Overfitting significa criar um modelo que corresponda (memorize) o conjunto de treinamento de perto que o modelo não faz previsões corretas com base em novos dados. Um modelo de overfitting é análogo a uma invenção que tem um bom desempenho no laboratório, mas não vale a pena no mundo real.
Na figura 11, imagine que cada forma geométrica representa a posição de uma árvore em uma floresta quadrada. Os diamantes azuis marcam os locais de árvores saudáveis, enquanto os círculos laranja marcam os locais das árvores doentes.

Desenhe mentalmente formas (linhas, curvas, formas ovais...qualquer coisa) para separar árvores saudáveis de árvores doentes. Em seguida, expanda a próxima linha para examinar uma possível separação.
Expanda para ver uma solução possível (Figura 12).

As formas complexas mostradas na figura 12 categorizam, exceto duas, das árvores. Se considerarmos as formas como um modelo, esta será uma experiência fantástica um modelo de machine learning.
Ou será que não? Um modelo realmente excelente categoriza novos exemplos. A figura 13 mostra o que acontece quando o mesmo modelo faz previsões em novos exemplos do conjunto de teste:

Então, o modelo complexo mostrado na Figura 12 fez um ótimo trabalho no conjunto de treinamento mas foi um trabalho péssimo no conjunto de teste. Esse é um caso clássico de modelo overfitting aos dados do conjunto de treinamento.
Ajuste, overfitting e underfitting
Um modelo precisa fazer boas previsões em dados novos. Ou seja, seu objetivo é criar um modelo que se encaixe novos dados.
Como você aprendeu, um modelo de overfitting faz previsões excelentes no treinamento previsões inadequadas, mas com resultados ruins. Um Modelo underfit nem faz boas previsões nos dados de treinamento. Se um modelo de overfitting for como um produto com bom desempenho no laboratório, mas ruim no mundo real, um modelo underfit é como um produto que nem se sai bem no laboratório.

Generalização é a oposto do overfitting. Ou seja, um modelo generaliza bem faz boas previsões com base em novos dados. Seu objetivo é criar um modelo que generalize para os novos dados.
Como detectar overfitting
As curvas a seguir ajudam a detectar o overfitting:
- curvas de perda
- curvas de generalização
Uma curva de perda traça a perda de um modelo em relação ao número de iterações de treinamento. Um gráfico que mostra duas ou mais curvas de perda é chamado de generalização curva. O seguinte de generalização mostra duas curvas de perda:
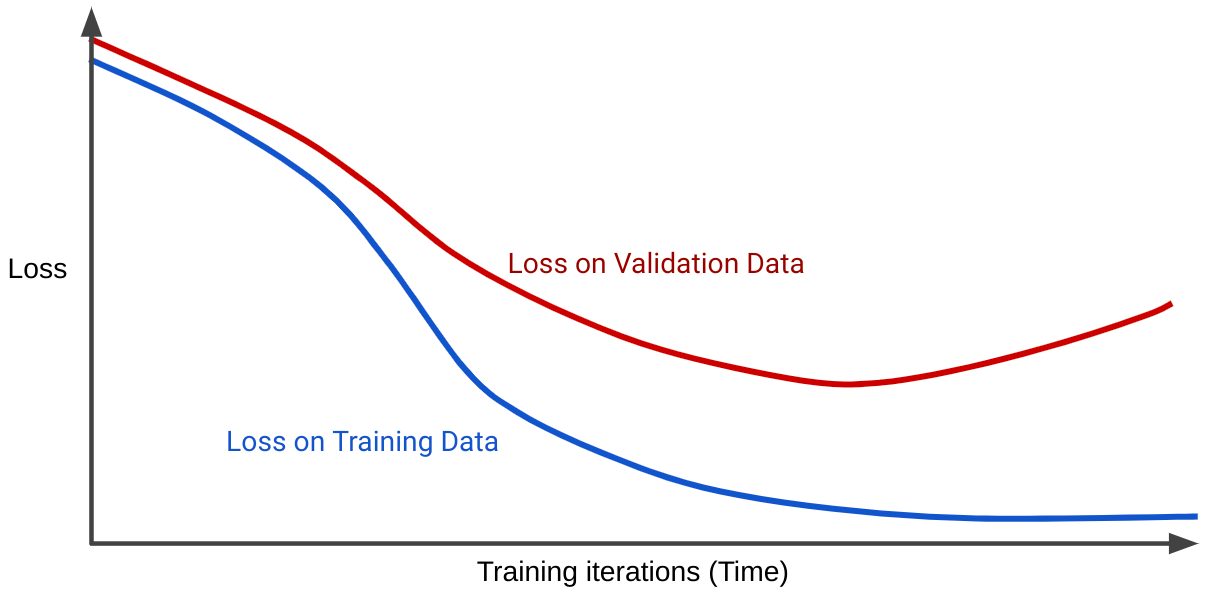
Observe que as duas curvas de perda se comportam de forma semelhante no início e, depois, divergem. Ou seja, após um certo número de iterações, a perda diminui ou permanece estável (convergente) para o conjunto de treinamento, mas aumenta para o conjunto de validação. Isso sugere um overfitting.
Por outro lado, uma curva de generalização para um modelo bem ajustado mostra duas curvas de perda. com formas semelhantes.
O que causa o overfitting?
Em linhas gerais, o overfitting é causado por um dos itens a seguir problemas:
- O conjunto de treinamento não representa adequadamente dados da vida real (ou a conjunto de validação ou de teste).
- O modelo é muito complexo.
Condições de generalização
Um modelo é treinado em um conjunto de treinamento, mas o verdadeiro teste do valor de um modelo é quão faz previsões sobre novos exemplos, especialmente em dados do mundo real. Ao desenvolver um modelo, o conjunto de teste serve como um proxy para dados do mundo real. Treinar um modelo que generaliza bem implica nas seguintes condições do conjunto de dados:
- Os exemplos devem ser distribuídos de forma independente e idêntica, que é uma maneira sofisticada de dizer exemplos não podem influenciar uns aos outros.
- O conjunto de dados é stationary, que significa o não muda significativamente ao longo do tempo.
- As partições do conjunto de dados têm a mesma distribuição. Ou seja, os exemplos no conjunto de treinamento são estatisticamente semelhantes à no conjunto de validação, no conjunto de teste e em dados do mundo real.
Faça os exercícios a seguir para conhecer as condições anteriores.
Exercícios: testar seu conhecimento

Exercício de desafio
Você está criando um modelo que prevê a data ideal para os passageiros comprarem um de trem para um trajeto específico. Por exemplo, o modelo pode recomendar que os usuários comprem a passagem no dia 8 de julho para um trem que parte no dia 23. A empresa de trens atualiza os preços por hora, com base em uma variedade de alguns fatores, mas principalmente no número atual de licenças disponíveis. Ou seja:
- Quando há muitos assentos disponíveis, os preços dos ingressos normalmente são baixos.
- Se houver poucos assentos disponíveis, os preços dos ingressos normalmente são altos.
Resposta:o modelo do mundo real está com dificuldades loop de feedback.
Por exemplo, suponha que o modelo recomende que os usuários comprem ingressos no dia 8 de julho. Alguns passageiros que usam a recomendação do modelo compram as passagens às 8h30. pela manhã do dia 8 de julho. Às 9h, a empresa de trem aumenta os preços porque menos assentos estão disponíveis agora. Os passageiros que usam a recomendação do modelo têm preços alterados. À noite, os preços dos ingressos podem ser muito mais altos do que da manhã.