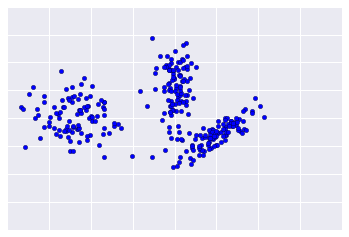
Como o clustering não é supervisionado, nenhuma "verdade" está disponível para verificar os resultados. A ausência de verdade complica a avaliação de qualidade. Além disso, os conjuntos de dados reais não se enquadram em clusters óbvios de exemplos, como o conjunto de dados mostrado na Figura 1.
Infelizmente, os dados reais são mais semelhantes à Figura 2, o que dificulta a avaliação visual da qualidade do clustering.
O fluxograma abaixo resume como verificar a qualidade do clustering. Falaremos mais sobre isso nas próximas seções.

Etapa 1: qualidade do clustering
Verificar a qualidade do clustering não é um processo rigoroso porque o clustering não tem "verdade". Estas são as diretrizes que podem ser aplicadas iterativamente para melhorar a qualidade do clustering.
Primeiro, realize uma verificação visual para confirmar que os clusters têm a aparência esperada e que exemplos que você considera semelhantes aparecem no mesmo cluster. Em seguida, verifique essas métricas usadas com frequência, conforme descrito nas seções a seguir:
- Cardinalidade de cluster
- magnitude do cluster
- Desempenho do sistema downstream
Cardinalidade do cluster
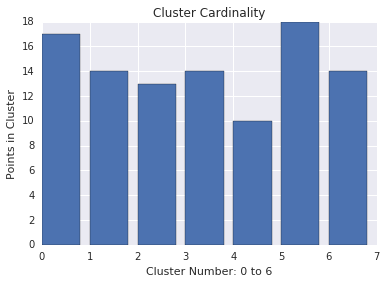
A cardinalidade do cluster é o número de exemplos por cluster. Representar a cardinalidade de cluster de todos os clusters e investigar os clusters que são outliers importantes. Por exemplo, na Figura 2, investigue o cluster número 5.
magnitude do cluster
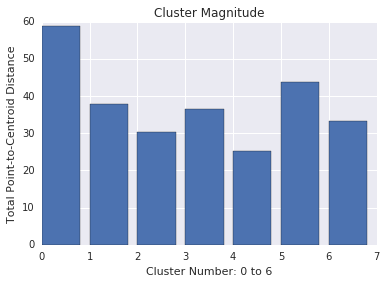
A magnitude do cluster é a soma das distâncias de todos os exemplos até o centroide do cluster. Assim como na cardinalidade, verifique como a magnitude varia nos clusters e investigue anomalias. Por exemplo, na Figura 3, investigue o número de cluster 0.
Magnitude x cardinalidade
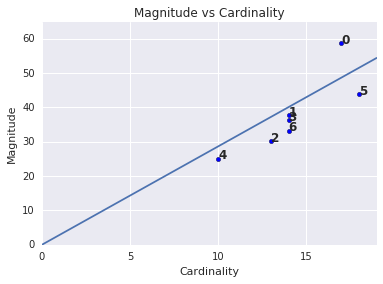
Observe que uma cardinalidade de cluster mais alta tende a resultar em uma magnitude de cluster maior, o que intuitivamente faz sentido. Os clusters são anômalos quando a cardinalidade não está correlacionada com a magnitude em relação aos outros clusters. Para encontrar clusters anômalos, compare a magnitude com a cardinalidade. Por exemplo, na Figura 4, o ajuste de uma linha nas métricas do cluster mostra que o número de cluster 0 é anômalo.
Desempenho do sistema downstream
Como a saída de clustering geralmente é usada em sistemas de ML downstream, verifique se o desempenho do sistema downstream melhora quando o processo de clustering muda. O impacto no desempenho downstream fornece um teste real para a qualidade do clustering. A desvantagem é que essa verificação é complexa.
Perguntas a serem investigadas em caso de problemas
Se você encontrar problemas, verifique a preparação de dados e a medida de semelhança, fazendo as seguintes perguntas:
- Seus dados são escalonados?
- Sua medida de semelhança está correta?
- Seu algoritmo está realizando operações semanticamente significativas nos dados?
- As suposições do algoritmo correspondem aos dados?
Etapa 2: desempenho da medida de semelhança
Seu algoritmo de clustering é tão bom quanto sua medida de semelhança. Verifique se sua medida de semelhança retorna resultados razoáveis. A verificação mais simples é identificar pares de exemplos que são conhecidos por serem mais ou menos semelhantes a outros pares. Em seguida, calcule a medida de semelhança para cada par de exemplos. Verifique se a medida de semelhança para exemplos mais semelhantes é maior do que a medida de semelhança para exemplos menos semelhantes.
Os exemplos usados para verificar a medida de semelhança devem representar o conjunto de dados. Verifique se a medida de semelhança é válida para todos os seus exemplos. Essa verificação garante que sua medida de semelhança, seja manual ou supervisionada, seja consistente em todo o conjunto de dados. Caso a medida de semelhança seja inconsistente para alguns exemplos, eles não serão agrupados com exemplos semelhantes.
Caso você encontre exemplos com semelhanças imprecisas, é provável que a medida de semelhança não capture os dados do atributo que distinguem esses exemplos. Teste sua medida de semelhança e determine se você tem semelhanças mais precisos.
Etapa 3: número ideal de clusters
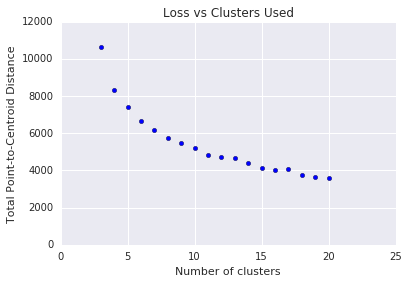
k-means exige que você decida o número de clusters \(k\) antes. Como você determina o valor ideal de \(k\)? Tente executar o algoritmo para aumentar \(k\) e observar a soma das magnitudes do cluster. À medida que \(k\) aumenta, os clusters ficam menores, e a distância total diminui. Considere essa distância em relação ao número de clusters.
Conforme mostrado na figura 4, em um determinado \(k\), a redução de perda se torna margem com o aumento de \(k\). Matematicamente, isso é aproximadamente o \(k\) em que a inclinação cruza acima de -1 (\(\theta > 135^{\circ}\)). Esta diretriz não indica um valor exato para o ideal \(k\) , mas apenas um valor aproximado. Para o gráfico exibido, o ideal \(k\) é aproximadamente 11. Se você preferir clusters mais granulares, escolha um mais alto \(k\) usando este gráfico como orientação.