Wenn Sie direkt auf Places Insights-Daten zugreifen möchten, schreiben Sie SQL-Abfragen in BigQuery, die aggregierte Informationen zu Orten zurückgeben. Die Ergebnisse werden aus dem Dataset für die in der Abfrage angegebenen Suchkriterien zurückgegeben.
Wenn Sie Zahlen unter 5 abrufen möchten, verwenden Sie stattdessen die Places Count Funktionen. Diese Funktionen können beliebige Zahlen zurückgeben, einschließlich 0, erzwingen aber einen Mindestsuchbereich von 40,0 × 40,0 Metern (1.600 m²). Weitere Informationen dazu, wann Sie Abfragen direkt ausführen und wann Sie Funktionen verwenden sollten.
Grundlagen zu Abfragen
Die folgende Abbildung zeigt das grundlegende Format einer Abfrage:

Die einzelnen Teile der Abfrage werden unten genauer beschrieben.
Abfrageanforderungen
In SQL-Abfragen, die direkt für das Dataset ausgeführt werden, muss das Dataset angegeben sein und die Klausel WITH AGGREGATION_THRESHOLD in der SELECT-Klausel enthalten sein. Andernfalls schlägt die Abfrage fehl.
In diesem Beispiel wird places_insights___us.places angegeben, um das Dataset für die USA abzufragen.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`
Projektname angeben (optional)
Sie können optional den Projektnamen in die Abfrage einfügen. Wenn Sie keinen Projektnamen angeben, wird standardmäßig das aktive Projekt verwendet.
Sie sollten den Projektnamen angeben, wenn Sie Datasets mit demselben Namen in verschiedenen Projekten verknüpft haben oder wenn Sie eine Tabelle außerhalb des aktiven Projekts abfragen.
Beispiel: [project name].[dataset name].places.
Aggregationsfunktion angeben
Im folgenden Beispiel werden die unterstützten BigQuery aggregation functions gezeigt. Mit dieser Abfrage werden die Bewertungen aller Orte im Umkreis von 1.000 Metern um das Empire State Building in New York City aggregiert, um Bewertungsstatistiken zu erstellen:
SELECT WITH AGGREGATION_THRESHOLD COUNT(id) AS place_count, APPROX_COUNT_DISTINCT(rating) as distinct_ratings, COUNTIF(rating > 4.0) as good_rating_count, LOGICAL_AND(rating <= 5) as all_ratings_equal_or_below_five, LOGICAL_OR(rating = 5) as any_rating_exactly_five, AVG(rating) as avg_rating, SUM(user_rating_count) as rating_count, COVAR_POP(rating, user_rating_count) as rating_covar_pop, COVAR_SAMP(rating, user_rating_count) as rating_covar_samp, STDDEV_POP(rating) as rating_stddev_pop, STDDEV_SAMP(rating) as rating_stddev_samp, VAR_POP(rating) as rating_var_pop, VAR_SAMP(rating) as rating_var_samp, FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL"
Standortbeschränkung angeben
Wenn Sie keine Standortbeschränkung angeben, wird die Datenaggregation auf das gesamte Dataset angewendet. In der Regel geben Sie eine Standortbeschränkung an, um in einem bestimmten Bereich zu suchen. In dieser Beispielabfrage wird eine Zielbeschränkung angegeben, die auf das Empire State Building in New York City zentriert ist und einen Radius von 1.000 Metern hat.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000)
Sie können ein Polygon verwenden, um den Suchbereich anzugeben. Wenn Sie ein Polygon verwenden, müssen die Punkte des Polygons eine geschlossene Schleife definieren, wobei der erste Punkt im Polygon mit dem letzten Punkt identisch sein muss:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_CONTAINS(ST_GEOGFROMTEXT("""POLYGON((-73.985708 40.75773,-73.993324 40.750298, -73.9857 40.7484,-73.9785 40.7575, -73.985708 40.75773))"""), point)
Im nächsten Beispiel definieren Sie den Suchbereich mit einer Linie aus verbundenen Punkten und legen den Suchradius auf 100 Meter um die Linie fest. Die Linie ähnelt einer Reiseroute, die von der Routes APIberechnet wurde. Die Route kann für ein Fahrzeug, ein Fahrrad oder einen Fußgänger sein:
DECLARE route GEOGRAPHY; SET route = ST_GEOGFROMTEXT("""LINESTRING(-73.98903537033028 40.73655649223003, -73.93580216278471 40.80955538843361)"""); SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(route, point, 100)
Nach Feldern des Orts-Datasets filtern
Verfeinern Sie die Suche anhand der Felder, die durch das dataset
schema definiert sind. Filtern Sie die Ergebnisse nach Datasetfeldern wie regular_opening_hours, price_level und rating.
Verweisen Sie auf alle Felder im Dataset, die durch das Datasetschema für Ihr Land definiert sind. Das Datasetschema für jedes Land besteht aus zwei Teilen:
- Das Kernschema das für die Datasets aller Länder gleich ist.
- Ein länderspezifisches Schema das Schemakomponenten definiert, die für dieses Land spezifisch sind.
Ihre Abfrage kann beispielsweise eine WHERE-Klausel enthalten, die Filterkriterien für die Abfrage definiert.
Im folgenden Beispiel werden Aggregationsdaten für Orte vom Typ tourist_attraction mit dem business_status OPERATIONAL zurückgegeben, die eine rating von mindestens 4,0 haben und bei denen allows_dogs auf true gesetzt ist:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND 'tourist_attraction' IN UNNEST(types) AND business_status = "OPERATIONAL" AND rating >= 4.0 AND allows_dogs = true
Die nächste Abfrage gibt Ergebnisse für Orte mit mindestens acht Ladestationen für Elektrofahrzeuge zurück:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
Nach primärem Ortstyp und Ortstyp filtern
Jeder Ort im Dataset kann Folgendes haben:
Einen einzelnen primären Typ , der ihm aus den von Ortstypen definierten Typen zugeordnet ist. Der primäre Typ kann beispielsweise
mexican_restaurantodersteak_housesein. Verwenden Sieprimary_typein einer Abfrage, um die Ergebnisse nach dem primären Typ eines Orts zu filtern.Mehrere Typwerte , die ihm aus den von Ortstypen definierten Typen zugeordnet sind. Ein Restaurant kann beispielsweise die folgenden Typen haben:
seafood_restaurant,restaurant,food,point_of_interest,establishment. Verwenden Sietypesin einer Abfrage, um die Ergebnisse nach der Liste der Typen zu filtern, die dem Ort zugeordnet sind.
Die folgende Abfrage gibt Ergebnisse für alle Orte mit dem primären Typ skin_care_clinic zurück, die auch als spa fungieren:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE 'spa' IN UNNEST(types) AND 'skin_care_clinic' = primary_type
Nach Orts-ID filtern
Im folgenden Beispiel wird die durchschnittliche Bewertung für fünf Orte berechnet. Die Orte werden durch ihre place_id identifiziert.
DECLARE place_ids ARRAY<STRING>; SET place_ids = ['ChIJPQOh8YVZwokRE2WsbZI4tOk', 'ChIJibtT3ohZwokR7tX0gp0nG8U', 'ChIJdfD8moVZwokRO6vxjXAtoWs', 'ChIJsdNONuFbwokRLM-yuifjb8k', 'ChIJp0gKoClawokR0txqrcaEkFc']; SELECT WITH AGGREGATION_THRESHOLD AVG(rating) as avg_rating, FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(place_ids) place_id WHERE id = place_id;
Bestimmte Orts-IDs herausfiltern
Sie können auch ein Array von Orts IDs aus einer Abfrage ausschließen.
Sie können die gesuchten Orts-IDs mit der Orts-ID Suche oder programmatisch mit der Places API finden, um eine Text Search (New) Anfrage auszuführen.
Im folgenden Beispiel wird mit der Abfrage die Anzahl der Cafés in der Postleitzahl 2000
von Sydney, Australien, ermittelt, die nicht im excluded_cafes Array enthalten sind. Eine solche Abfrage kann für einen Geschäftsinhaber nützlich sein, der seine eigenen Unternehmen aus einer Zählung ausschließen möchte.
WITH excluded_cafes AS ( -- List the specific place IDs to exclude from the final count SELECT * FROM UNNEST([ 'ChIJLTcYGz-uEmsRmazk9oMnP5w', 'ChIJeWDDDNOvEmsRF8SMPUwPbhw', 'ChIJKdaKHbmvEmsRSdxq_1O05bU' ]) AS place_id ) SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `places_insights___au.places` AS places -- Perform a LEFT JOIN to identify which places are in the exclusion list LEFT JOIN excluded_cafes ON places.id = excluded_cafes.place_id WHERE -- Filter for specific place type and postal code places.primary_type = 'cafe' AND '2000' IN UNNEST(places.postal_code_names) -- Keep only the rows where the join failed (meaning the ID was NOT in the list) AND excluded_cafes.place_id IS NULL;
Nach vordefinierten Datenwerten filtern
Viele Datasetfelder haben vordefinierte Werte. Beispiel:
Das Feld
price_levelunterstützt die folgenden vordefinierten Werte:PRICE_LEVEL_FREEPRICE_LEVEL_INEXPENSIVEPRICE_LEVEL_MODERATEPRICE_LEVEL_EXPENSIVEPRICE_LEVEL_VERY_EXPENSIVE
Das Feld
business_statusunterstützt die folgenden vordefinierten Werte:OPERATIONALCLOSED_TEMPORARILYCLOSED_PERMANENTLYFUTURE_OPENING
In diesem Beispiel gibt die Abfrage die Anzahl aller Blumenläden mit dem business_status OPERATIONAL im Umkreis von 1.000 Metern um das Empire State Building in New York City zurück:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL" AND 'florist' IN UNNEST(types)
Nach Öffnungszeiten filtern
In diesem Beispiel wird die Anzahl aller Orte in einem geografischen Gebiet mit Happy Hour am Freitag zurückgegeben:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(regular_opening_hours_happy_hour.friday) AS friday_hours WHERE '17:00:00' BETWEEN friday_hours.start_time AND friday_hours.end_time AND ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000);
Nach Region filtern (Adresskomponenten)
Unser Orts-Dataset enthält auch eine Reihe von Adresskomponenten, die zum Filtern von Ergebnissen nach politischen Grenzen nützlich sind. Jede Adresskomponente wird durch ihren Textcodenamen (10002 für die Postleitzahl in New York City) oder die Orts-ID (ChIJm5NfgIBZwokR6jLqucW0ipg) für die entsprechende Postleitzahl-ID identifiziert.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE '10002' IN UNNEST(postal_code_names) --- 'ChIJm5NfgIBZwokR6jLqucW0ipg' IN UNNEST(postal_code_ids) -- same filter as above using postal code ID
Nach Ladestationen für Elektrofahrzeuge filtern
In diesem Beispiel wird die Anzahl der Orte mit mindestens acht Ladestationen für Elektrofahrzeuge angegeben:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
In diesem Beispiel wird die Anzahl der Orte mit mindestens zehn Tesla-Ladestationen gezählt, die Schnellladen unterstützen:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(ev_charge_options.connector_aggregation) as connectors WHERE connectors.type ='EV_CONNECTOR_TYPE_TESLA' AND connectors.max_charge_rate_kw >= 50 AND connectors.count >= 10
Ergebnisgruppen zurückgeben
Die bisher gezeigten Abfragen geben eine einzelne Zeile im Ergebnis zurück, die die Aggregationsanzahl für die Abfrage enthält. Sie können auch den Operator GROUP BY verwenden, um basierend auf den Gruppierungskriterien mehrere Zeilen in der Antwort zurückzugeben.
Die folgende Abfrage gibt beispielsweise Ergebnisse zurück, die nach dem primären Typ jedes Orts im Suchbereich gruppiert sind:
SELECT WITH AGGREGATION_THRESHOLD primary_type, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.99992071622756, 40.71818785986936), point, 1000) GROUP BY primary_type
Diese Abbildung zeigt eine Beispielausgabe für diese Abfrage:

In diesem Beispiel definieren Sie eine Tabelle mit Orten. Für jeden Ort berechnen Sie dann die Anzahl der Restaurants in der Nähe, d. h. im Umkreis von 1.000 Metern:
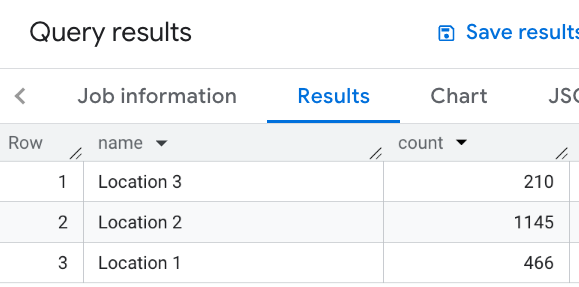
WITH my_locations AS ( SELECT 'Location 1' AS name, ST_GEOGPOINT(-74.00776440888504, 40.70932825380786) AS location UNION ALL SELECT 'Location 2' AS name, ST_GEOGPOINT(-73.98257192833559, 40.750738934863215) AS location UNION ALL SELECT 'Location 3' AS name, ST_GEOGPOINT(-73.94701794263223, 40.80792954838445) AS location ) SELECT WITH AGGREGATION_THRESHOLD l.name, COUNT(*) as count FROM `PROJECT_NAME.places_insights___us.places` JOIN my_locations l ON ST_DWITHIN(l.location, p.point, 1000) WHERE primary_type = "restaurant" AND business_status = "OPERATIONAL" GROUP BY l.name
Diese Abbildung zeigt eine Beispielausgabe für diese Abfrage: