Fark etme, model oluşturmak anlamına gelir şununla eşleşen (ezberleyen) eğitim seti modelin yeni veriler hakkında doğru tahminlerde bulunamadığını yakından gösterir. Fazla uyum modeli, laboratuvarda iyi performans gösteren icata benzer ancak gerçek dünyada değersizdir.
Şekil 11'de her bir geometrik şeklin bir ağacın konumunu temsil ettiğini düşünün ortaya çıkar. Mavi elmaslar sağlıklı ağaçların yerlerini, turuncu daireler ise hasta ağaçların konumlarını işaret ediyor.

Farklı şekilleri birbirinden ayırmak için zihinsel olarak her türlü şekli (çizgiler, kıvrımlar, ovaller vb.) sağlıklı ağaçlara götürmekti. Ardından, incelemek için sonraki satırı genişletin. fark edebilirsiniz.
Olası bir çözümü görmek için genişletin (Şekil 12).

Şekil 12'de gösterilen karmaşık şekiller, şemanın ikisi hariç olmak üzere tümü bulmaktır. Şekilleri bir model olarak düşünürsek, bu tablo gerçekten modeli.
Yoksa mümkün mü dersiniz? Gerçekten mükemmel bir model, yeni örnekleri başarıyla kategorilere ayırır. Şekil 13'te, aynı model yeni bir model üzerinde tahminde bulunduğunda ne test kümesinden örnekler:

Şekil 12'de gösterilen karmaşık model, başlangıçtaki eğitim veri kümesi ama test setinde oldukça kötü bir iş çıkarmış. Bu, modelin klasik durumu
Fitil, fazla ve az kesim
Bir modelin yeni veriler hakkında iyi tahminlerde bulunması gerekir. Yani, projenizin hedeflerine "uymayan" bir model yeni veriler oluşturabilirsiniz.
Gördüğünüz gibi, fazla giyilen bir modelin eğitim süresince ancak yeni verilere ilişkin kötü tahminler oluşturabilirsiniz. underfit modeli eğitim verileri hakkında iyi tahminlerde bile bulunmayabilir. Fazla uyum modeli laboratuvarda iyi performans gösteren, ancak gerçek dünyada kötü performans gösteren bir ürün gibi "Uygun değil" durumundaki bir model, kontrol edin.

Genelleme çok önemlidir. Yani iyi genelleştiren bir model yeni verilere dair tahminlerde bulunmaktır. Hedefiniz, genelleme yapan bir model oluşturmak iyi bir örnektir.
Fazla uyumu tespit etme
Aşağıdaki eğriler, fazla uyumu tespit etmenize yardımcı olur:
- kayıp eğrileri
- genelleme eğrileri
Kayıp eğrisi, bir modelin kaybının grafiğini çizer ve eğitim iterasyonu sayısına kıyasla. İki veya daha fazla kayıp eğrisini gösteren bir grafiğe genelleme denir emin olun. Aşağıdakiler genelleştirme eğrisi iki kayıp eğrisini gösterir:
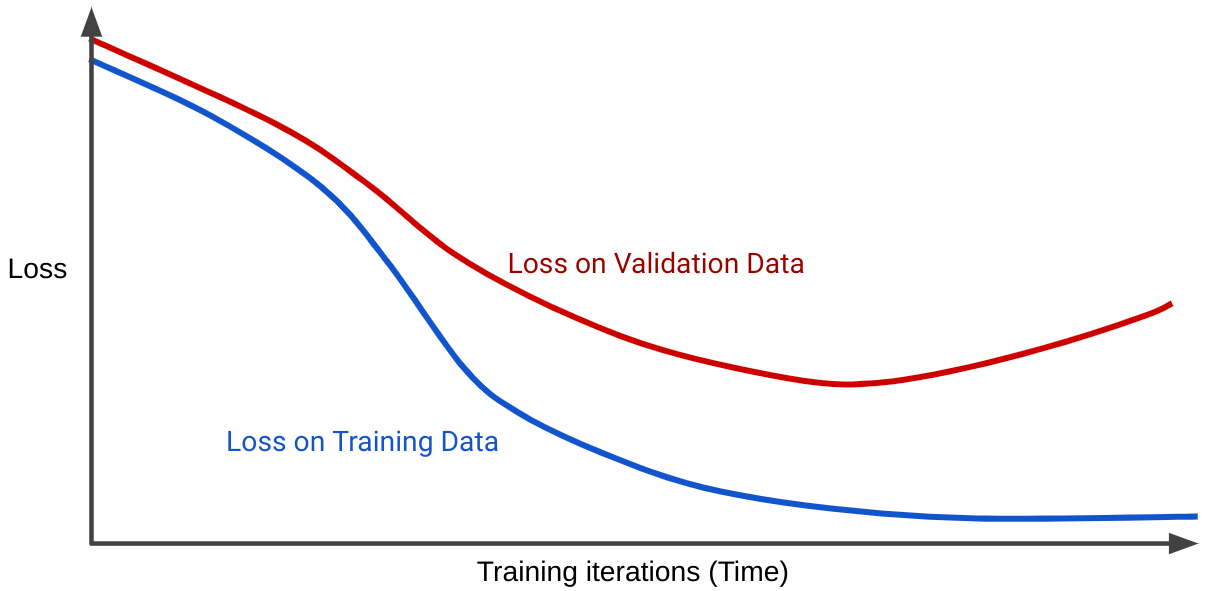
İki kayıp eğrisinin başta benzer bir davranışa sahip olduğunu, daha sonra ise farklılaştığını göreceksiniz. Yani belirli sayıda iterasyondan sonra kayıp düşerken eğitim kümesinde sabit bir şekilde tutar (tümleşme) ancak artış iki seçenekten oluşur. Bu, aşırı uyuma işaret eder.
Buna karşılık, iyi uyan bir modelin genelleştirme eğrisi iki kayıp eğrisini gösterir içeren bir e-posta alırsınız.
Fazla uyuma neden olan nedir?
Çok geniş kapsamlı olarak, fazla uyum aşağıdakilerden biri veya her ikisinden kaynaklanır sorunlar:
- Eğitim veri kümesi, gerçek hayat verilerini (veya doğrulama kümesi veya test kümesi) ekleyebilirsiniz.
- Model çok karmaşık.
Genelleştirme koşulları
Bir model, eğitim seti üzerinde eğitilir ancak modelin gerçek değeri şudur: yeni örneklerle ilgili, özellikle de gerçek dünya verilerine dair tahminlerde bulunur. Model geliştirirken test kümeniz gerçek dünyadan veriler için bir proxy görevi görür. İyi genelleme yapan bir modeli eğitmek, aşağıdaki veri kümesi koşullarını gerektirir:
- Örnekler: bağımsız ve özdeş şekilde dağıtılmış, demenin çok daha güzel bir yolu, birbirlerini etkileyemez.
- Veri kümesi durağan; yani zaman içinde önemli ölçüde değişmez.
- Veri kümesi bölümleri aynı dağılıma sahiptir. Yani eğitim veri kümesindeki örnekler istatistiksel açıdan benzerdir. doğrulama kümesi, test kümesi ve gerçek dünya verilerindeki örneklere bakın.
Aşağıdaki alıştırmalarla önceki koşulları keşfedin.
Alıştırmalar: Öğrendiklerinizi sınayın

Meydan okuma alıştırması
Sürücülerin otomobil satın almak için ideal tarihi tahmin eden bir model belirli bir rota için tren bileti gerekiyor. Örneğin, model size 23 Temmuz'da kalkan bir tren için biletlerini 8 Temmuz'da satın aldığını tespit ettik. Tren şirketi çeşitli kriterlere dayanarak fiyatlarını saatlik olarak güncelliyor Ancak temel olarak mevcut koltuk sayısına göre belirlenir. Yani:
- O kadar çok koltuk varsa bilet fiyatları genellikle düşük olur.
- Boş koltuk sayısı çok azsa bilet fiyatları genellikle yüksektir.
Yanıt: Gerçek dünya modeli, karmaşık bir geri bildirim döngüsü.
Örneğin, modelin kullanıcılara 8 Temmuz'da bilet satın almalarını önerdiğini varsayalım. Modelin önerisini kullanan bazı yolcular biletlerini 8:30'da satın alıyor 8 Temmuz sabahı. Tren şirketi saat 09:00’da fiyatları yükseltiyor çünkü daha az boş koltuk var. Modelin önerisini kullanan yolcular Değiştirilmiş fiyatlar. Akşam saatlerinde bilet fiyatları, ABD doları ile karşılaştırıldığında sabah başladı.