Dalam tutorial sebelumnya (Pengantar), kita telah melihat cara Sematan Satelit merekam lintasan tahunan pengamatan satelit dan variabel iklim. Hal ini membuat set data dapat langsung digunakan untuk memetakan tanaman tanpa perlu memodelkan fenologi tanaman. Pemetaan jenis tanaman adalah tugas yang sulit dan biasanya memerlukan pemodelan fenologi tanaman dan pengumpulan sampel lapangan untuk semua tanaman yang ditanam di wilayah tersebut.
Dalam tutorial ini, kita akan menggunakan pendekatan klasifikasi tanpa pengawasan untuk pemetaan tanaman yang memungkinkan kita melakukan tugas kompleks ini tanpa mengandalkan label lapangan. Metode ini memanfaatkan pengetahuan lokal tentang wilayah tersebut bersama dengan statistik gabungan tanaman, yang tersedia dengan mudah untuk banyak wilayah di dunia.
Pilih region
Untuk tutorial ini, kita akan membuat peta jenis pangkas untuk Cerro Gordo County, Iowa. County ini berada di sabuk jagung Amerika Serikat yang memiliki dua tanaman utama: jagung dan kedelai. Pengetahuan lokal ini penting dan akan membantu kami memutuskan parameter utama untuk model kami.
Mari kita mulai dengan mendapatkan batas untuk county yang dipilih.
// Select the region
// Cerro Gordo County, Iowa
var counties = ee.FeatureCollection('TIGER/2018/Counties');
var selected = counties
.filter(ee.Filter.eq('GEOID', '19033'));
var geometry = selected.geometry();
Map.centerObject(geometry, 12);
Map.addLayer(geometry, {color: 'red'}, 'Selected Region', false);

Gambar: Wilayah yang dipilih
Menyiapkan set data Embedding Satelit
Selanjutnya, kita memuat set data Satellite Embedding, memfilter gambar untuk tahun yang dipilih, dan membuat mosaik.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
var year = 2022;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredembeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
var embeddingsImage = filteredembeddings.mosaic();
Membuat masker lahan pertanian
Untuk pemodelan, kita perlu mengecualikan area non-lahan pertanian. Ada banyak set data global dan regional yang dapat digunakan untuk membuat mask pemangkasan. ESA WorldCover atau GFSAD Global Cropland Extent Product adalah pilihan yang baik untuk set data lahan pertanian global. Tambahan terbaru adalah produk ESA WorldCereal Active Cropland yang memiliki pemetaan musiman lahan pertanian aktif. Karena wilayah kita berada di Amerika Serikat, kita dapat menggunakan set data regional yang lebih akurat, yaitu USDA NASS Cropland Data Layers (CDL) untuk mendapatkan masker tanaman.
// Use Cropland Data Layers (CDL) to obtain cultivated cropland
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var croplandMask = cdl.select('cultivated').eq(2).rename('cropmask');
// Visualize the crop mask
var croplandMaskVis = {min: 0, max: 1, palette: ['white', 'green']};
Map.addLayer(croplandMask.clip(geometry), croplandMaskVis, 'Crop Mask');
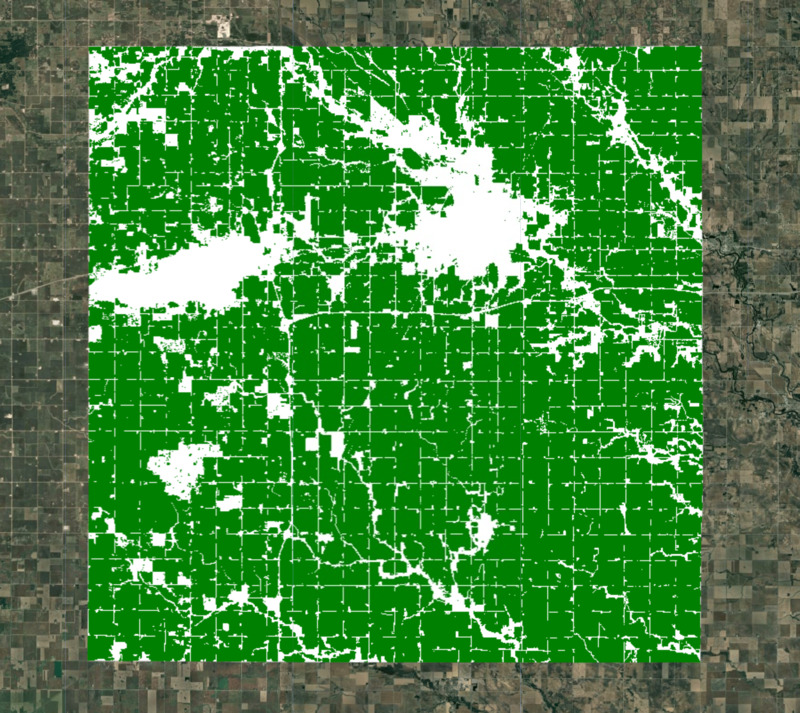
Gambar: Wilayah yang dipilih dengan mask lahan pertanian
Ekstrak sampel pelatihan
Kami menerapkan mask lahan pertanian ke mozaik penyematan. Sekarang kita memiliki semua piksel yang merepresentasikan lahan pertanian yang dikelola di county tersebut.
// Mask all non-cropland pixels
var clusterImage = embeddingsImage.updateMask(croplandMask);
Kita perlu mengambil gambar Sematan Satelit dan mendapatkan sampel acak untuk melatih model pengelompokan. Karena region yang kita minati berisi banyak piksel yang tertutup, pengambilan sampel acak sederhana dapat menghasilkan sampel dengan nilai null. Untuk memastikan kami dapat mengekstrak jumlah sampel non-null yang diinginkan, kami menggunakan pengambilan sampel bertingkat untuk mendapatkan jumlah sampel yang diinginkan di area yang tidak disamarkan.
// Stratified random sampling
var training = clusterImage.addBands(croplandMask).stratifiedSample({
numPoints: 1000,
classBand: 'cropmask',
region: geometry,
scale: 10,
tileScale: 16,
seed: 100,
dropNulls: true,
geometries: true
});
Mengekspor sampel ke aset (opsional)
Mengekstrak sampel adalah operasi yang mahal secara komputasi, dan merupakan praktik yang baik untuk mengekspor sampel pelatihan yang diekstrak sebagai Aset dan menggunakan aset yang diekspor dalam langkah-langkah berikutnya. Hal ini akan membantu mengatasi error waktu tunggu komputasi habis atau error memori pengguna terlampaui saat bekerja dengan wilayah yang besar.
Mulai tugas ekspor dan tunggu hingga selesai sebelum melanjutkan.
// Replace this with your asset folder
// The folder must exist before exporting
var exportFolder = 'projects/spatialthoughts/assets/satellite_embedding/';
var samplesExportFc = 'cluster_training_samples';
var samplesExportFcPath = exportFolder + samplesExportFc;
Export.table.toAsset({
collection: training,
description: 'Cluster_Training_Samples',
assetId: samplesExportFcPath
});
Setelah tugas ekspor selesai, kita dapat membaca kembali sampel yang diekstrak ke dalam kode sebagai kumpulan fitur.
// Use the exported asset
var training = ee.FeatureCollection(samplesExportFcPath);
Memvisualisasikan sampel
Baik Anda menjalankan sampel secara interaktif maupun mengekspornya ke kumpulan fitur, Anda kini akan memiliki variabel pelatihan dengan titik sampel. Mari cetak sampel pertama untuk memeriksa dan menambahkan titik pelatihan ke Map.
print('Extracted sample', training.first());
Map.addLayer(training, {color: 'blue'}, 'Extracted Samples', false);

Gambar: Sampel acak yang diekstrak untuk pengelompokan
Melakukan pengelompokan tanpa pengawasan
Sekarang kita dapat melatih pengelompokan dan mengelompokkan vektor sematan 64D ke dalam sejumlah cluster berbeda yang dipilih. Berdasarkan pengetahuan lokal kami, ada dua jenis tanaman utama yang mewakili sebagian besar area dengan beberapa jenis tanaman lain yang mencakup sebagian kecil sisanya. Kita dapat melakukan pengelompokan tanpa pengawasan pada Sematan Satelit untuk mendapatkan kelompok piksel yang memiliki pola dan lintasan temporal yang serupa. Piksel dengan karakteristik spektral dan spasial yang serupa beserta fenologi yang serupa akan dikelompokkan dalam cluster yang sama.
ee.Clusterer.wekaCascadeKMeans() memungkinkan kita menentukan jumlah minimum dan maksimum cluster serta menemukan jumlah cluster yang optimal berdasarkan data pelatihan. Di sini, pengetahuan lokal kita akan berguna untuk menentukan jumlah minimum dan maksimum klaster. Karena kami memperkirakan ada beberapa jenis klaster yang berbeda - jagung, kedelai, dan beberapa tanaman lainnya - kami dapat menggunakan 4 sebagai jumlah minimum klaster dan 5 sebagai jumlah maksimum klaster. Anda mungkin harus bereksperimen dengan angka-angka ini untuk mengetahui angka yang paling sesuai untuk wilayah Anda.
// Cluster the Satellite Embedding Image
var minClusters = 4;
var maxClusters = 5;
var clusterer = ee.Clusterer.wekaCascadeKMeans({
minClusters: minClusters, maxClusters: maxClusters}).train({
features: training,
inputProperties: clusterImage.bandNames()
});
var clustered = clusterImage.cluster(clusterer);
Map.addLayer(clustered.randomVisualizer().clip(geometry), {}, 'Clusters');
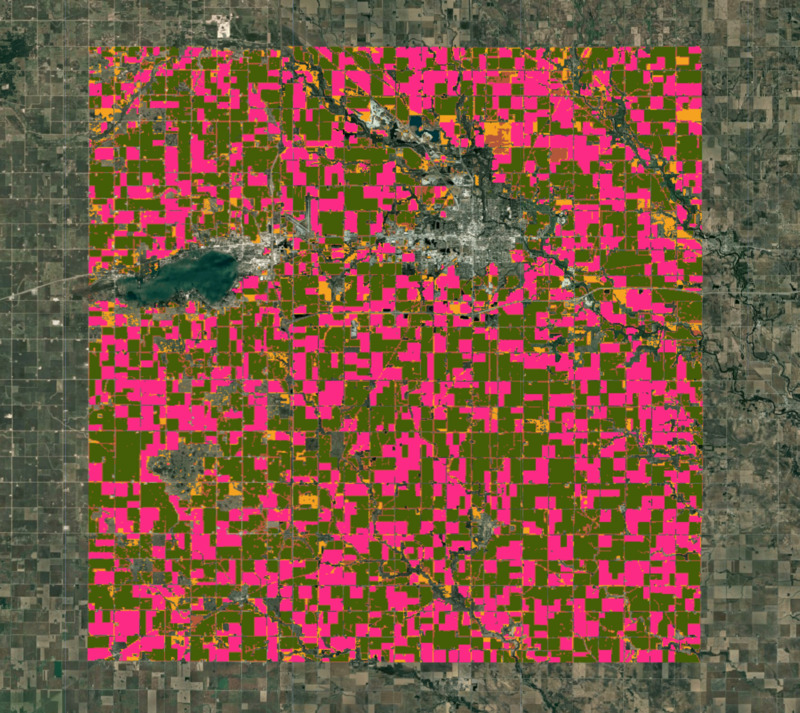
Gambar: Cluster yang diperoleh dari klasifikasi tanpa pengawasan
Menetapkan label ke cluster
Setelah diperiksa secara visual, kelompok yang diperoleh pada langkah sebelumnya sangat cocok dengan batas lahan pertanian yang terlihat dalam gambar beresolusi tinggi. Dari pengetahuan lokal, kita tahu bahwa dua kelompok terbesar adalah jagung dan kedelai. Mari kita hitung area setiap cluster dalam gambar kita.
// Calculate Cluster Areas
// 1 Acre = 4046.86 Sq. Meters
var areaImage = ee.Image.pixelArea().divide(4046.86).addBands(clustered);
var areas = areaImage.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: 'cluster',
}),
geometry: geometry,
scale: 10,
maxPixels: 1e10
});
var clusterAreas = ee.List(areas.get('groups'));
// Process results to extract the areas and create a FeatureCollection
var clusterAreas = clusterAreas.map(function(item) {
var areaDict = ee.Dictionary(item);
var clusterNumber = areaDict.getNumber('cluster').format();
var area = areaDict.getNumber('sum');
return ee.Feature(null, {cluster: clusterNumber, area: area});
});
var clusterAreaFc = ee.FeatureCollection(clusterAreas);
print('Cluster Areas', clusterAreaFc);
Kita memilih 2 cluster dengan area tertinggi.
var selectedFc = clusterAreaFc.sort('area', false).limit(2);
print('Top 2 Clusters by Area', selectedFc);
Namun, kita masih belum mengetahui cluster mana yang merupakan tanaman apa. Jika Anda memiliki beberapa sampel lapangan jagung atau kedelai, Anda dapat menempatkannya di atas cluster untuk mengetahui labelnya masing-masing. Jika tidak ada sampel kolom, kita dapat memanfaatkan statistik panen gabungan. Di banyak negara, statistik gabungan tanaman dikumpulkan dan dipublikasikan secara rutin. Untuk Amerika Serikat, National Agricultural Statistics Service (NASS) memiliki statistik tanaman yang mendetail untuk setiap county dan setiap tanaman utama. Pada tahun 2022, Cerro Gordo County, Iowa memiliki Area Penanaman Jagung seluas 161.500 hektar dan Area Penanaman Kedelai seluas 110.500 hektar.
Dengan menggunakan informasi ini, kita sekarang tahu bahwa di antara 2 cluster teratas, cluster dengan area terbesar kemungkinan besar adalah jagung dan yang lainnya adalah kedelai. Mari tetapkan label ini dan bandingkan area yang dihitung dengan statistik yang dipublikasikan.
var cornFeature = selectedFc.sort('area', false).first();
var soybeanFeature = selectedFc.sort('area').first();
var cornCluster = cornFeature.get('cluster');
var soybeanCluster = soybeanFeature.get('cluster');
print('Corn Area (Detected)', cornFeature.getNumber('area').round());
print('Corn Area (From Crop Statistics)', 163500);
print('Soybean Area (Detected)', soybeanFeature.getNumber('area').round());
print('Soybean Area (From Crop Statistics)', 110500);
Membuat peta pangkas
Sekarang kita mengetahui label untuk setiap cluster dan dapat mengekstrak piksel untuk setiap jenis pangkasan dan menggabungkannya untuk membuat peta pangkasan akhir.
// Select the clusters to create the crop map
var corn = clustered.eq(ee.Number.parse(cornCluster));
var soybean = clustered.eq(ee.Number.parse(soybeanCluster));
var merged = corn.add(soybean.multiply(2));
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(merged.clip(geometry), cropVis, 'Crop Map (Detected)');
Untuk membantu menafsirkan hasil, kita juga dapat menggunakan elemen UI untuk membuat dan menambahkan legenda ke peta.
// Add a Legend
var legend = ui.Panel({
layout: ui.Panel.Layout.Flow('horizontal'),
style: {position: 'bottom-center', padding: '8px 15px'}});
var addItem = function(color, name) {
var colorBox = ui.Label({
style: {color: '#ffffff',
backgroundColor: color,
padding: '10px',
margin: '0 4px 4px 0',
}
});
var description = ui.Label({
value: name,
style: {
margin: '0px 10px 0px 2px',
}
});
return ui.Panel({
widgets: [colorBox, description],
layout: ui.Panel.Layout.Flow('horizontal')
});
};
var title = ui.Label({
value: 'Legend',
style: {
fontWeight: 'bold',
fontSize: '16px',
margin: '0px 10px 0px 4px'
}
});
legend.add(title);
legend.add(addItem('#ffd400', 'Corn'));
legend.add(addItem('#267300', 'Soybean'));
legend.add(addItem('#bdbdbd', 'Other Crops'));
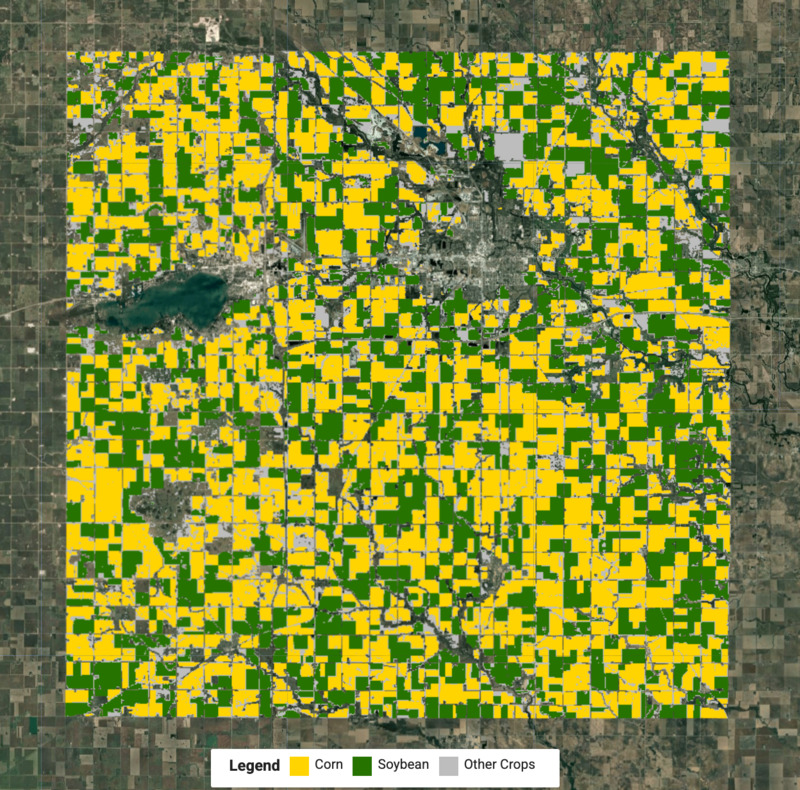
Gambar: Peta tanaman yang terdeteksi dengan tanaman jagung dan kedelai
Memvalidasi hasil
Kami berhasil mendapatkan peta jenis tanaman dengan set data Sematan Satelit tanpa label kolom apa pun hanya menggunakan statistik gabungan dan pengetahuan lokal tentang wilayah tersebut. Mari kita bandingkan hasil kita dengan peta jenis tanaman resmi dari USDA NASS Cropland Data Layers (CDL).
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var cropMap = cropLandcover.updateMask(croplandMask).rename('crops');
// Original data has unique values for each crop ranging from 0 to 254
var cropClasses = ee.List.sequence(0, 254);
// We remap all values as following
// Crop | Source Value | Target Value
// Corn | 1 | 1
// Soybean | 5 | 2
// All other| 0-255 | 0
var targetClasses = ee.List.repeat(0, 255).set(1, 1).set(5, 2);
var cropMapReclass = cropMap.remap(cropClasses, targetClasses).rename('crops');
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(cropMapReclass.clip(geometry), cropVis, 'Crop Landcover (CDL)');

Gambar: (kiri) peta yang dipangkas dari sematan satelit (kanan) peta yang dipangkas dari CDL
Meskipun ada perbedaan antara hasil kami dan peta resmi, Anda akan melihat bahwa kami dapat memperoleh hasil yang cukup baik dengan sedikit upaya. Dengan menerapkan langkah pasca-pemrosesan pada hasilnya, kita dapat menghilangkan beberapa noise dan mengisi kesenjangan dalam output.
Coba skrip lengkap untuk tutorial ini di Editor Kode Earth Engine.