 GitHub-এ উৎস দেখুন
GitHub-এ উৎস দেখুনএই টিউটোরিয়ালে, Google আর্থ ইঞ্জিন ব্যবহার করে প্রজাতি বন্টন মডেলিংয়ের পদ্ধতি চালু করা হবে। প্রজাতি বন্টন মডেলিংয়ের একটি সংক্ষিপ্ত বিবরণ প্রদান করা হবে, তারপরে ফেয়ারি পিট্টা (বৈজ্ঞানিক নাম: পিট্টা নিম্ফা ) নামে পরিচিত একটি বিপন্ন পাখি প্রজাতির বাসস্থানের পূর্বাভাস এবং বিশ্লেষণের প্রক্রিয়া অনুসরণ করা হবে।
আগে আমাকে চালান
API শুরু করতে নিম্নলিখিত ঘরটি চালান। আউটপুটে আপনার অ্যাকাউন্ট ব্যবহার করে আর্থ ইঞ্জিনে এই নোটবুকটিকে কীভাবে অ্যাক্সেস দেওয়া যায় তার নির্দেশাবলী থাকবে।
import ee
# Trigger the authentication flow.
ee.Authenticate()
# Initialize the library.
ee.Initialize(project='my-project')
প্রজাতি বিতরণ মডেলিংয়ের একটি সংক্ষিপ্ত বিবরণ
আসুন জেনে নেই প্রজাতির বন্টন মডেলগুলি কী, তাদের প্রক্রিয়াকরণের জন্য Google আর্থ ইঞ্জিন ব্যবহার করার সুবিধাগুলি, মডেলগুলির জন্য প্রয়োজনীয় ডেটা এবং কর্মপ্রবাহটি কীভাবে গঠন করা হয়।
প্রজাতি বিতরণ মডেলিং কি?
প্রজাতি বন্টন মডেলিং (নীচে SDM) হল একটি প্রজাতির প্রকৃত বা সম্ভাব্য ভৌগলিক বন্টন অনুমান করার জন্য ব্যবহৃত সবচেয়ে সাধারণ পদ্ধতি। এটি একটি নির্দিষ্ট প্রজাতির জন্য উপযুক্ত পরিবেশগত অবস্থার বৈশিষ্ট্যযুক্ত এবং তারপর চিহ্নিত করে যেখানে এই উপযুক্ত অবস্থাগুলি ভৌগলিকভাবে বিতরণ করা হয়।
সাম্প্রতিক বছরগুলিতে এসডিএম সংরক্ষণ পরিকল্পনার একটি গুরুত্বপূর্ণ উপাদান হিসাবে আবির্ভূত হয়েছে এবং এই উদ্দেশ্যে বিভিন্ন মডেলিং কৌশল তৈরি করা হয়েছে। Google আর্থ ইঞ্জিনে (নীচে GEE) SDM প্রয়োগ করা দ্রুত মডেলিংয়ের জন্য শক্তিশালী কম্পিউটিং ক্ষমতা এবং মেশিন লার্নিং অ্যালগরিদমগুলির জন্য সমর্থন সহ বড় আকারের পরিবেশগত ডেটাতে সহজ অ্যাক্সেস সরবরাহ করে।
এসডিএম-এর জন্য প্রয়োজনীয় ডেটা
SDM সাধারণত পরিচিত প্রজাতির সংঘটন রেকর্ড এবং পরিবেশগত ভেরিয়েবলের মধ্যে সম্পর্ককে ব্যবহার করে এমন পরিস্থিতি সনাক্ত করতে যা একটি জনসংখ্যা টিকিয়ে রাখতে পারে। অন্য কথায়, দুটি ধরণের মডেল ইনপুট ডেটা প্রয়োজন:
- পরিচিত প্রজাতির ঘটনার রেকর্ড
- বিভিন্ন পরিবেশগত পরিবর্তনশীল
এই তথ্যগুলি প্রজাতির উপস্থিতির সাথে সম্পর্কিত পরিবেশগত অবস্থা সনাক্ত করতে অ্যালগরিদমগুলিতে ইনপুট করা হয়।
GEE ব্যবহার করে SDM-এর কর্মপ্রবাহ
GEE ব্যবহার করে SDM-এর কর্মপ্রবাহ নিম্নরূপ:
- প্রজাতির সংঘটন তথ্য সংগ্রহ এবং প্রিপ্রসেসিং
- আগ্রহের এলাকার সংজ্ঞা
- GEE পরিবেশগত ভেরিয়েবলের সংযোজন
- ছদ্ম-অনুপস্থিতি ডেটা তৈরি করা
- মডেল ফিটিং এবং ভবিষ্যদ্বাণী
- পরিবর্তনশীল গুরুত্ব এবং নির্ভুলতা মূল্যায়ন
জিইই ব্যবহার করে বাসস্থানের পূর্বাভাস এবং বিশ্লেষণ
পরী পিট্টা ( Pitta nympha ) কেস স্টাডি হিসেবে ব্যবহার করা হবে GEE-ভিত্তিক SDM-এর আবেদন প্রদর্শনের জন্য। যদিও এই নির্দিষ্ট প্রজাতিটিকে একটি উদাহরণের জন্য নির্বাচিত করা হয়েছে, গবেষকরা প্রদত্ত সোর্স কোডে সামান্য পরিবর্তনের সাথে আগ্রহের যে কোনো লক্ষ্য প্রজাতির জন্য পদ্ধতিটি প্রয়োগ করতে পারেন।
পরী পিট্টা দক্ষিণ কোরিয়ার একটি বিরল গ্রীষ্মকালীন অভিবাসী এবং উত্তরণ অভিবাসী, যার বিতরণ এলাকা কোরীয় উপদ্বীপে সাম্প্রতিক জলবায়ু উষ্ণতার কারণে প্রসারিত হচ্ছে। এটি একটি বিরল প্রজাতি, দ্বিতীয় শ্রেণীর বিপন্ন বন্যপ্রাণী, প্রাকৃতিক স্মৃতিস্তম্ভ নং 204, জাতীয় লাল তালিকায় আঞ্চলিকভাবে বিলুপ্ত (আরই) হিসাবে মূল্যায়ন করা এবং IUCN বিভাগ অনুসারে দুর্বল (VU) হিসাবে শ্রেণীবদ্ধ করা হয়েছে।
পরী পিট্টের সংরক্ষণ পরিকল্পনার জন্য এসডিএম পরিচালনা করা বেশ মূল্যবান বলে মনে হচ্ছে। এখন, জিইই-এর মাধ্যমে বাসস্থানের পূর্বাভাস এবং বিশ্লেষণ নিয়ে এগিয়ে যাওয়া যাক।
প্রথমত, পাইথন লাইব্রেরিগুলি আমদানি করা হয়৷ import বিবৃতি একটি মডিউলের সম্পূর্ণ বিষয়বস্তু নিয়ে আসে, যখন from import বিবৃতিটি একটি মডিউল থেকে নির্দিষ্ট বস্তু আমদানির অনুমতি দেয়৷
# Import libraries
import geemap
import geemap.colormaps as cm
import pandas as pd, geopandas as gpd
import numpy as np, matplotlib.pyplot as plt
import os, requests, math, random
from ipyleaflet import TileLayer
from statsmodels.stats.outliers_influence import variance_inflation_factor
প্রজাতি সংঘটন তথ্য সংগ্রহ এবং প্রিপ্রসেসিং
এখন, ফেইরি পিট্টার ঘটনার তথ্য সংগ্রহ করা যাক। এমনকি যদি আপনার কাছে বর্তমানে আগ্রহের প্রজাতির সংঘটন ডেটাতে অ্যাক্সেস নাও থাকে, আপনি GBIF API-এর মাধ্যমে নির্দিষ্ট প্রজাতি সম্পর্কে পর্যবেক্ষণমূলক ডেটা পেতে পারেন। GBIF API হল একটি ইন্টারফেস যা GBIF দ্বারা প্রদত্ত প্রজাতি বিতরণ ডেটাতে অ্যাক্সেসের অনুমতি দেয়, ব্যবহারকারীদের অনুসন্ধান, ফিল্টার এবং ডেটা ডাউনলোড করতে এবং সেইসাথে প্রজাতি সম্পর্কিত বিভিন্ন তথ্য অর্জন করতে সক্ষম করে।
নিচের কোডে, species_name ভেরিয়েবলটিকে প্রজাতির বৈজ্ঞানিক নাম বরাদ্দ করা হয়েছে (যেমন, Fairy pitta-এর জন্য Pitta nympha ), এবং country_code ভেরিয়েবলটিকে দেশের কোড (যেমন, দক্ষিণ কোরিয়ার জন্য KR) বরাদ্দ করা হয়েছে। base_url ভেরিয়েবল GBIF API-এর ঠিকানা সংরক্ষণ করে। params হল API অনুরোধে ব্যবহার করা প্যারামিটার ধারণকারী একটি অভিধান:
-
scientificName: অনুসন্ধান করা প্রজাতির বৈজ্ঞানিক নাম সেট করে। -
country: একটি নির্দিষ্ট দেশে অনুসন্ধান সীমাবদ্ধ করে। -
hasCoordinate: শুধুমাত্র স্থানাঙ্ক (সত্য) সহ ডেটা অনুসন্ধান করা হয়েছে তা নিশ্চিত করে। -
basisOfRecord: শুধুমাত্র মানুষের পর্যবেক্ষণের রেকর্ড বেছে নেয় (HUMAN_OBSERVATION)। -
limit: 10000-এ ফেরত আসা ফলাফলের সর্বোচ্চ সংখ্যা সেট করে।
def get_gbif_species_data(species_name, country_code):
"""
Retrieves observational data for a specific species using the GBIF API and returns it as a pandas DataFrame.
Parameters:
species_name (str): The scientific name of the species to query.
country_code (str): The country code of the where the observation data will be queried.
Returns:
pd.DataFrame: A pandas DataFrame containing the observational data.
"""
base_url = "https://api.gbif.org/v1/occurrence/search"
params = {
"scientificName": species_name,
"country": country_code,
"hasCoordinate": "true",
"basisOfRecord": "HUMAN_OBSERVATION",
"limit": 10000,
}
try:
response = requests.get(base_url, params=params)
response.raise_for_status() # Raises an exception for a response error.
data = response.json()
occurrences = data.get("results", [])
if occurrences: # If data is present
df = pd.json_normalize(occurrences)
return df
else:
print("No data found for the given species and country code.")
return pd.DataFrame() # Returns an empty DataFrame
except requests.RequestException as e:
print(f"Request failed: {e}")
return pd.DataFrame() # Returns an empty DataFrame in case of an exception
পূর্বে সেট করা পরামিতি ব্যবহার করে, আমরা পরী পিট্টা ( Pitta nympha ) এর পর্যবেক্ষণমূলক রেকর্ডের জন্য GBIF API-কে জিজ্ঞাসা করি এবং প্রথম সারিটি পরীক্ষা করার জন্য একটি ডেটাফ্রেমে ফলাফল লোড করি। একটি ডেটাফ্রেম হল সারি এবং কলাম সমন্বিত টেবিল-ফরম্যাট করা ডেটা পরিচালনা করার জন্য একটি ডেটা কাঠামো। প্রয়োজনে, ডেটাফ্রেমটিকে একটি CSV ফাইল হিসাবে সংরক্ষণ করা যেতে পারে এবং পুনরায় পড়তে পারেন৷
# Retrieve Fairy Pitta data
df = get_gbif_species_data("Pitta nympha", "KR")
"""
# Save DataFrame to CSV and read back in.
df.to_csv("pitta_nympha_data.csv", index=False)
df = pd.read_csv("pitta_nympha_data.csv")
"""
df.head(1) # Display the first row of the DataFrame
এর পরে, আমরা ডেটাফ্রেমটিকে একটি জিওডেটাফ্রেমে রূপান্তর করি যাতে ভৌগলিক তথ্যের জন্য একটি কলাম রয়েছে ( geometry ) এবং প্রথম সারিটি পরীক্ষা করুন৷ একটি GeoDataFrame একটি জিওপ্যাকেজ ফাইল (*.gpkg) হিসাবে সংরক্ষণ করা যেতে পারে এবং আবার পড়তে পারে৷
# Convert DataFrame to GeoDataFrame
gdf = gpd.GeoDataFrame(
df,
geometry=gpd.points_from_xy(df.decimalLongitude,
df.decimalLatitude),
crs="EPSG:4326"
)[["species", "year", "month", "geometry"]]
"""
# Convert GeoDataFrame to GeoPackage (requires pycrs module)
%pip install -U -q pycrs
gdf.to_file("pitta_nympha_data.gpkg", driver="GPKG")
gdf = gpd.read_file("pitta_nympha_data.gpkg")
"""
gdf.head(1) # Display the first row of the GeoDataFrame
এইবার, আমরা GeoDataFrame থেকে বছর এবং মাসে ডেটা বন্টন কল্পনা করার জন্য একটি ফাংশন তৈরি করেছি এবং এটিকে একটি গ্রাফ হিসাবে প্রদর্শন করেছি, যা পরে একটি চিত্র ফাইল হিসাবে সংরক্ষণ করা যেতে পারে। একটি হিটম্যাপের ব্যবহার আমাদেরকে বছর এবং মাস দ্বারা প্রজাতির সংঘটনের ফ্রিকোয়েন্সি দ্রুত উপলব্ধি করতে দেয়, তথ্যের মধ্যে সাময়িক পরিবর্তন এবং প্যাটার্নগুলির একটি স্বজ্ঞাত ভিজ্যুয়ালাইজেশন প্রদান করে। এটি প্রজাতির সংঘটন ডেটাতে অস্থায়ী নিদর্শন এবং ঋতুগত বৈচিত্র সনাক্তকরণের পাশাপাশি ডেটার মধ্যে বহিরাগত বা গুণমানের সমস্যাগুলির দ্রুত সনাক্তকরণের অনুমতি দেয়।
# Yearly and monthly data distribution heatmap
def plot_heatmap(gdf, h_size=8):
statistics = gdf.groupby(["month", "year"]).size().unstack(fill_value=0)
# Heatmap
plt.figure(figsize=(h_size, h_size - 6))
heatmap = plt.imshow(
statistics.values, cmap="YlOrBr", origin="upper", aspect="auto"
)
# Display values above each pixel
for i in range(len(statistics.index)):
for j in range(len(statistics.columns)):
plt.text(
j, i, statistics.values[i, j], ha="center", va="center", color="black"
)
plt.colorbar(heatmap, label="Count")
plt.title("Monthly Species Count by Year")
plt.xlabel("Year")
plt.ylabel("Month")
plt.xticks(range(len(statistics.columns)), statistics.columns)
plt.yticks(range(len(statistics.index)), statistics.index)
plt.tight_layout()
plt.savefig("heatmap_plot.png")
plt.show()
plot_heatmap(gdf)
অন্যান্য বছরের তুলনায় 1995 সালের তথ্য খুবই বিরল, এবং আগস্ট এবং সেপ্টেম্বর মাসেও সীমিত নমুনা রয়েছে এবং অন্যান্য সময়ের তুলনায় বিভিন্ন ঋতুগত বৈশিষ্ট্য প্রদর্শন করে। এই ডেটা বাদ দিলে মডেলের স্থিতিশীলতা এবং ভবিষ্যদ্বাণীমূলক শক্তির উন্নতিতে অবদান রাখতে পারে।
যাইহোক, এটি মনে রাখা গুরুত্বপূর্ণ যে ডেটা বাদ দিলে মডেলের সাধারণীকরণ ক্ষমতা বাড়তে পারে, তবে এটি গবেষণার উদ্দেশ্যগুলির সাথে প্রাসঙ্গিক মূল্যবান তথ্যের ক্ষতির দিকেও যেতে পারে। অতএব, এই ধরনের সিদ্ধান্ত সাবধানে বিবেচনা করা উচিত।
# Filtering data by year and month
filtered_gdf = gdf[
(~gdf['year'].eq(1995)) &
(~gdf['month'].between(8, 9))
]
এখন, ফিল্টার করা GeoDataFrame একটি Google Earth Engine অবজেক্টে রূপান্তরিত হয়েছে।
# Convert GeoDataFrame to Earth Engine object
data_raw = geemap.geopandas_to_ee(filtered_gdf)
এর পরে, আমরা SDM ফলাফলের রাস্টার পিক্সেল আকারকে 1km রেজোলিউশন হিসাবে সংজ্ঞায়িত করব।
# Spatial resolution setting (meters)
grain_size = 1000
যখন একই 1কিমি রেজোলিউশন রাস্টার পিক্সেলের মধ্যে একাধিক ঘটনা বিন্দু উপস্থিত থাকে, তখন একই ভৌগলিক অবস্থানে একই পরিবেশগত পরিস্থিতি ভাগ করার একটি উচ্চ সম্ভাবনা থাকে। বিশ্লেষণে সরাসরি এই ধরনের ডেটা ব্যবহার করা ফলাফলে পক্ষপাতিত্বের পরিচয় দিতে পারে।
অন্য কথায়, আমাদের ভৌগলিক স্যাম্পলিং পক্ষপাতের সম্ভাব্য প্রভাব সীমিত করতে হবে। এটি অর্জন করতে, আমরা প্রতিটি 1কিমি পিক্সেলের মধ্যে শুধুমাত্র একটি অবস্থান ধরে রাখব এবং অন্য সবগুলি সরিয়ে দেব, মডেলটিকে পরিবেশগত অবস্থার আরও উদ্দেশ্যমূলকভাবে প্রতিফলিত করার অনুমতি দেবে৷
def remove_duplicates(data, grain_size):
# Select one occurrence record per pixel at the chosen spatial resolution
random_raster = ee.Image.random().reproject("EPSG:4326", None, grain_size)
rand_point_vals = random_raster.sampleRegions(
collection=ee.FeatureCollection(data), geometries=True
)
return rand_point_vals.distinct("random")
data = remove_duplicates(data_raw, grain_size)
# Before selection and after selection
print("Original data size:", data_raw.size().getInfo())
print("Final data size:", data.size().getInfo())
প্রিপ্রসেসিংয়ের আগে (নীল রঙে) এবং প্রি-প্রসেসিংয়ের পরে (লাল রঙে) ভৌগলিক স্যাম্পলিং পক্ষপাতের তুলনামূলক ভিজ্যুয়ালাইজেশন নীচে দেখানো হয়েছে। তুলনা করার সুবিধার্থে, মানচিত্রটি হাল্লাসান ন্যাশনাল পার্কে ফেয়ারি পিট্টা ঘটনা স্থানাঙ্কের উচ্চ ঘনত্ব সহ এলাকার উপর কেন্দ্রীভূত করা হয়েছে।
# Visualization of geographic sampling bias before (blue) and after (red) preprocessing
Map = geemap.Map(layout={"height": "400px", "width": "800px"})
# Add the random raster layer
random_raster = ee.Image.random().reproject("EPSG:4326", None, grain_size)
Map.addLayer(
random_raster,
{"min": 0, "max": 1, "palette": ["black", "white"], "opacity": 0.5},
"Random Raster",
)
# Add the original data layer in blue
Map.addLayer(data_raw, {"color": "blue"}, "Original data")
# Add the final data layer in red
Map.addLayer(data, {"color": "red"}, "Final data")
# Set the center of the map to the coordinates
Map.setCenter(126.712, 33.516, 14)
Map
আগ্রহের এলাকার সংজ্ঞা
আগ্রহের ক্ষেত্র সংজ্ঞায়িত করা (নীচে AOI) বলতে গবেষকরা যে ভৌগলিক এলাকা বিশ্লেষণ করতে চান তা বোঝাতে ব্যবহৃত শব্দটিকে বোঝায়। এটি অধ্যয়ন এলাকা শব্দটির অনুরূপ অর্থ রয়েছে।
এই প্রসঙ্গে, আমরা ঘটনা বিন্দু স্তর জ্যামিতির বাউন্ডিং বক্স পেয়েছি এবং AOI সংজ্ঞায়িত করতে এটির চারপাশে একটি 50-কিলোমিটার বাফার তৈরি করেছি (সর্বোচ্চ 1,000 মিটার সহনশীলতা সহ)।
# Define the AOI
aoi = data.geometry().bounds().buffer(distance=50000, maxError=1000)
# Add the AOI to the map
outline = ee.Image().byte().paint(
featureCollection=aoi, color=1, width=3)
Map.remove_layer("Random Raster")
Map.addLayer(outline, {'palette': 'FF0000'}, "AOI")
Map.centerObject(aoi, 6)
Map
GEE পরিবেশগত ভেরিয়েবলের সংযোজন
এখন, বিশ্লেষণে পরিবেশগত ভেরিয়েবল যোগ করা যাক। GEE পরিবেশগত ভেরিয়েবল যেমন তাপমাত্রা, বৃষ্টিপাত, উচ্চতা, ভূমি আচ্ছাদন এবং ভূখণ্ডের জন্য ডেটাসেটের একটি বিস্তৃত পরিসর সরবরাহ করে। এই ডেটাসেটগুলি পরী পিট্টার বাসস্থান পছন্দগুলিকে প্রভাবিত করতে পারে এমন বিভিন্ন কারণগুলিকে ব্যাপকভাবে বিশ্লেষণ করতে আমাদের সক্ষম করে৷
SDM-তে GEE পরিবেশগত ভেরিয়েবলের নির্বাচন প্রজাতির বাসস্থান পছন্দ বৈশিষ্ট্য প্রতিফলিত করা উচিত। এটি করার জন্য, পরী পিট্টার বাসস্থান পছন্দগুলির উপর পূর্বে গবেষণা এবং সাহিত্য পর্যালোচনা করা উচিত। এই টিউটোরিয়ালটি প্রাথমিকভাবে GEE ব্যবহার করে SDM-এর কর্মপ্রবাহের উপর ফোকাস করে, তাই কিছু গভীর বিবরণ বাদ দেওয়া হয়েছে।
ওয়ার্ল্ডক্লিম V1 বায়োক্লিম : এই ডেটাসেটটি মাসিক তাপমাত্রা এবং বৃষ্টিপাতের ডেটা থেকে প্রাপ্ত 19টি বায়োক্লিম্যাটিক ভেরিয়েবল প্রদান করে। এটি 1960 থেকে 1991 সময়কালকে কভার করে এবং এর রেজোলিউশন 927.67 মিটার।
# WorldClim V1 Bioclim
bio = ee.Image("WORLDCLIM/V1/BIO")
NASA SRTM ডিজিটাল এলিভেশন 30m : এই ডেটাসেটে শাটল রাডার টপোগ্রাফি মিশন (SRTM) থেকে ডিজিটাল এলিভেশন ডেটা রয়েছে। তথ্যটি প্রাথমিকভাবে 2000 সালের দিকে সংগ্রহ করা হয়েছিল এবং প্রায় 30 মিটার (1 আর্ক-সেকেন্ড) রেজোলিউশনে সরবরাহ করা হয়েছিল। নিম্নলিখিত কোডটি SRTM ডেটা থেকে উচ্চতা, ঢাল, দৃষ্টিভঙ্গি এবং পাহাড়ের ছায়া স্তরগুলি গণনা করে৷
# NASA SRTM Digital Elevation 30m
terrain = ee.Algorithms.Terrain(ee.Image("USGS/SRTMGL1_003"))
গ্লোবাল ফরেস্ট কভার চেঞ্জ (GFCC) ট্রি কভার মাল্টি-ইয়ার গ্লোবাল 30m : ল্যান্ডস্যাট থেকে ভেজিটেশন কন্টিনিউয়াস ফিল্ডস (ভিসিএফ) ডেটাসেট যখন গাছের উচ্চতা 5 মিটারের বেশি হয় তখন উল্লম্বভাবে অনুমান করা গাছপালা কভারের অনুপাত অনুমান করে। এই ডেটাসেটটি 2000, 2005, 2010, এবং 2015 সালকে কেন্দ্র করে চারটি সময়ের জন্য প্রদান করা হয়েছে, যার রেজোলিউশন 30 মিটার। এখানে, এই চারটি সময়কালের মধ্যম মান ব্যবহার করা হয়।
# Global Forest Cover Change (GFCC) Tree Cover Multi-Year Global 30m
tcc = ee.ImageCollection("NASA/MEASURES/GFCC/TC/v3")
median_tcc = (
tcc.filterDate("2000-01-01", "2015-12-31")
.select(["tree_canopy_cover"], ["TCC"])
.median()
)
bio (বায়োক্লাইমেটিক ভেরিয়েবল), terrain (টপোগ্রাফি), এবং median_tcc (ট্রি ক্যানোপি কভার) একটি একক মাল্টিব্যান্ড চিত্রে একত্রিত হয়। elevation ব্যান্ড terrain থেকে নির্বাচন করা হয়, এবং যেখানে elevation 0 এর বেশি সেগুলির জন্য একটি watermask তৈরি করা হয়। এটি সমুদ্রপৃষ্ঠের নীচের অঞ্চলগুলিকে (যেমন মহাসাগর) মাস্ক করে এবং গবেষককে AOI এর জন্য বিভিন্ন পরিবেশগত কারণগুলি ব্যাপকভাবে বিশ্লেষণ করতে প্রস্তুত করে।
# Combine bands into a multi-band image
predictors = bio.addBands(terrain).addBands(median_tcc)
# Create a water mask
watermask = terrain.select('elevation').gt(0)
# Mask out ocean pixels and clip to the area of interest
predictors = predictors.updateMask(watermask).clip(aoi)
যখন অত্যন্ত পারস্পরিক সম্পর্কযুক্ত ভবিষ্যদ্বাণীকারী ভেরিয়েবলগুলিকে একটি মডেলে একত্রে অন্তর্ভুক্ত করা হয়, তখন বহুসংখ্যার সমস্যা দেখা দিতে পারে। মাল্টিকোলিনিয়ারিটি এমন একটি ঘটনা যা ঘটে যখন একটি মডেলের স্বাধীন ভেরিয়েবলের মধ্যে শক্তিশালী রৈখিক সম্পর্ক থাকে, যা মডেলের সহগ (ওজন) অনুমানে অস্থিরতার দিকে পরিচালিত করে। এই অস্থিরতা মডেলের নির্ভরযোগ্যতা হ্রাস করতে পারে এবং নতুন ডেটা চ্যালেঞ্জিং এর জন্য ভবিষ্যদ্বাণী বা ব্যাখ্যা করতে পারে। অতএব, আমরা মাল্টিকোলিনিয়ারিটি বিবেচনা করব এবং ভবিষ্যদ্বাণীকারী ভেরিয়েবল নির্বাচন করার প্রক্রিয়াটি নিয়ে এগিয়ে যাব।
প্রথমে, আমরা 5,000 র্যান্ডম পয়েন্ট তৈরি করব এবং তারপর সেই পয়েন্টগুলিতে একক মাল্টিব্যান্ড চিত্রের ভবিষ্যদ্বাণীকারী পরিবর্তনশীল মানগুলি বের করব।
# Generate 5,000 random points
data_cor = predictors.sample(scale=grain_size, numPixels=5000, geometries=True)
# Extract predictor variable values
pvals = predictors.sampleRegions(collection=data_cor, scale=grain_size)
আমরা প্রতিটি পয়েন্টের জন্য এক্সট্র্যাক্ট করা ভবিষ্যদ্বাণীর মানগুলিকে একটি ডেটাফ্রেমে রূপান্তর করব এবং তারপর প্রথম সারিটি পরীক্ষা করব।
# Converting predictor values from Earth Engine to a DataFrame
pvals_df = geemap.ee_to_df(pvals)
pvals_df.head(1)
# Displaying the columns
columns = pvals_df.columns
print(columns)
প্রদত্ত ভবিষ্যদ্বাণীকারী ভেরিয়েবলের মধ্যে স্পিয়ারম্যান পারস্পরিক সম্পর্ক সহগ গণনা করা এবং একটি হিটম্যাপে তাদের কল্পনা করা।
def plot_correlation_heatmap(dataframe, h_size=10, show_labels=False):
# Calculate Spearman correlation coefficients
correlation_matrix = dataframe.corr(method="spearman")
# Create a heatmap
plt.figure(figsize=(h_size, h_size-2))
plt.imshow(correlation_matrix, cmap='coolwarm', interpolation='nearest')
# Optionally display values on the heatmap
if show_labels:
for i in range(correlation_matrix.shape[0]):
for j in range(correlation_matrix.shape[1]):
plt.text(j, i, f"{correlation_matrix.iloc[i, j]:.2f}",
ha='center', va='center', color='white', fontsize=8)
columns = dataframe.columns.tolist()
plt.xticks(range(len(columns)), columns, rotation=90)
plt.yticks(range(len(columns)), columns)
plt.title("Variables Correlation Matrix")
plt.colorbar(label="Spearman Correlation")
plt.savefig('correlation_heatmap_plot.png')
plt.show()
# Plot the correlation heatmap of variables
plot_correlation_heatmap(pvals_df)
স্পিয়ারম্যান পারস্পরিক সম্পর্ক সহগ ভবিষ্যদ্বাণীকারী ভেরিয়েবলগুলির মধ্যে সাধারণ সংযোগগুলি বোঝার জন্য দরকারী তবে একাধিক ভেরিয়েবলগুলি কীভাবে ইন্টারঅ্যাক্ট করে তা সরাসরি মূল্যায়ন করে না, বিশেষত মাল্টিকলিনিয়ারিটি সনাক্ত করে।
ভ্যারিয়েন্স ইনফ্লেশন ফ্যাক্টর (নীচে ভিআইএফ) হল একটি পরিসংখ্যানগত মেট্রিক যা মাল্টিকোলাইন্যারিটি মূল্যায়ন করতে এবং পরিবর্তনশীল নির্বাচনকে গাইড করতে ব্যবহৃত হয়। এটি অন্যান্য স্বাধীন ভেরিয়েবলের সাথে প্রতিটি স্বাধীন ভেরিয়েবলের রৈখিক সম্পর্কের ডিগ্রী নির্দেশ করে এবং উচ্চ ভিআইএফ মান মাল্টিকোলিনিয়ারটির প্রমাণ হতে পারে।
সাধারণত, যখন VIF মান 5 বা 10 অতিক্রম করে, তখন এটি পরামর্শ দেয় যে ভেরিয়েবলের অন্যান্য ভেরিয়েবলের সাথে একটি শক্তিশালী সম্পর্ক রয়েছে, সম্ভাব্যভাবে মডেলের স্থায়িত্ব এবং ব্যাখ্যাযোগ্যতার সাথে আপস করে। এই টিউটোরিয়ালে, পরিবর্তনশীল নির্বাচনের জন্য 10-এর কম VIF মানের একটি মানদণ্ড ব্যবহার করা হয়েছিল। VIF এর উপর ভিত্তি করে নিম্নলিখিত 6টি ভেরিয়েবল নির্বাচন করা হয়েছে।
# Filter variables based on Variance Inflation Factor (VIF)
def filter_variables_by_vif(dataframe, threshold=10):
original_columns = dataframe.columns.tolist()
remaining_columns = original_columns[:]
while True:
vif_data = dataframe[remaining_columns]
vif_values = [
variance_inflation_factor(vif_data.values, i)
for i in range(vif_data.shape[1])
]
max_vif_index = vif_values.index(max(vif_values))
max_vif = max(vif_values)
if max_vif < threshold:
break
print(f"Removing '{remaining_columns[max_vif_index]}' with VIF {max_vif:.2f}")
del remaining_columns[max_vif_index]
filtered_data = dataframe[remaining_columns]
bands = filtered_data.columns.tolist()
print("Bands:", bands)
return filtered_data, bands
filtered_pvals_df, bands = filter_variables_by_vif(pvals_df)
# Variable Selection Based on VIF
predictors = predictors.select(bands)
# Plot the correlation heatmap of variables
plot_correlation_heatmap(filtered_pvals_df, h_size=6, show_labels=True)
এর পরে, মানচিত্রে 6টি নির্বাচিত ভবিষ্যদ্বাণীকারী ভেরিয়েবলের কল্পনা করা যাক। 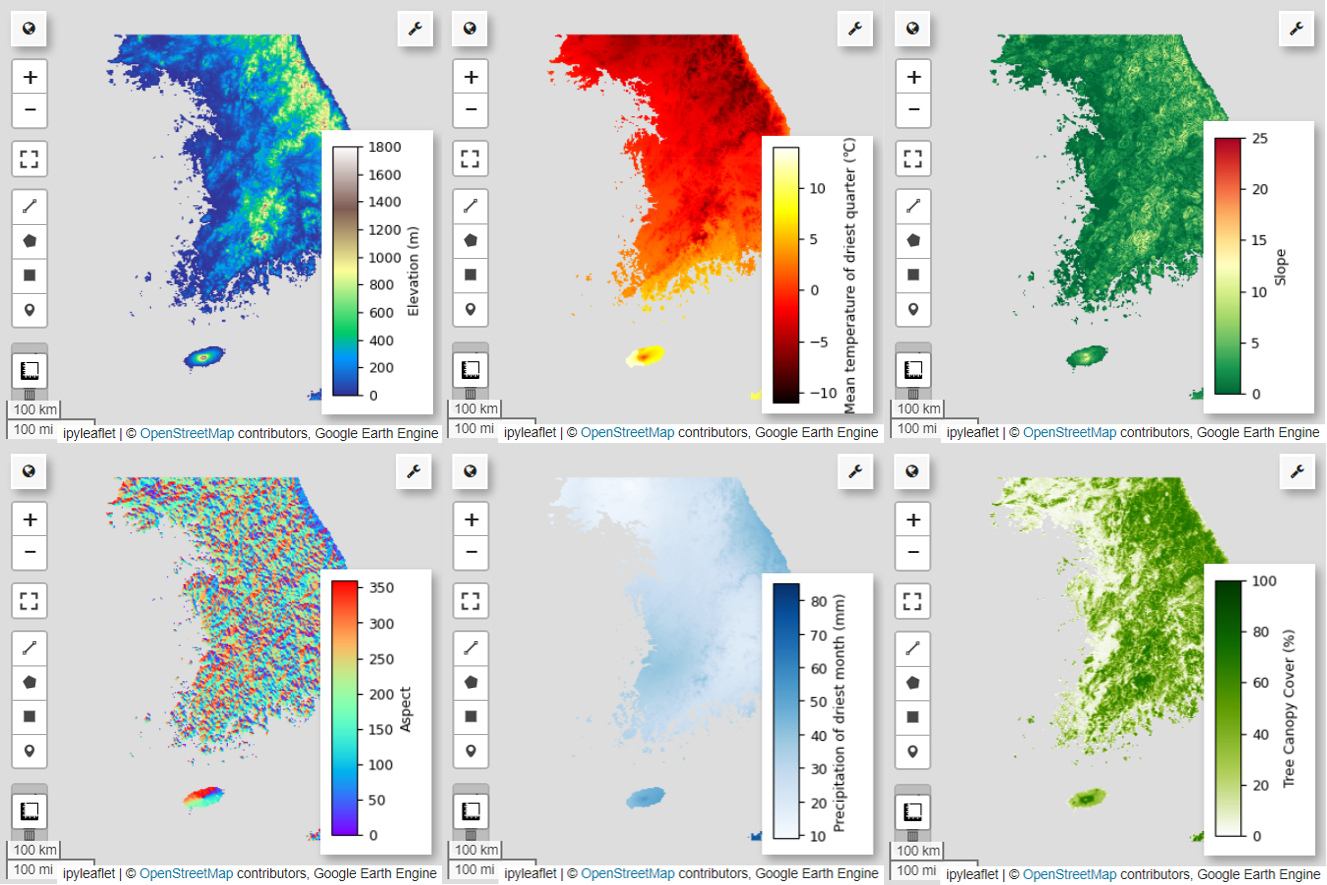
আপনি নিম্নলিখিত কোড ব্যবহার করে মানচিত্র ভিজ্যুয়ালাইজেশনের জন্য উপলব্ধ প্যালেটগুলি অন্বেষণ করতে পারেন। উদাহরণস্বরূপ, terrain প্যালেট এই মত দেখায়। cm.plot_colormaps(width=8.0, height=0.2)
cm.plot_colormap('terrain', width=8.0, height=0.2, orientation='horizontal')
# Elevation layer
Map = geemap.Map(layout={'height':'400px', 'width':'800px'})
vis_params = {'bands':['elevation'], 'min': 0, 'max': 1800, 'palette': cm.palettes.terrain}
Map.addLayer(predictors, vis_params, 'elevation')
Map.add_colorbar(vis_params, label="Elevation (m)", orientation="vertical", layer_name="elevation")
Map.centerObject(aoi, 6)
Map
# Calculate the minimum and maximum values for bio09
min_max_val = (
predictors.select("bio09")
.multiply(0.1)
.reduceRegion(reducer=ee.Reducer.minMax(), scale=1000)
.getInfo()
)
# bio09 (Mean temperature of driest quarter) layer
Map = geemap.Map(layout={"height": "400px", "width": "800px"})
vis_params = {
"min": math.floor(min_max_val["bio09_min"]),
"max": math.ceil(min_max_val["bio09_max"]),
"palette": cm.palettes.hot,
}
Map.addLayer(predictors.select("bio09").multiply(0.1), vis_params, "bio09")
Map.add_colorbar(
vis_params,
label="Mean temperature of driest quarter (℃)",
orientation="vertical",
layer_name="bio09",
)
Map.centerObject(aoi, 6)
Map
# Slope layer
Map = geemap.Map(layout={'height':'400px', 'width':'800px'})
vis_params = {'bands':['slope'], 'min': 0, 'max': 25, 'palette': cm.palettes.RdYlGn_r}
Map.addLayer(predictors, vis_params, 'slope')
Map.add_colorbar(vis_params, label="Slope", orientation="vertical", layer_name="slope")
Map.centerObject(aoi, 6)
Map
# Aspect layer
Map = geemap.Map(layout={'height':'400px', 'width':'800px'})
vis_params = {'bands':['aspect'], 'min': 0, 'max': 360, 'palette': cm.palettes.rainbow}
Map.addLayer(predictors, vis_params, 'aspect')
Map.add_colorbar(vis_params, label="Aspect", orientation="vertical", layer_name="aspect")
Map.centerObject(aoi, 6)
Map
# Calculate the minimum and maximum values for bio14
min_max_val = (
predictors.select("bio14")
.reduceRegion(reducer=ee.Reducer.minMax(), scale=1000)
.getInfo()
)
# bio14 (Precipitation of driest month) layer
Map = geemap.Map(layout={"height": "400px", "width": "800px"})
vis_params = {
"bands": ["bio14"],
"min": math.floor(min_max_val["bio14_min"]),
"max": math.ceil(min_max_val["bio14_max"]),
"palette": cm.palettes.Blues,
}
Map.addLayer(predictors, vis_params, "bio14")
Map.add_colorbar(
vis_params,
label="Precipitation of driest month (mm)",
orientation="vertical",
layer_name="bio14",
)
Map.centerObject(aoi, 6)
Map
# TCC layer
Map = geemap.Map(layout={"height": "400px", "width": "800px"})
vis_params = {
"bands": ["TCC"],
"min": 0,
"max": 100,
"palette": ["ffffff", "afce56", "5f9c00", "0e6a00", "003800"],
}
Map.addLayer(predictors, vis_params, "TCC")
Map.add_colorbar(
vis_params, label="Tree Canopy Cover (%)", orientation="vertical", layer_name="TCC"
)
Map.centerObject(aoi, 6)
Map
ছদ্ম-অনুপস্থিতি ডেটা তৈরি করা
এসডিএম প্রক্রিয়ায়, একটি প্রজাতির জন্য ইনপুট ডেটা নির্বাচন প্রধানত দুটি পদ্ধতি ব্যবহার করে যোগাযোগ করা হয়:
উপস্থিতি-প্রেক্ষাপট পদ্ধতি : এই পদ্ধতিটি এমন স্থানগুলির তুলনা করে যেখানে একটি নির্দিষ্ট প্রজাতি পর্যবেক্ষণ করা হয়েছে (উপস্থিতি) অন্যান্য অবস্থানের সাথে যেখানে প্রজাতিটি পর্যবেক্ষণ করা হয়নি (পটভূমি)। এখানে, ব্যাকগ্রাউন্ড ডেটা অগত্যা এমন এলাকা বোঝায় না যেখানে প্রজাতির অস্তিত্ব নেই বরং অধ্যয়ন এলাকার সামগ্রিক পরিবেশগত অবস্থার প্রতিফলন করার জন্য সেট আপ করা হয়েছে। এটি উপযুক্ত পরিবেশের পার্থক্য করতে ব্যবহৃত হয় যেখানে প্রজাতিগুলি কম উপযুক্ত পরিবেশ থেকে বিদ্যমান থাকতে পারে।
উপস্থিতি-অনুপস্থিতি পদ্ধতি : এই পদ্ধতিটি এমন অবস্থানগুলির সাথে তুলনা করে যেখানে প্রজাতিটি পর্যবেক্ষণ করা হয়েছে (উপস্থিতি) এমন অবস্থানগুলির সাথে যেখানে এটি নিশ্চিতভাবে পরিলক্ষিত হয়নি (অনুপস্থিতি)। এখানে, অনুপস্থিতির ডেটা নির্দিষ্ট অবস্থানগুলিকে প্রতিনিধিত্ব করে যেখানে প্রজাতির অস্তিত্ব নেই বলে জানা যায়। এটি অধ্যয়ন এলাকার সামগ্রিক পরিবেশগত অবস্থাকে প্রতিফলিত করে না বরং সেই স্থানগুলিকে নির্দেশ করে যেখানে প্রজাতির অস্তিত্ব নেই বলে অনুমান করা হয়।
বাস্তবে, সত্যিকারের অনুপস্থিতির তথ্য সংগ্রহ করা প্রায়ই কঠিন, তাই কৃত্রিমভাবে উত্পন্ন ছদ্ম-অনুপস্থিতির ডেটা প্রায়শই ব্যবহার করা হয়। যাইহোক, এই পদ্ধতির সীমাবদ্ধতা এবং সম্ভাব্য ত্রুটিগুলি স্বীকার করা গুরুত্বপূর্ণ, কারণ কৃত্রিমভাবে উত্পন্ন ছদ্ম-অনুপস্থিতি পয়েন্টগুলি সঠিকভাবে অনুপস্থিতির ক্ষেত্রগুলিকে সঠিকভাবে প্রতিফলিত করতে পারে না।
এই দুটি পদ্ধতির মধ্যে পছন্দ ডেটা প্রাপ্যতা, গবেষণার উদ্দেশ্য, মডেলের নির্ভুলতা এবং নির্ভরযোগ্যতা, সেইসাথে সময় এবং সম্পদের উপর নির্ভর করে। এখানে, আমরা "উপস্থিতি-অনুপস্থিতি" পদ্ধতি ব্যবহার করে মডেলের জন্য GBIF থেকে সংগৃহীত ঘটনা ডেটা এবং কৃত্রিমভাবে তৈরি করা ছদ্ম-অনুপস্থিতি ডেটা ব্যবহার করব।
ছদ্ম-অনুপস্থিতির ডেটা তৈরি করা "পরিবেশগত প্রোফাইলিং পদ্ধতির" মাধ্যমে করা হবে এবং নির্দিষ্ট পদক্ষেপগুলি নিম্নরূপ:
কে-মানে ক্লাস্টারিং ব্যবহার করে পরিবেশগত শ্রেণীবিভাগ: ইউক্লিডীয় দূরত্বের উপর ভিত্তি করে k-মানে ক্লাস্টারিং অ্যালগরিদম, অধ্যয়ন এলাকার মধ্যে পিক্সেলগুলিকে দুটি ক্লাস্টারে ভাগ করতে ব্যবহার করা হবে। একটি ক্লাস্টার এলোমেলোভাবে নির্বাচিত 100টি উপস্থিতি অবস্থানের অনুরূপ পরিবেশগত বৈশিষ্ট্যযুক্ত অঞ্চলগুলিকে প্রতিনিধিত্ব করবে, যখন অন্য ক্লাস্টারটি বিভিন্ন বৈশিষ্ট্যযুক্ত অঞ্চলগুলিকে প্রতিনিধিত্ব করবে।
ভিন্ন ক্লাস্টারগুলির মধ্যে ছদ্ম-অনুপস্থিতি ডেটা তৈরি: প্রথম ধাপে চিহ্নিত দ্বিতীয় ক্লাস্টারের মধ্যে (যা উপস্থিতি ডেটা থেকে ভিন্ন পরিবেশগত বৈশিষ্ট্য রয়েছে), এলোমেলোভাবে উত্পন্ন ছদ্ম-অনুপস্থিতি পয়েন্ট তৈরি করা হবে। এই ছদ্ম-অনুপস্থিতির পয়েন্টগুলি এমন অবস্থানগুলিকে প্রতিনিধিত্ব করবে যেখানে প্রজাতির অস্তিত্বের আশা করা হয় না।
# Randomly select 100 locations for occurrence
pvals = predictors.sampleRegions(
collection=data.randomColumn().sort('random').limit(100),
properties=[],
scale=grain_size
)
# Perform k-means clustering
clusterer = ee.Clusterer.wekaKMeans(
nClusters=2,
distanceFunction="Euclidean"
).train(pvals)
cl_result = predictors.cluster(clusterer)
# Get cluster ID for locations similar to occurrence
cl_id = cl_result.sampleRegions(
collection=data.randomColumn().sort('random').limit(200),
properties=[],
scale=grain_size
)
# Define non-occurrence areas in dissimilar clusters
cl_id = ee.FeatureCollection(cl_id).reduceColumns(ee.Reducer.mode(),['cluster'])
cl_id = ee.Number(cl_id.get('mode')).subtract(1).abs()
cl_mask = cl_result.select(['cluster']).eq(cl_id)
# Presence location mask
presence_mask = data.reduceToImage(properties=['random'],
reducer=ee.Reducer.first()
).reproject('EPSG:4326', None,
grain_size).mask().neq(1).selfMask()
# Masking presence locations in non-occurrence areas and clipping to AOI
area_for_pa = presence_mask.updateMask(cl_mask).clip(aoi)
# Area for Pseudo-absence
Map = geemap.Map(layout={'height':'400px', 'width':'800px'})
Map.addLayer(area_for_pa, {'palette': 'black'}, 'AreaForPA')
Map.centerObject(aoi, 6)
Map
মডেল ফিটিং এবং ভবিষ্যদ্বাণী
আমরা এখন প্রশিক্ষণ ডেটা এবং পরীক্ষার ডেটাতে ডেটা ভাগ করব। প্রশিক্ষণের ডেটা মডেলকে প্রশিক্ষণের মাধ্যমে সর্বোত্তম পরামিতিগুলি খুঁজে পেতে ব্যবহার করা হবে, যখন পরীক্ষার ডেটা আগে থেকে প্রশিক্ষিত মডেলের মূল্যায়ন করতে ব্যবহার করা হবে। এই প্রসঙ্গে বিবেচনা করার জন্য একটি গুরুত্বপূর্ণ ধারণা হল স্থানিক স্বয়ংক্রিয় সম্পর্ক।
স্থানিক স্বয়ংক্রিয় সম্পর্ক হল এসডিএম-এর একটি অপরিহার্য উপাদান, টবলারের আইনের সাথে যুক্ত। এটি এই ধারণাটিকে মূর্ত করে যে "সবকিছু অন্য সবকিছুর সাথে সম্পর্কিত, তবে কাছের জিনিসগুলি দূরের জিনিসগুলির চেয়ে বেশি সম্পর্কিত"। স্থানিক স্বয়ংক্রিয় সম্পর্ক প্রজাতির অবস্থান এবং পরিবেশগত ভেরিয়েবলের মধ্যে উল্লেখযোগ্য সম্পর্ক উপস্থাপন করে। যাইহোক, যদি প্রশিক্ষণ এবং পরীক্ষার ডেটার মধ্যে স্থানিক স্বয়ংক্রিয় সম্পর্ক বিদ্যমান থাকে তবে দুটি ডেটা সেটের মধ্যে স্বাধীনতা আপস করা যেতে পারে। এটি মডেলের সাধারণীকরণ ক্ষমতার মূল্যায়নকে উল্লেখযোগ্যভাবে প্রভাবিত করে।
এই সমস্যাটির সমাধান করার একটি পদ্ধতি হল স্থানিক ব্লক ক্রস-ভ্যালিডেশন কৌশল, যার মধ্যে ডেটাকে প্রশিক্ষণ এবং ডেটাসেটে পরীক্ষা করা জড়িত। এই কৌশলটি একাধিক ব্লকে ডেটা ভাগ করে, প্রতিটি ব্লককে স্বতন্ত্রভাবে প্রশিক্ষণ হিসাবে ব্যবহার করে এবং স্থানিক স্বয়ংক্রিয় সম্পর্কের প্রভাব কমাতে ডেটাসেট পরীক্ষা করে। এটি ডেটাসেটের মধ্যে স্বাধীনতা বাড়ায়, মডেলের সাধারণীকরণ ক্ষমতার আরও সঠিক মূল্যায়নের অনুমতি দেয়।
নির্দিষ্ট পদ্ধতি নিম্নরূপ:
- স্থানিক ব্লক তৈরি: সমগ্র ডেটাসেটকে সমান আকারের স্থানিক ব্লকে ভাগ করুন (যেমন, 50x50 কিমি)।
- প্রশিক্ষণ এবং পরীক্ষার সেটের বরাদ্দ: প্রতিটি স্থানিক ব্লক এলোমেলোভাবে প্রশিক্ষণ সেট (70%) বা পরীক্ষা সেট (30%) এর জন্য নির্ধারিত হয়। এটি মডেলটিকে নির্দিষ্ট এলাকা থেকে ডেটা ওভারফিটিং থেকে বাধা দেয় এবং আরও সাধারণ ফলাফল অর্জনের লক্ষ্য রাখে।
- পুনরাবৃত্তিমূলক ক্রস-বৈধকরণ: পুরো প্রক্রিয়াটি n বার পুনরাবৃত্তি হয় (যেমন, 10 বার)। প্রতিটি পুনরাবৃত্তিতে, ব্লকগুলি এলোমেলোভাবে প্রশিক্ষণ এবং পরীক্ষা সেটে বিভক্ত করা হয়, যা মডেলের স্থায়িত্ব এবং নির্ভরযোগ্যতা উন্নত করার উদ্দেশ্যে করা হয়।
- ছদ্ম-অনুপস্থিতি ডেটা তৈরি: প্রতিটি পুনরাবৃত্তিতে, ছদ্ম-অনুপস্থিতির ডেটা এলোমেলোভাবে মডেলের কার্যকারিতা মূল্যায়ন করার জন্য তৈরি করা হয়।
Scale = 50000
grid = watermask.reduceRegions(
collection=aoi.coveringGrid(scale=Scale, proj='EPSG:4326'),
reducer=ee.Reducer.mean()).filter(ee.Filter.neq('mean', None))
Map = geemap.Map(layout={'height':'400px', 'width':'800px'})
Map.addLayer(grid, {}, "Grid for spatial block cross validation")
Map.addLayer(outline, {'palette': 'FF0000'}, "Study Area")
Map.centerObject(aoi, 6)
Map
এখন আমরা মডেল ফিট করতে পারেন. একটি মডেল ফিট করার জন্য ডেটার প্যাটার্নগুলি বোঝা এবং সেই অনুযায়ী মডেলের প্যারামিটারগুলি (ওজন এবং পক্ষপাত) সামঞ্জস্য করা জড়িত। এই প্রক্রিয়াটি মডেলটিকে নতুন ডেটা সহ উপস্থাপিত হলে আরও সঠিক ভবিষ্যদ্বাণী করতে সক্ষম করে। এই উদ্দেশ্যে, আমরা মডেলের সাথে মানানসই করার জন্য SDM() নামে একটি ফাংশন সংজ্ঞায়িত করেছি।
আমরা Random Forest অ্যালগরিদম ব্যবহার করব।
def sdm(x):
seed = ee.Number(x)
# Random block division for training and validation
rand_blk = ee.FeatureCollection(grid).randomColumn(seed=seed).sort("random")
training_grid = rand_blk.filter(ee.Filter.lt("random", split)) # Grid for training
testing_grid = rand_blk.filter(ee.Filter.gte("random", split)) # Grid for testing
# Presence points
presence_points = ee.FeatureCollection(data)
presence_points = presence_points.map(lambda feature: feature.set("PresAbs", 1))
tr_presence_points = presence_points.filter(
ee.Filter.bounds(training_grid)
) # Presence points for training
te_presence_points = presence_points.filter(
ee.Filter.bounds(testing_grid)
) # Presence points for testing
# Pseudo-absence points for training
tr_pseudo_abs_points = area_for_pa.sample(
region=training_grid,
scale=grain_size,
numPixels=tr_presence_points.size().add(300),
seed=seed,
geometries=True,
)
# Same number of pseudo-absence points as presence points for training
tr_pseudo_abs_points = (
tr_pseudo_abs_points.randomColumn()
.sort("random")
.limit(ee.Number(tr_presence_points.size()))
)
tr_pseudo_abs_points = tr_pseudo_abs_points.map(lambda feature: feature.set("PresAbs", 0))
te_pseudo_abs_points = area_for_pa.sample(
region=testing_grid,
scale=grain_size,
numPixels=te_presence_points.size().add(100),
seed=seed,
geometries=True,
)
# Same number of pseudo-absence points as presence points for testing
te_pseudo_abs_points = (
te_pseudo_abs_points.randomColumn()
.sort("random")
.limit(ee.Number(te_presence_points.size()))
)
te_pseudo_abs_points = te_pseudo_abs_points.map(lambda feature: feature.set("PresAbs", 0))
# Merge training and pseudo-absence points
training_partition = tr_presence_points.merge(tr_pseudo_abs_points)
testing_partition = te_presence_points.merge(te_pseudo_abs_points)
# Extract predictor variable values at training points
train_pvals = predictors.sampleRegions(
collection=training_partition,
properties=["PresAbs"],
scale=grain_size,
geometries=True,
)
# Random Forest classifier
classifier = ee.Classifier.smileRandomForest(
numberOfTrees=500,
variablesPerSplit=None,
minLeafPopulation=10,
bagFraction=0.5,
maxNodes=None,
seed=seed,
)
# Presence probability: Habitat suitability map
classifier_pr = classifier.setOutputMode("PROBABILITY").train(
train_pvals, "PresAbs", bands
)
classified_img_pr = predictors.select(bands).classify(classifier_pr)
# Binary presence/absence map: Potential distribution map
classifier_bin = classifier.setOutputMode("CLASSIFICATION").train(
train_pvals, "PresAbs", bands
)
classified_img_bin = predictors.select(bands).classify(classifier_bin)
return [
classified_img_pr,
classified_img_bin,
training_partition,
testing_partition,
], classifier_pr
স্থানিক ব্লকগুলি যথাক্রমে মডেল প্রশিক্ষণের জন্য 70% এবং মডেল পরীক্ষার জন্য 30% ভাগে বিভক্ত। ছদ্ম-অনুপস্থিতির ডেটা এলোমেলোভাবে প্রতিটি প্রশিক্ষণ এবং প্রতিটি পুনরাবৃত্তিতে সেট করা পরীক্ষার মধ্যে তৈরি হয়। ফলস্বরূপ, প্রতিটি এক্সিকিউশন মডেল প্রশিক্ষণ এবং পরীক্ষার জন্য উপস্থিতি এবং ছদ্ম-অনুপস্থিতির বিভিন্ন সেট প্রদান করে।
split = 0.7
numiter = 10
# Random Seed
runif = lambda length: [random.randint(1, 1000) for _ in range(length)]
items = runif(numiter)
# Fixed seed
# items = [287, 288, 553, 226, 151, 255, 902, 267, 419, 538]
results_list = [] # Initialize SDM results list
importances_list = [] # Initialize variable importance list
for item in items:
result, trained = sdm(item)
# Accumulate SDM results into the list
results_list.extend(result)
# Accumulate variable importance into the list
importance = ee.Dictionary(trained.explain()).get('importance')
importances_list.extend(importance.getInfo().items())
# Flatten the SDM results list
results = ee.List(results_list).flatten()
এখন আমরা পরী পিট্টার জন্য বাসস্থানের উপযুক্ততার মানচিত্র এবং সম্ভাব্য বিতরণ মানচিত্রটি কল্পনা করতে পারি। এই ক্ষেত্রে, বাসস্থানের উপযুক্ততা মানচিত্রটি mean() ফাংশন ব্যবহার করে তৈরি করা হয় সমস্ত চিত্র জুড়ে প্রতিটি পিক্সেল অবস্থানের গড় গণনা করার জন্য, এবং সম্ভাব্য বন্টন মানচিত্রটি mode() ফাংশন ব্যবহার করে তৈরি করা হয় সর্বাধিক ঘন ঘন ঘটতে থাকা মান নির্ধারণ করতে। সমস্ত ছবি জুড়ে প্রতিটি পিক্সেল অবস্থানে।
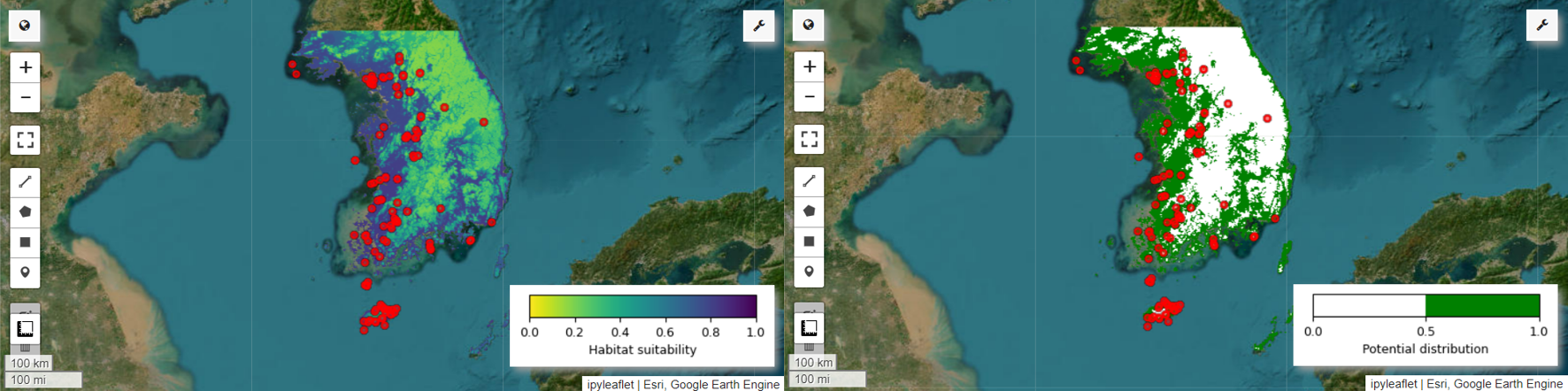
# Habitat suitability map
images = ee.List.sequence(
0, ee.Number(numiter).multiply(4).subtract(1), 4).map(
lambda x: results.get(x))
model_average = ee.ImageCollection.fromImages(images).mean()
Map = geemap.Map(layout={'height':'400px', 'width':'800px'}, basemap='Esri.WorldImagery')
vis_params = {
'min': 0,
'max': 1,
'palette': cm.palettes.viridis_r}
Map.addLayer(model_average, vis_params, 'Habitat suitability')
Map.add_colorbar(vis_params, label="Habitat suitability",
orientation="horizontal",
layer_name="Habitat suitability")
Map.addLayer(data, {'color':'red'}, 'Presence')
Map.centerObject(aoi, 6)
Map
# Potential distribution map
images2 = ee.List.sequence(1, ee.Number(numiter).multiply(4).subtract(1), 4).map(
lambda x: results.get(x)
)
distribution_map = ee.ImageCollection.fromImages(images2).mode()
Map = geemap.Map(
layout={"height": "400px", "width": "800px"}, basemap="Esri.WorldImagery"
)
vis_params = {"min": 0, "max": 1, "palette": ["white", "green"]}
Map.addLayer(distribution_map, vis_params, "Potential distribution")
Map.addLayer(data, {"color": "red"}, "Presence")
Map.add_colorbar(
vis_params,
label="Potential distribution",
discrete=True,
orientation="horizontal",
layer_name="Potential distribution",
)
Map.centerObject(data.geometry(), 6)
Map
পরিবর্তনশীল গুরুত্ব এবং নির্ভুলতা মূল্যায়ন
র্যান্ডম ফরেস্ট ( ee.Classifier.smileRandomForest ) হল এক ধরনের শেখার পদ্ধতি, যা ভবিষ্যদ্বাণী করার জন্য একাধিক সিদ্ধান্ত গাছ তৈরি করে কাজ করে। প্রতিটি সিদ্ধান্ত গাছ স্বাধীনভাবে ডেটার বিভিন্ন উপসেট থেকে শেখে, এবং তাদের ফলাফল আরও সঠিক এবং স্থিতিশীল ভবিষ্যদ্বাণী সক্ষম করার জন্য একত্রিত করা হয়।
পরিবর্তনশীল গুরুত্ব হল একটি পরিমাপ যা র্যান্ডম ফরেস্ট মডেলের মধ্যে ভবিষ্যদ্বাণীগুলির উপর প্রতিটি ভেরিয়েবলের প্রভাবকে মূল্যায়ন করে। গড় পরিবর্তনশীল গুরুত্ব গণনা এবং মুদ্রণ করতে আমরা পূর্বে সংজ্ঞায়িত importances_list ব্যবহার করব।
def plot_variable_importance(importances_list):
# Extract each variable importance value into a list
variables = [item[0] for item in importances_list]
importances = [item[1] for item in importances_list]
# Calculate the average importance for each variable
average_importances = {}
for variable in set(variables):
indices = [i for i, var in enumerate(variables) if var == variable]
average_importance = np.mean([importances[i] for i in indices])
average_importances[variable] = average_importance
# Sort the importances in descending order of importance
sorted_importances = sorted(average_importances.items(),
key=lambda x: x[1], reverse=False)
variables = [item[0] for item in sorted_importances]
avg_importances = [item[1] for item in sorted_importances]
# Adjust the graph size
plt.figure(figsize=(8, 4))
# Plot the average importance as a horizontal bar chart
plt.barh(variables, avg_importances)
plt.xlabel('Importance')
plt.ylabel('Variables')
plt.title('Average Variable Importance')
# Display values above the bars
for i, v in enumerate(avg_importances):
plt.text(v + 0.02, i, f"{v:.2f}", va='center')
# Adjust the x-axis range
plt.xlim(0, max(avg_importances) + 5) # Adjust to the desired range
plt.tight_layout()
plt.savefig('variable_importance.png')
plt.show()
plot_variable_importance(importances_list)
টেস্টিং ডেটাসেট ব্যবহার করে, আমরা প্রতিটি রানের জন্য AUC-ROC এবং AUC-PR গণনা করি। তারপর, আমরা n পুনরাবৃত্তির উপর গড় AUC-ROC এবং AUC-PR গণনা করি।
AUC-ROC 'সংবেদনশীলতা (রিকল) বনাম 1-স্পেসিফিসিটি' গ্রাফের বক্ররেখার অধীন এলাকাকে প্রতিনিধিত্ব করে, থ্রেশহোল্ড পরিবর্তনের সাথে সাথে সংবেদনশীলতা এবং নির্দিষ্টতার মধ্যে সম্পর্ককে চিত্রিত করে। নির্দিষ্টতা সমস্ত পর্যবেক্ষিত অ-ঘটনার উপর ভিত্তি করে। অতএব, AUC-ROC বিভ্রান্তি ম্যাট্রিক্সের সমস্ত চতুর্ভুজকে অন্তর্ভুক্ত করে।
AUC-PR 'প্রিসিশন বনাম রিকল (সংবেদনশীলতা)' গ্রাফের বক্ররেখার নিচের এলাকাকে প্রতিনিধিত্ব করে, থ্রেশহোল্ড পরিবর্তিত হওয়ার সাথে সাথে নির্ভুলতা এবং রিকলের মধ্যে সম্পর্ক দেখায়। নির্ভুলতা সমস্ত পূর্বাভাসিত ঘটনার উপর ভিত্তি করে। তাই, AUC-PR প্রকৃত নেতিবাচক (TN) অন্তর্ভুক্ত করে না।
def print_pres_abs_sizes(TestingDatasets, numiter):
# Check and print the sizes of presence and pseudo-absence coordinates
def get_pres_abs_size(x):
fc = ee.FeatureCollection(TestingDatasets.get(x))
presence_size = fc.filter(ee.Filter.eq("PresAbs", 1)).size()
pseudo_absence_size = fc.filter(ee.Filter.eq("PresAbs", 0)).size()
return ee.List([presence_size, pseudo_absence_size])
sizes_info = (
ee.List.sequence(0, ee.Number(numiter).subtract(1), 1)
.map(get_pres_abs_size)
.getInfo()
)
for i, sizes in enumerate(sizes_info):
presence_size = sizes[0]
pseudo_absence_size = sizes[1]
print(
f"Iteration {i + 1}: Presence Size = {presence_size}, Pseudo-absence Size = {pseudo_absence_size}"
)
# Extracting the Testing Datasets
testing_datasets = ee.List.sequence(
3, ee.Number(numiter).multiply(4).subtract(1), 4
).map(lambda x: results.get(x))
print_pres_abs_sizes(testing_datasets, numiter)
def get_acc(hsm, t_data, grain_size):
pr_prob_vals = hsm.sampleRegions(
collection=t_data, properties=["PresAbs"], scale=grain_size
)
seq = ee.List.sequence(start=0, end=1, count=25) # Divide 0 to 1 into 25 intervals
def calculate_metrics(cutoff):
# Each element of the seq list is passed as cutoff(threshold value)
# Observed present = TP + FN
pres = pr_prob_vals.filterMetadata("PresAbs", "equals", 1)
# TP (True Positive)
tp = ee.Number(
pres.filterMetadata("classification", "greater_than", cutoff).size()
)
# TPR (True Positive Rate) = Recall = Sensitivity = TP / (TP + FN) = TP / Observed present
tpr = tp.divide(pres.size())
# Observed absent = FP + TN
abs = pr_prob_vals.filterMetadata("PresAbs", "equals", 0)
# FN (False Negative)
fn = ee.Number(
pres.filterMetadata("classification", "less_than", cutoff).size()
)
# TNR (True Negative Rate) = Specificity = TN / (FP + TN) = TN / Observed absent
tn = ee.Number(abs.filterMetadata("classification", "less_than", cutoff).size())
tnr = tn.divide(abs.size())
# FP (False Positive)
fp = ee.Number(
abs.filterMetadata("classification", "greater_than", cutoff).size()
)
# FPR (False Positive Rate) = FP / (FP + TN) = FP / Observed absent
fpr = fp.divide(abs.size())
# Precision = TP / (TP + FP) = TP / Predicted present
precision = tp.divide(tp.add(fp))
# SUMSS = SUM of Sensitivity and Specificity
sumss = tpr.add(tnr)
return ee.Feature(
None,
{
"cutoff": cutoff,
"TP": tp,
"TN": tn,
"FP": fp,
"FN": fn,
"TPR": tpr,
"TNR": tnr,
"FPR": fpr,
"Precision": precision,
"SUMSS": sumss,
},
)
return ee.FeatureCollection(seq.map(calculate_metrics))
def calculate_and_print_auc_metrics(images, testing_datasets, grain_size, numiter):
# Calculate AUC-ROC and AUC-PR
def calculate_auc_metrics(x):
hsm = ee.Image(images.get(x))
t_data = ee.FeatureCollection(testing_datasets.get(x))
acc = get_acc(hsm, t_data, grain_size)
# Calculate AUC-ROC
x = ee.Array(acc.aggregate_array("FPR"))
y = ee.Array(acc.aggregate_array("TPR"))
x1 = x.slice(0, 1).subtract(x.slice(0, 0, -1))
y1 = y.slice(0, 1).add(y.slice(0, 0, -1))
auc_roc = x1.multiply(y1).multiply(0.5).reduce("sum", [0]).abs().toList().get(0)
# Calculate AUC-PR
x = ee.Array(acc.aggregate_array("TPR"))
y = ee.Array(acc.aggregate_array("Precision"))
x1 = x.slice(0, 1).subtract(x.slice(0, 0, -1))
y1 = y.slice(0, 1).add(y.slice(0, 0, -1))
auc_pr = x1.multiply(y1).multiply(0.5).reduce("sum", [0]).abs().toList().get(0)
return (auc_roc, auc_pr)
auc_metrics = (
ee.List.sequence(0, ee.Number(numiter).subtract(1), 1)
.map(calculate_auc_metrics)
.getInfo()
)
# Print AUC-ROC and AUC-PR for each iteration
df = pd.DataFrame(auc_metrics, columns=["AUC-ROC", "AUC-PR"])
df.index = [f"Iteration {i + 1}" for i in range(len(df))]
df.to_csv("auc_metrics.csv", index_label="Iteration")
print(df)
# Calculate mean and standard deviation of AUC-ROC and AUC-PR
mean_auc_roc, std_auc_roc = df["AUC-ROC"].mean(), df["AUC-ROC"].std()
mean_auc_pr, std_auc_pr = df["AUC-PR"].mean(), df["AUC-PR"].std()
print(f"Mean AUC-ROC = {mean_auc_roc:.4f} ± {std_auc_roc:.4f}")
print(f"Mean AUC-PR = {mean_auc_pr:.4f} ± {std_auc_pr:.4f}")
%%time
# Calculate AUC-ROC and AUC-PR
calculate_and_print_auc_metrics(images, testing_datasets, grain_size, numiter)
এই টিউটোরিয়ালটি স্পিসিস ডিস্ট্রিবিউশন মডেলিং (SDM) এর জন্য Google আর্থ ইঞ্জিন (GEE) ব্যবহার করার একটি বাস্তব উদাহরণ প্রদান করেছে। এসডিএম-এর ক্ষেত্রে জিইই-এর বহুমুখীতা এবং নমনীয়তা একটি গুরুত্বপূর্ণ উপায়। আর্থ ইঞ্জিনের শক্তিশালী ভূ-স্থানিক ডেটা প্রসেসিং ক্ষমতার ব্যবহার গবেষক এবং সংরক্ষণবাদীদের জন্য আমাদের গ্রহে জীববৈচিত্র্য বোঝা ও সংরক্ষণ করার জন্য অফুরন্ত সম্ভাবনার দ্বার উন্মোচন করে। এই টিউটোরিয়াল থেকে প্রাপ্ত জ্ঞান এবং দক্ষতা প্রয়োগ করে, ব্যক্তিরা পরিবেশগত গবেষণার এই আকর্ষণীয় ক্ষেত্রে অন্বেষণ এবং অবদান রাখতে পারে।