מאחר שהאשכולות לא מפוקחים, אין "אמת" זמינה לאימות התוצאות. היעדר עובדות מקשה על הערכת האיכות. כמו כן, מערכי נתונים מהעולם האמיתי לא שייכים בדרך כלל לאשכולות ברורים של דוגמאות, כמו מערך הנתונים שמוצג באיור 1.
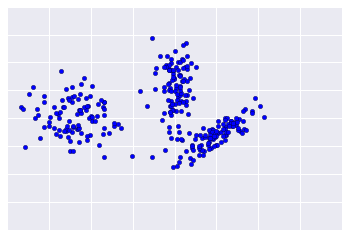
לצערנו, נתונים בעולם האמיתי נראים כמו איור 2, וכתוצאה מכך קשה יותר להעריך באופן ויזואלי את איכות האשכולות.
תרשים הזרימה הבא מסכם את אופן בדיקת האיכות של אשכולות. נרחיב את הסיכום בסעיפים הבאים.

שלב ראשון: איכות הקיבוץ
בדיקת איכות האשכולות אינה תהליך קפדני, משום שהאשכולות "חסרים". הנה כמה הנחיות שתוכלו להחיל באופן חוזר כדי לשפר את איכות האשכולות.
תחילה, בצעו בדיקה חזותית של אשכולות כפי שציפיתם, ושדוגמאות שאתם חושבים שאשכולות דומים מופיעות באותו אשכול. לאחר מכן, נסו לבדוק את המדדים הנפוצים הבאים כפי שמתואר בסעיפים הבאים:
- עוצמה של אשכול
- עוצמה של אשכול
- ביצועי המערכת ב-downstream
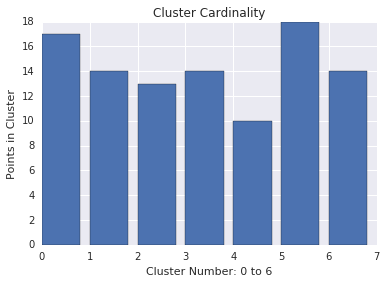
אשכולות (cardinality)
מספר האשכולות הוא מספר הדוגמאות לכל אשכול. תכננו את העוצמה של אשכולות עבור כל האשכולות וחקרו אשכולות בולטים. לדוגמה, באיור 2, חוקרים את אשכול מספר 5.
היקף האשכול
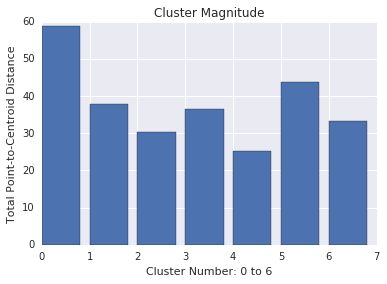
נפח האשכול הוא סכום המרחקים מכל הדוגמאות עד למרכז של האשכול. בדומה לעוצמה, יש לבדוק כיצד העוצמה משתנה בכל האשכולות ולחקור חריגות. לדוגמה, באיור 3, נחקור את אשכול מספר 0.
מגנטיות לעומת עוצמה
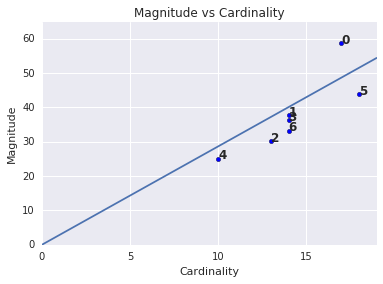
שימו לב שהעוצמה של אשכול נוטה להיות גבוהה יותר לאשכולות, וזה הגיוני. אשכולות הם חריגים כאשר לא ניתן להתאים את העוצמה עם אשכולות אחרים. התמצאות באשכולות אנומליים על ידי הצגת תרשים של העוצמה בעוצמה. לדוגמה, באיור 4, התאמת קו למדדי האשכול מעידה על כך שאשכול מספר 0 הוא חריג.
ביצועי המערכת ב-downstream
בדרך כלל, הפלט של אשכולות במערכות למידת מכונה ב-downstream בודקים אם הביצועים של מערכת ה-downstream משתפרים כשתהליך הקיבוץ משתנה. ההשפעה על הביצועים ב-downstream מספקת בדיקה של איכות המציאות באשכולות. החיסרון הוא שהבדיקה הזו מורכבת.
מה צריך לבדוק אם נמצאו בעיות
אם מצאתם בעיות, בדקו את מדד הכנת הנתונים ומידת הדמיון, ושאלו את עצמכם את השאלות הבאות:
- האם הנתונים שלכם מדורגים?
- האם מידת הדמיון שלך נכונה?
- האם האלגוריתם שלך מבצע פעולות בעלות משמעות סמנטית לגבי הנתונים?
- האם ההנחות שלכם מהאלגוריתם תואמות לנתונים?
שלב שני: ביצועי מדד הדמיון
אלגוריתם הקיבוץ הוא רק טוב כמו מידת הדמיון. ודאו שאמצעי הדמיון מחזיר תוצאות הגיוניות. הבדיקה הפשוטה ביותר היא לזהות זוגות של דוגמאות שידועות כדומות או דומות יותר לזוגות אחרים. לאחר מכן, מחשבים את מידת הדמיון בין כל צמד דוגמאות. מוודאים שמידת הדמיון בין דוגמאות דומות גבוהה יותר ממידת הדמיון בין דוגמאות דומות.
הדוגמאות שבהן תשתמשו כדי לבדוק את מידת הדמיון שלכם צריכות לייצג את קבוצת הנתונים. ודאו שמידת הדמיון שייכת לכל הדוגמאות שלכם. האימות הקפדני מבטיח שמידת הדמיון, בין אם ידנית או בפיקוח, היא עקבית בכל מערך הנתונים. אם מדד הדמיון שלכם לא עקבי בחלק מהדוגמאות, הדוגמאות האלה לא יקובצו בדוגמאות דומות.
אם מצאתם דוגמאות עם דמיון לא מדויק, סביר להניח שמדד הדמיון לא כולל את נתוני התכונות שמבדילים בין הדוגמאות האלה. כדאי לנסות את מדד הדמיון ולקבוע אם יש לכם דמיון מדויק יותר.
שלב שלישי: מספר האשכולות האופטימלי
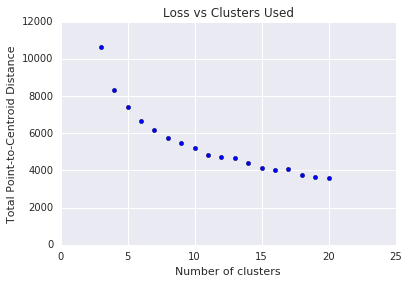
כדי לקבל את הערך k, נדרש מספר האשכולות \(k\) לפני כן. איך נקבע הערך האופטימלי של \(k\)? נסו להפעיל את האלגוריתם להגדלת \(k\) ושימו לב לעוצמה של האשכולות. ככל שהגודל של \(k\)גדל, האשכולות מתקטנים והמרחק הכולל מצטמצם. אפשר להציג את המרחק הזה בהשוואה למספר האשכולות.
כפי שמתואר באיור 4, בירידה \(k\)מסוימת, הירידה במספר הכולל גובלת בעלייה \(k\). מתמטית, זה בערך \(k\) שמדרון המדרון חוצה מעל 1- (\(\theta > 135^{\circ}\)). ההנחיה הזו לא מתארת את הערך המדויק של האופטימיזציה האופטימלית \(k\) , אלא רק ערך משוער. עבור העלילה המוצגת, האופטימיזציה היא \(k\) כ-11. אם אתם מעדיפים אשכולות מפורטים יותר, תוכלו לבחור על חלק \(k\) גבוה יותר כהנחיות.