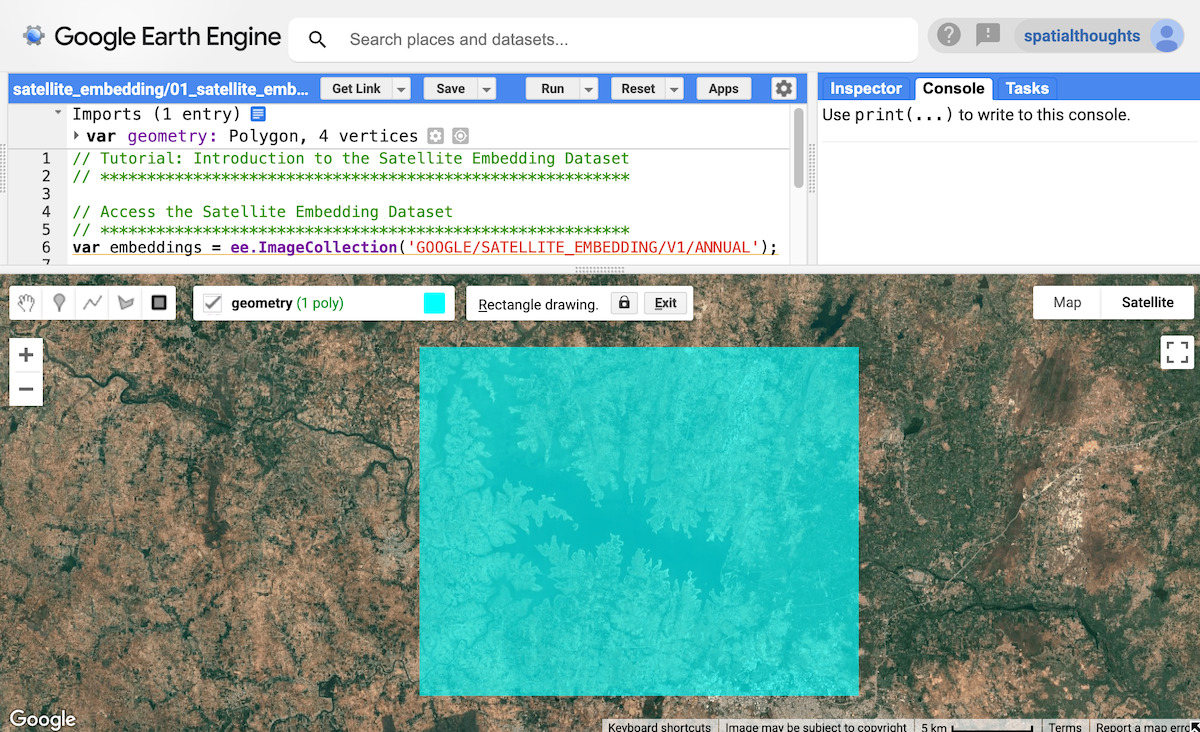
Figura: Selección de la región de interés
Prepara el conjunto de datos de Satellite Embedding
Las imágenes de cada año se dividen en mosaicos para facilitar el acceso. Aplicamos filtros y encontramos las imágenes para el año y la región que elegimos.
var year = 2024;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredEmbeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
Las imágenes de Satellite Embedding se dividen en cuadrículas de hasta 163,840 m x 163,840 m cada una y se publican en la proyección de las zonas UTM de la cuadrícula. Como resultado, obtenemos varias tarjetas de Satellite Embedding que cubren la región de interés. Podemos usar la función mosaic() para combinar varias tarjetas en una sola imagen. Imprimamos la imagen resultante para ver las bandas.
var embeddingsImage = filteredEmbeddings.mosaic();
print('Satellite Embedding Image', embeddingsImage);
Verás que la imagen tiene 64 bandas, llamadas A00, A01, … , A63. Cada banda contiene el valor del vector de incorporación para el año determinado en esa dimensión o eje. A diferencia de los índices o las bandas espectrales, las bandas individuales no tienen un significado independiente, sino que cada banda representa un eje del espacio de incorporación. Usarías todas las 64 bandas como entradas para tus aplicaciones posteriores.

Figura: 64 bandas de la imagen de la incorporación satelital
Visualiza el conjunto de datos de Satellite Embedding
Como acabamos de ver, nuestra imagen contiene 64 bandas. No hay una manera fácil de visualizar toda la información contenida en todas las bandas, ya que solo podemos ver una combinación de tres bandas a la vez.
Podemos elegir tres bandas cualesquiera para visualizar tres ejes del espacio de incorporación como una imagen RGB.
var visParams = {min: -0.3, max: 0.3, bands: ['A01', 'A16', 'A09']};
Map.addLayer(embeddingsImage.clip(geometry), visParams, 'Embeddings Image');

Figura: Visualización RGB de 3 ejes del espacio de embedding
Otra forma de visualizar esta información es usarla para agrupar píxeles con incorporaciones similares y usar estos agrupamientos para comprender cómo el modelo aprendió la variabilidad espacial y temporal de un paisaje.
Podemos usar técnicas de agrupamiento no supervisado para agrupar los píxeles en un espacio de 64 dimensiones en grupos o "clústeres" de valores similares. Para ello, primero tomamos muestras de algunos valores de píxeles y entrenamos un ee.Clusterer.
var nSamples = 1000;
var training = embeddingsImage.sample({
region: geometry,
scale: 10,
numPixels: nSamples,
seed: 100
});
print(training.first());
Si imprimes los valores de la primera muestra, verás que tiene 64 valores de bandas que definen el vector de embedding para ese píxel. El vector de embedding está diseñado para tener una longitud unitaria (es decir, la longitud del vector desde el origen (0,0,…,0) hasta los valores del vector será 1).

Figura: Vector de embedding extraído
Ahora podemos entrenar un modelo no supervisado para agrupar las muestras en la cantidad deseada de clústeres. Cada clúster representaría píxeles de incorporaciones similares.
// Function to train a model for desired number of clusters
var getClusters = function(nClusters) {
var clusterer = ee.Clusterer.wekaKMeans({nClusters: nClusters})
.train(training);
// Cluster the image
var clustered = embeddingsImage.cluster(clusterer);
return clustered;
};
Ahora podemos agrupar la imagen de embedding más grande para ver grupos de píxeles que tienen embeddings similares. Antes de hacerlo, es importante comprender que el modelo capturó la trayectoria temporal completa de cada píxel durante el año, lo que significa que, si dos píxeles tienen valores espectrales similares en todas las imágenes, pero en diferentes momentos, se pueden separar.
A continuación, se muestra una visualización de nuestra área de interés, tal como se capturó en las imágenes de Sentinel-2 con máscara de nubes para el año 2024. Recuerda que todas las imágenes (junto con las de Sentinel-2, Landsat 8/9 y muchos otros sensores) se usaron para aprender las incorporaciones finales.

Figura: Serie temporal anual de Sentinel-2 para nuestra región
Visualicemos las imágenes de incorporación de satélite segmentando el paisaje en 3 clústeres.
var cluster3 = getClusters(3);
Map.addLayer(cluster3.randomVisualizer().clip(geometry), {}, '3 clusters');

Figura: Imagen de incorporación satelital con 3 clústeres
Notarás que los clústeres resultantes tienen límites muy claros. Esto se debe a que los embeddings incluyen inherentemente el contexto espacial: se esperaría que los píxeles dentro del mismo objeto tengan vectores de embedding relativamente similares. Además, uno de los clústeres incluye áreas con agua estacional alrededor del embalse principal. Esto se debe al contexto temporal que se captura en el vector de incorporación, lo que nos permite detectar píxeles con patrones temporales similares.
Veamos si podemos refinar aún más los clústeres agrupando los píxeles en 5 clústeres.
var cluster5 = getClusters(5);
Map.addLayer(cluster5.randomVisualizer().clip(geometry), {}, '5 clusters');

Figura: Imagen de incorporación satelital con 5 clústeres
Podemos seguir y refinar las imágenes en grupos más especializados aumentando la cantidad de clústeres. Así se ve la imagen con 10 clústeres.
var cluster10 = getClusters(10);
Map.addLayer(cluster10.randomVisualizer().clip(geometry), {}, '10 clusters');

Figura: Imagen de incorporación satelital con 10 clústeres
Están surgiendo muchos detalles, y podemos ver diferentes tipos de cultivos agrupados en diferentes clústeres. Dado que el embedding satelital captura la fenología del cultivo junto con las variables climáticas, es adecuado para la asignación de tipos de cultivos. En el próximo instructivo (Clasificación no supervisada), veremos cómo crear un mapa de tipos de cultivos con datos de Satellite Embedding con pocas o ninguna etiqueta a nivel del campo.
Prueba la secuencia de comandos completa de este instructivo en el editor de código de Earth Engine.