Da das Clustering nicht überwacht wird, ist keine „Wahrheit“ verfügbar, um Ergebnisse zu überprüfen. Die fehlende Bewertung der Qualität erschwert die Qualitätsbewertung. Darüber hinaus fallen reale Datasets in der Regel nicht in offensichtliche Cluster von Beispielen wie dem in Abbildung 1 gezeigten Dataset.
Leider ähneln reale Daten Abbildung 2, was die visuelle Bewertung der Clusterqualität erschwert.
Im Flussdiagramm wird zusammengefasst, wie Sie die Qualität Ihres Clusters prüfen. Die Zusammenfassung wird in den folgenden Abschnitten ausführlicher erläutert.

Schritt 1: Clustering-Qualität
Die Prüfung der Clustering-Qualität ist kein strenger Prozess, da das Clustering keine wahrheitsgemäßen Informationen enthält. Im Folgenden finden Sie Richtlinien, die Sie iterativ anwenden können, um die Clustering-Qualität zu verbessern.
Führen Sie zuerst eine visuelle Prüfung durch, um sicherzustellen, dass die Cluster wie erwartet aussehen und Beispiele, die Ihnen ähnlich sind, im selben Cluster angezeigt werden. Sehen Sie sich dann diese häufig verwendeten Messwerte an, wie in den folgenden Abschnitten beschrieben:
- Clusterkardinalität
- Clustergröße
- Leistung des nachgelagerten Systems
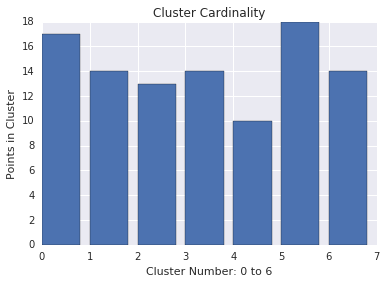
Clusterkardinalität
Die Clusterkardinalität ist die Anzahl der Beispiele pro Cluster. Stellen Sie die Clusterkardinalität für alle Cluster dar und untersuchen Sie Cluster, die größere Ausreißer sind. Untersuchen Sie beispielsweise in Abbildung 2 die Clusternummer 5.
Clustergröße
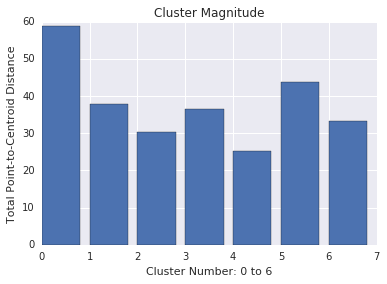
Die Clustergröße ist die Summe der Entfernungen von allen Beispielen zum Schwerpunkt des Clusters. Ähnlich wie bei Kardinalität sollten Sie auch prüfen, wie stark diese Schwankungen in den Clustern sind, und Anomalien untersuchen. Untersuchen Sie beispielsweise in Abbildung 3 die Clusternummer 0.
Magnitude vs. Kardinalität
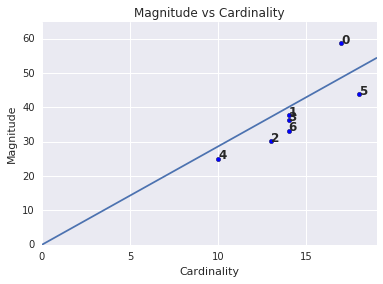
Eine höhere Clusterkardinalität führt tendenziell zu einer höheren Clusterintensität, was intuitiv sinnvoll ist. Cluster sind anomal, wenn die Kardinalität im Verhältnis zu den anderen Clustern nicht zum Ausmaß passt. Ermitteln Sie anomale Cluster, indem Sie die Größenordnung mit der Kardinalität vergleichen. In Abbildung 4 zeigt beispielsweise das Anpassen einer Linie an die Clustermesswerte, dass die Clusternummer 0 anomal ist.
Leistung des nachgelagerten Systems
Da die Clustering-Ausgabe häufig in nachgelagerten ML-Systemen verwendet wird, sollten Sie prüfen, ob sich die Leistung des nachgelagerten Systems verbessert, wenn sich der Clustering-Prozess ändert. Die Auswirkungen auf die nachgelagerte Leistung bieten einen realen Test für die Qualität Ihres Clusters. Der Nachteil besteht darin, dass diese Prüfung komplex ist.
Fragen, die untersucht werden müssen, wenn Probleme gefunden werden
Wenn Sie Probleme feststellen, prüfen Sie die Datenvorbereitung und die Ähnlichkeitsmessung. Stellen Sie sich dabei die folgenden Fragen:
- Werden Ihre Daten skaliert?
- Ist die Ähnlichkeitsmessung korrekt?
- Führt der Algorithmus semantisch aussagekräftige Vorgänge für die Daten aus?
- Stimmen die Annahmen Ihres Algorithmus mit den Daten überein?
Schritt 2: Leistung der Ähnlichkeitsmessung
Ihr Clustering-Algorithmus ist nur so gut wie Ihr Ähnlichkeitsmesswert. Achte darauf, dass deine Ähnlichkeitsmessung aussagekräftige Ergebnisse liefert. Am einfachsten ist es, zwei Paare von Beispielen zu identifizieren, die bekanntermaßen mehr oder weniger ähnlich sind. Berechnen Sie dann die Ähnlichkeitsmessung für jedes Beispielpaar. Achten Sie darauf, dass die Ähnlichkeitsmessung für ähnliche Beispiele höher ist als die für weniger ähnliche.
Die Beispiele, mit denen Sie die Ähnlichkeitsmessung ermitteln, sollten dem Dataset entsprechen. Achten Sie darauf, dass die Ähnlichkeitsmessung für alle Ihre Beispiele gilt. Eine sorgfältige Überprüfung stellt sicher, dass Ihre Ähnlichkeitsmessung im Dataset konsistent ist, egal ob manuell oder überwacht. Wenn die Ähnlichkeitsmessung für einige Beispiele nicht konsistent ist, werden diese nicht geclustert.
Wenn Sie Beispiele mit ungenauen Ähnlichkeiten finden, werden mit der Ähnlichkeitsmessung wahrscheinlich nicht die Featuredaten erfasst, die diese Beispiele unterscheiden. Experimentieren Sie mit Ihrer Ähnlichkeitsmessung und ermitteln Sie, ob Sie genauere Ähnlichkeiten erhalten.
Schritt 3: Optimale Anzahl von Clustern
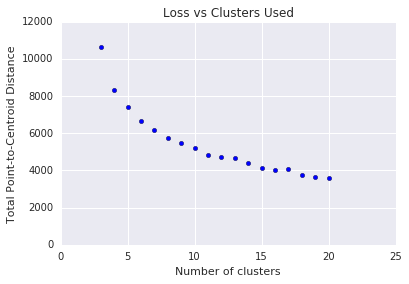
Für k-means müssen Sie die Anzahl der Cluster \(k\) vorher entscheiden. Wie wird der optimale Wert von \(k\)ermittelt? Führen Sie den Algorithmus zum Erhöhen \(k\) aus und notieren Sie sich die Summe der Clustergrößen. Mit zunehmender \(k\)Anzahl werden die Cluster kleiner und die Gesamtentfernung nimmt ab. Ordnen Sie diese Entfernung der Anzahl der Cluster zu.
Wie in Abbildung 4 gezeigt, nimmt die Verringerung des Verlusts bei einer bestimmten \(k\)mit zunehmender \(k\)ab. Mathematisch gesehen entspricht dies ungefähr der \(k\)Kurve, die sich über -1 (\(\theta > 135^{\circ}\)) erstreckt. In dieser Richtlinie ist kein genauer Wert für das Optimum angegeben \(k\) , sondern nur ein ungefährer Wert. Für das gezeigte Diagramm beträgt das Optimum \(k\) ungefähr 11. Wenn Sie detailliertere Cluster bevorzugen, können Sie anhand dieses Diagramms eine höhere \(k\) auswählen.