Google の AlphaEarth Foundations は、さまざまな地球観測(EO)データセットでトレーニングされた地理空間エンベディング モデルです。このモデルは、画像の年次時系列で実行されており、結果のエンベディングは Earth Engine で分析可能なデータセットとして利用できます。このデータセットを使用すると、計算コストの高いディープ ラーニング モデルを実行することなく、任意の数のファインチューニング アプリケーションやその他のタスクを構築できます。その結果、次のようなさまざまなダウンストリーム タスクに使用できる汎用データセットが作成されます。
- 分類
- 回帰
- 変更の検出
- 類似検索
このチュートリアルでは、エンベディングの仕組みを理解し、衛星エンベディング データセットにアクセスして可視化する方法を学びます。
エンベディングについて
エンベディングは、大量の情報を意味のあるセマンティクスを表す小さな特徴セットに圧縮する方法です。AlphaEarth Foundations モデルは、Sentinel-2、Sentinel-1、Landsat などのセンサーからの画像の時系列を取得し、ソースとターゲット間の相互情報を 64 個の数値で一意に表現する方法を学習します(詳細については、こちらの論文をご覧ください)。入力データ ストリームには、複数のセンサーからの数千の画像バンドが含まれています。モデルは、この高次元の入力を受け取り、低次元の表現に変換します。
AlphaEarth Foundations の仕組みを理解するうえで役立つメンタルモデルは、主成分分析(PCA)という手法です。PCA は、機械学習アプリケーションのデータの次元削減にも役立ちます。PCA は統計手法であり、数十の入力バンドを少数の主成分に圧縮できますが、AlphaEarth Foundations は、マルチセンサー時系列データセットの数千の入力ディメンションを取得し、そのピクセルの空間的および時間的変動を一意にキャプチャする 64 バンド表現を作成することを学習するディープ ラーニング モデルです。
エンベディング フィールドは、学習済みエンベディングの連続した配列または「フィールド」です。エンベディング フィールド コレクションの画像は、1 年間をカバーする時空間軌跡を表し、64 個のバンド(エンベディング ディメンションごとに 1 つ)があります。
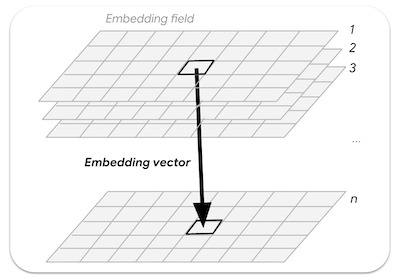
図: エンベディング フィールドからサンプリングされた n 次元エンベディング ベクトル
Satellite Embedding データセットにアクセスする
Satellite Embedding データセットは、2017 年以降の年次画像を含む画像コレクションです(例: 2017、2018、2019 など)。各画像には 64 個のバンドがあり、各ピクセルは特定の年のマルチセンサー時系列を表すエンベディング ベクトルです。
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
リージョンを選択
まず、関心領域を定義します。このチュートリアルでは、インドのクリシュナ ラジャ サガラ(KRS)貯水池周辺のリージョンを選択し、ポリゴンをジオメトリ変数として定義します。または、コードエディタの描画ツールを使用して、対象領域の周りにポリゴンを描画することもできます。このポリゴンは、インポートの geometry 変数として保存されます。
// Use the satellite basemap
Map.setOptions('SATELLITE');
var geometry = ee.Geometry.Polygon([[
[76.3978, 12.5521],
[76.3978, 12.3550],
[76.6519, 12.3550],
[76.6519, 12.5521]
]]);
Map.centerObject(geometry, 12);
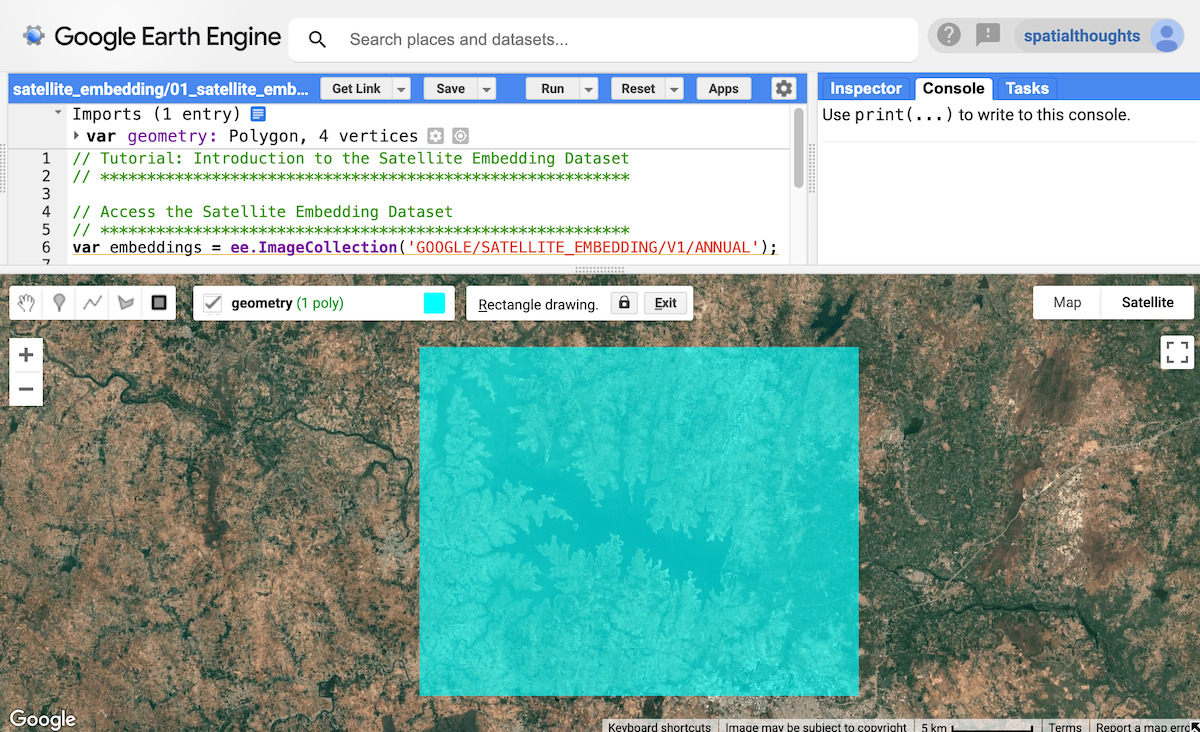
図: 関心領域の選択
衛星エンベディング データセットを準備する
各年の画像は、簡単にアクセスできるようにタイルに分割されています。フィルタを適用して、選択した年と地域の画像を見つけます。
var year = 2024;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredEmbeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
衛星埋め込み画像は、それぞれ最大 163,840 m × 163,840 m のタイルに分割され、タイルの UTM ゾーンの投影で提供されます。その結果、対象地域をカバーする複数の衛星エンベディング タイルが取得されます。mosaic() 関数を使用して、複数のタイルを 1 つの画像に結合できます。結果の画像を印刷して、バンドを確認してみましょう。
var embeddingsImage = filteredEmbeddings.mosaic();
print('Satellite Embedding Image', embeddingsImage);
画像には A00、A01、…、A63 という名前の 64 個のバンドがあります。各帯域には、そのディメンションまたは軸の特定の年のエンベディング ベクトルの値が含まれます。スペクトル バンドや指標とは異なり、個々のバンドには独立した意味はありません。各バンドはエンベディング空間の 1 つの軸を表します。64 個のバンドすべてをダウンストリーム アプリケーションの入力として使用します。

図: 衛星エンベディング画像の 64 バンド
Satellite Embedding データセットを可視化する
先ほど見たように、この画像には 64 個のバンドが含まれています。一度に 3 つのバンドの組み合わせしか表示できないため、すべてのバンドに含まれるすべての情報を簡単に可視化する方法はありません。
任意の 3 つの帯域を選択して、埋め込み空間の 3 つの軸を RGB 画像として可視化できます。
var visParams = {min: -0.3, max: 0.3, bands: ['A01', 'A16', 'A09']};
Map.addLayer(embeddingsImage.clip(geometry), visParams, 'Embeddings Image');

図: 埋め込み空間の 3 つの軸の RGB 可視化
この情報を可視化する別の方法として、類似したエンベディングを持つピクセルをグループ化し、これらのグループ化を使用して、モデルが景観の空間的および時間的変動をどのように学習したかを理解する方法があります。
教師なしクラスタリング手法を使用して、64 次元空間のピクセルを類似した値のグループ(クラスタ)にグループ化できます。このため、まずいくつかのピクセル値をサンプリングして ee.Clusterer をトレーニングします。
var nSamples = 1000;
var training = embeddingsImage.sample({
region: geometry,
scale: 10,
numPixels: nSamples,
seed: 100
});
print(training.first());
最初のサンプルの値を出力すると、そのピクセルのエンベディング ベクトルを定義する 64 個のバンド値があることがわかります。エンベディング ベクトルは単位長になるように設計されています(つまり、原点(0,0,....0)からベクトルの値までのベクトルの長さが 1 になります)。

図: 抽出されたエンベディング ベクトル
これで、教師なしモデルをトレーニングして、サンプルを目的の数のクラスタにグループ化できます。各クラスタは、類似したエンベディングのピクセルを表します。
// Function to train a model for desired number of clusters
var getClusters = function(nClusters) {
var clusterer = ee.Clusterer.wekaKMeans({nClusters: nClusters})
.train(training);
// Cluster the image
var clustered = embeddingsImage.cluster(clusterer);
return clustered;
};
これで、大きなエンベディング画像をクラスタリングして、類似したエンベディングを持つピクセルのグループを確認できます。その前に、モデルが 1 年間の各ピクセルの完全な時間軌跡をキャプチャしていることを理解しておくことが重要です。つまり、2 つのピクセルがすべての画像でスペクトル値が類似しているが、時間が異なる場合、それらを分離できます。
以下は、2024 年の雲マスク処理済みの Sentinel-2 画像でキャプチャされた対象地域の可視化です。すべての画像(Sentinel-2、Landsat 8/9、その他多くのセンサーからの画像を含む)が最終的なエンベディングの学習に使用されていることに注意してください。

図: 地域における Sentinel-2 の年次時系列
風景を 3 つのクラスタに分割して、衛星エンベディング画像を可視化してみましょう。
var cluster3 = getClusters(3);
Map.addLayer(cluster3.randomVisualizer().clip(geometry), {}, '3 clusters');

図: 3 つのクラスタを含む衛星エンベディング画像
結果として得られるクラスタの境界線が非常に明確になっていることがわかります。これは、エンベディングに空間コンテキストが本質的に含まれているためです。同じオブジェクト内のピクセルには、比較的類似したエンベディング ベクトルが想定されます。また、1 つのクラスタには、メインの貯水池周辺の季節的な水域が含まれています。これは、エンベディング ベクトルでキャプチャされた時間的コンテキストにより、同様の時間的パターンを持つピクセルを検出できるためです。
ピクセルを 5 つのクラスタにグループ化して、クラスタをさらに絞り込んでみましょう。
var cluster5 = getClusters(5);
Map.addLayer(cluster5.randomVisualizer().clip(geometry), {}, '5 clusters');

図: 5 つのクラスタを含む衛星エンベディング画像
クラスタの数を増やすことで、画像をより専門的なグループに分類できます。10 個のクラスタを使用した画像は次のようになります。
var cluster10 = getClusters(10);
Map.addLayer(cluster10.randomVisualizer().clip(geometry), {}, '10 clusters');

図: 10 個のクラスタを含む衛星エンベディング画像
さまざまな詳細情報が明らかになり、さまざまな種類の作物が異なるクラスタにグループ化されていることがわかります。衛星エンベディングは、気候変数とともに作物のフェノロジーを捉えるため、作物タイプのマッピングに適しています。次のチュートリアル(教師なし分類)では、フィールドレベルのラベルがほとんどない、またはまったくない衛星エンベディング データを使用して、作物タイプの地図を作成する方法について説明します。