이전 섹션에서는 모두 한 번에 계산된 모델 측정항목 집합을 제시했습니다. 단일 분류 임곗값입니다. 그러나 '주목하는 방법'을 모델의 품질을 개선하는 데 도움이 되므로 다양한 도구가 필요합니다.
수신자 조작 특성 곡선 (ROC)
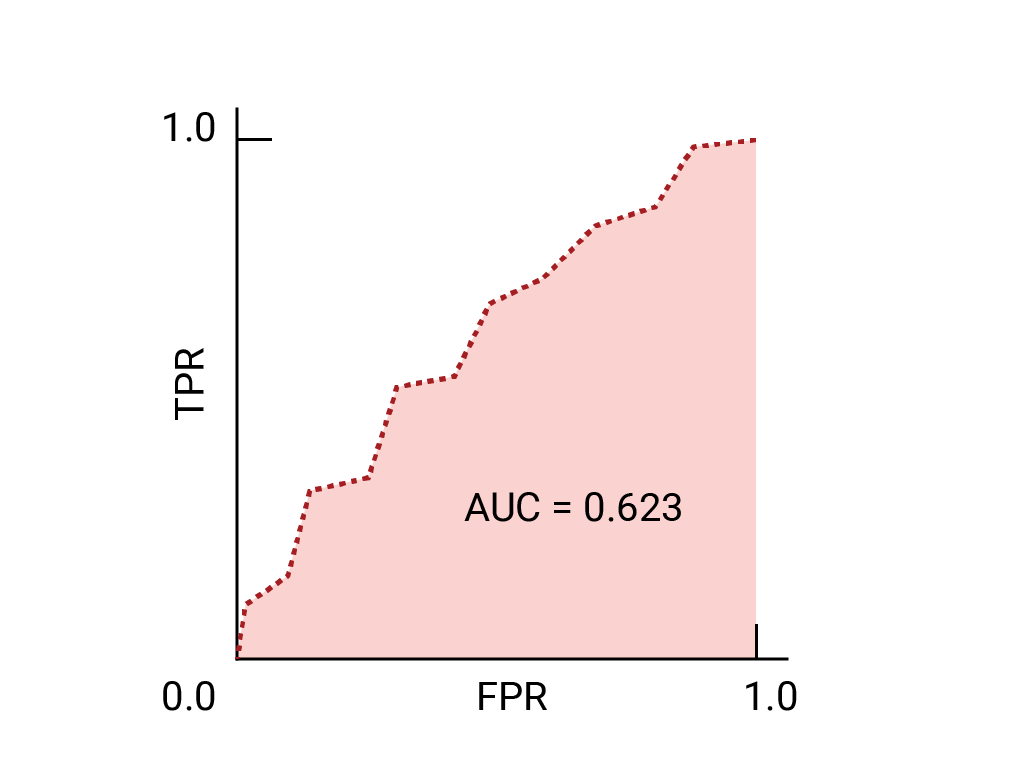
ROC 곡선 모든 임곗값의 모델 성능을 시각적으로 나타낸 것입니다. 긴 버전의 이름, 수신자 조작 특성은 탐지하기 시작했습니다.
ROC 곡선은 참양성률 (TPR)을 계산하여 그립니다. 거짓양성률(FPR)과 거짓양성률을 선택한 간격), 그런 다음 FPR을 통해 TPR을 그래프로 표시합니다. 완벽한 모델은 일부 임곗값에서 TPR이 1.0이고 FPR이 0.0인 경우 점 또는 경계선의 (0, 1) 다른 모든 임곗값이 무시되거나 다음에 의해 무시되는 경우:
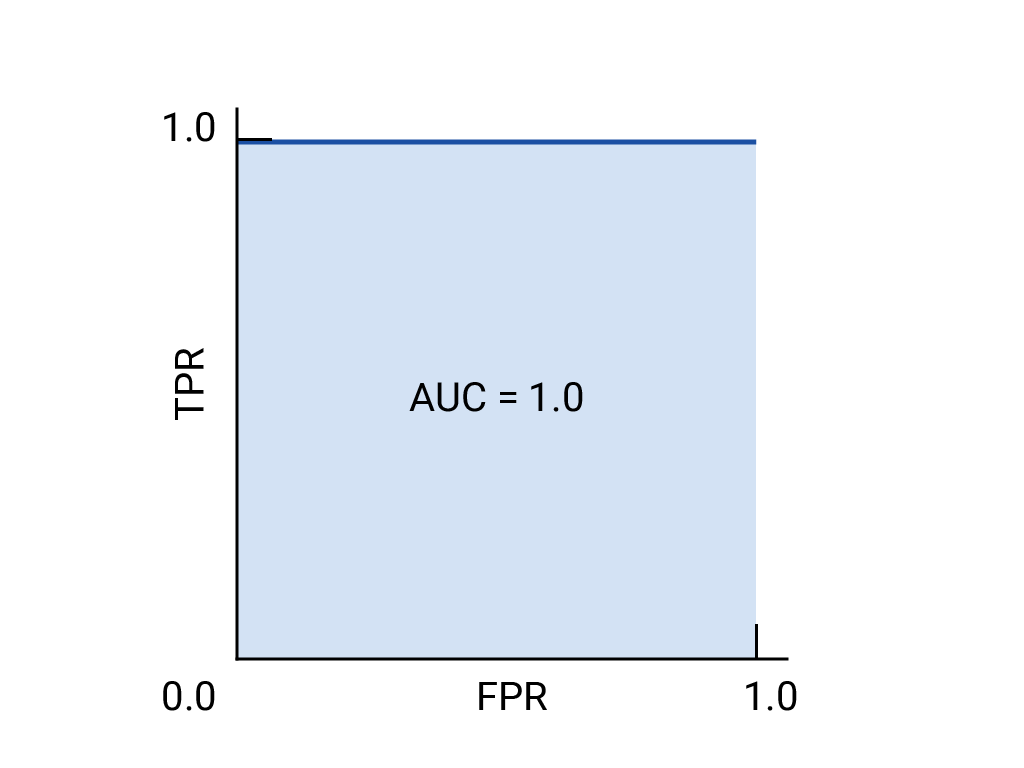
곡선 아래 면적 (AUC)
ROC 곡선 아래 영역 (AUC) 모델이 '양성'과 '음수' 예가 무작위로 선정된 경우 확인할 수 있습니다
변의 길이가 1인 정사각형을 포함하는 위의 완벽한 모델은 변이 1인 경우 1.0의 곡선 아래 면적 다시 말해 100% 오류가 발생할 모델이 무작위로 선택된 양성 예제의 순위를 무작위로 선택한 부정적인 예입니다. 다시 말해, 퍼블릭 클라우드의 확산을 AUC는 모델이 특정 의자를 배치할 확률을 제곱과 관계없이 무작위로 선택된 원의 오른쪽에 있는 임곗값을 설정합니다

좀 더 구체적으로 말하면 AUC를 사용하는 스팸 분류기 항상 무작위로 스팸 이메일이 스팸일 수 있습니다. 각 포드의 실제 분류는 선택하는 임계값에 따라 달라집니다.
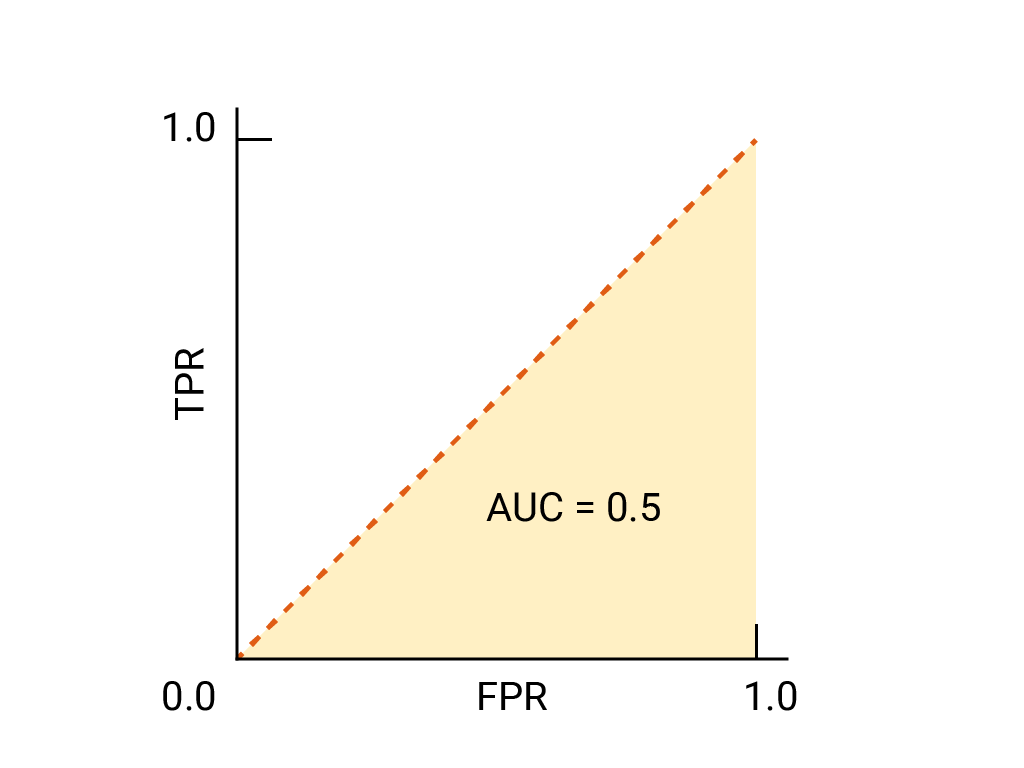
이진 분류기의 경우, 임의의 추측과 정확하게 일치하는 모델 또는 동전 던지기에는 (0,0)에서 (1,1)까지의 대각선인 ROC가 있습니다. AUC는 0.5로, 임의의 양성 예측과 제외 예시.
스팸 분류기 예에서 AUC가 0.5인 스팸 분류기는 임의의 스팸 이메일보다 스팸일 확률이 더 높은 이메일 스팸이 아닌 이메일의 경우
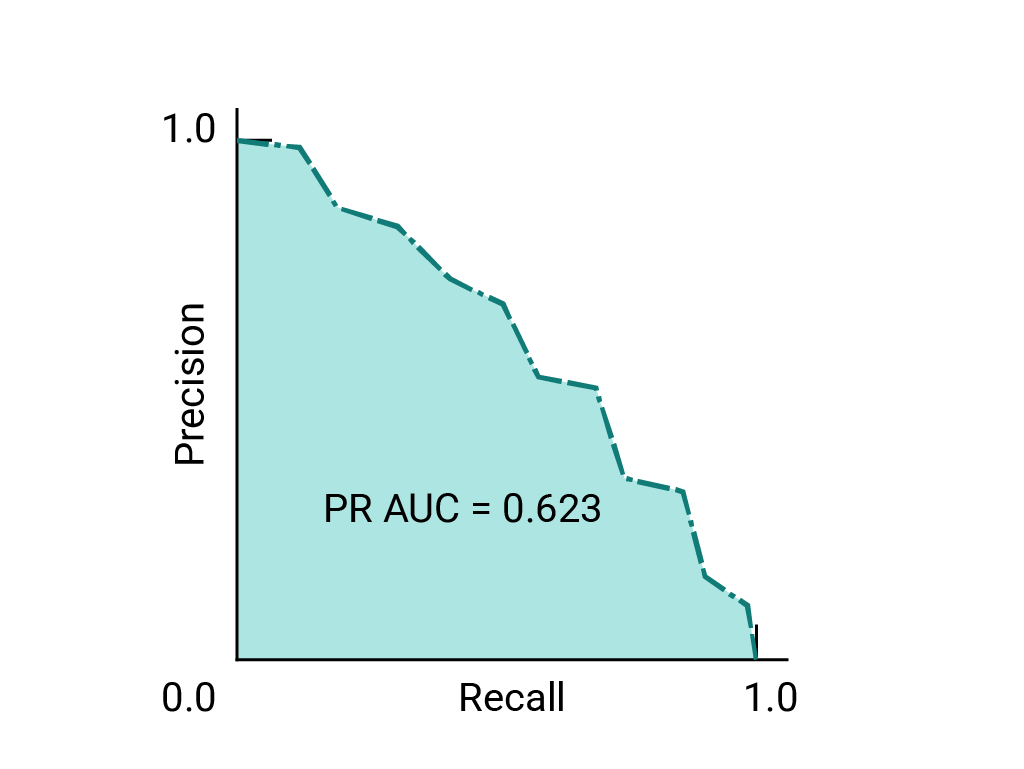
(선택사항, 고급) 정밀도-재현율 곡선
AUC 및 ROC는 데이터 세트가 대략 클래스 간 균형을 유지합니다. 데이터 세트의 균형이 맞지 않는 경우 정밀도-재현율은 더 나은 비교 결과를 제공할 수 있는데, 모델 성능을 시각화합니다 정밀도-재현율 곡선은 다음에 의해 생성됩니다. y축에 정밀도를 표시하고 x축에 재현율을 표시 있습니다
모델 및 임곗값 선택을 위한 AUC 및 ROC
AUC는 서로 다른 두 모델의 실적을 비교하는 데 유용한 데이터 세트가 대략적으로 균형을 이루고 있는 한 데이터를 집계할 수 있습니다 (정밀도-재현율 곡선 참고, (불균형 데이터 세트의 경우) 아래 영역이 더 큰 모델 일반적으로 곡선이 더 좋습니다.
<ph type="x-smartling-placeholder">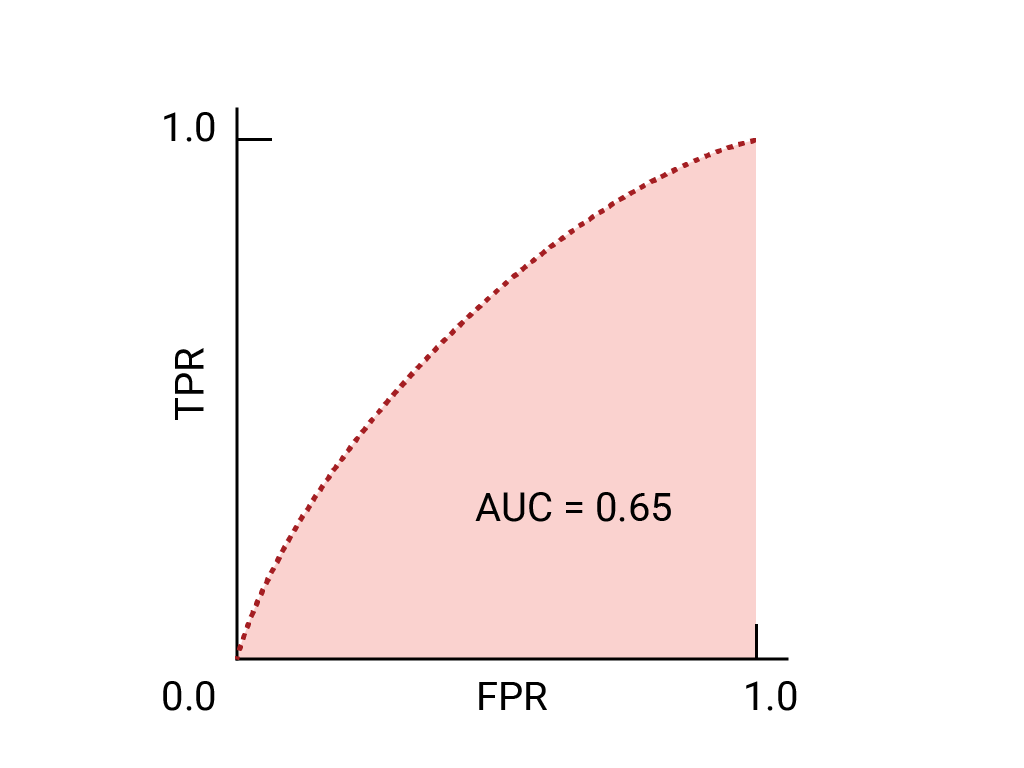 <ph type="x-smartling-placeholder">
<ph type="x-smartling-placeholder">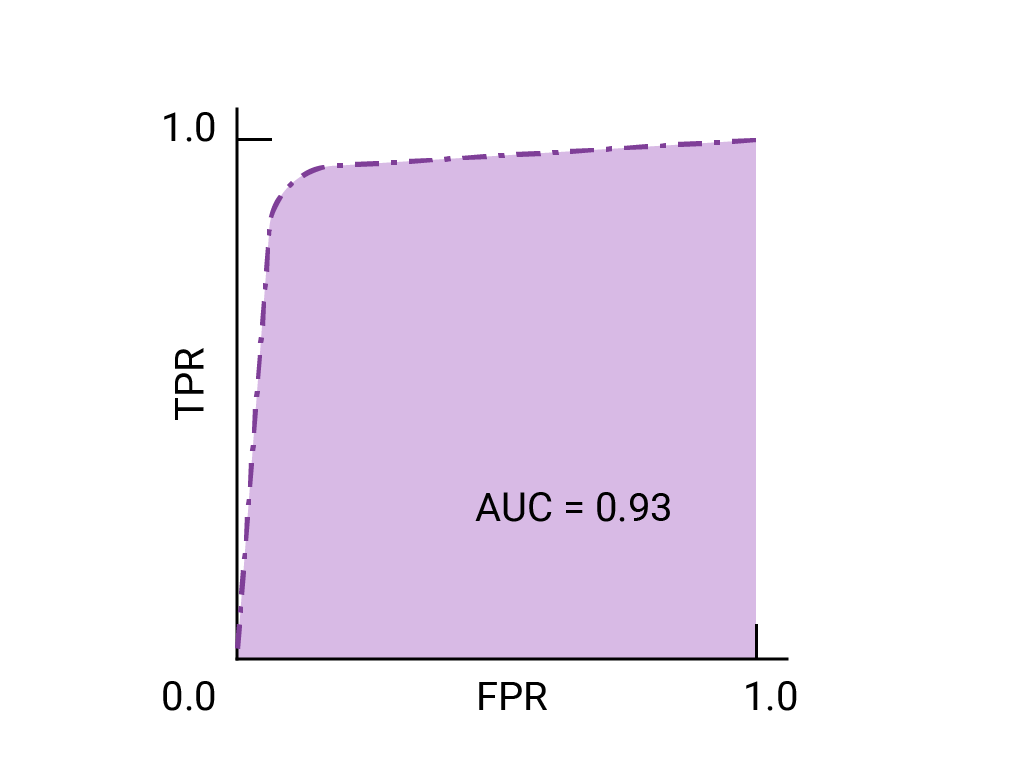 </ph>
</ph>
(0,1)에 가장 가까운 ROC 곡선상의 점들은 가장 높은 성능을 보이는 임곗값입니다. 앞서 말씀드린 것처럼 기준점, 혼동 행렬 및 측정항목 선택 및 절충점 선택하는 임계값이 가장 중요한 측정항목을 기준으로 구체적인 사용 사례를 알아보겠습니다 다음에서 점 A, B, C를 고려하세요. 각각 임곗값을 나타냄
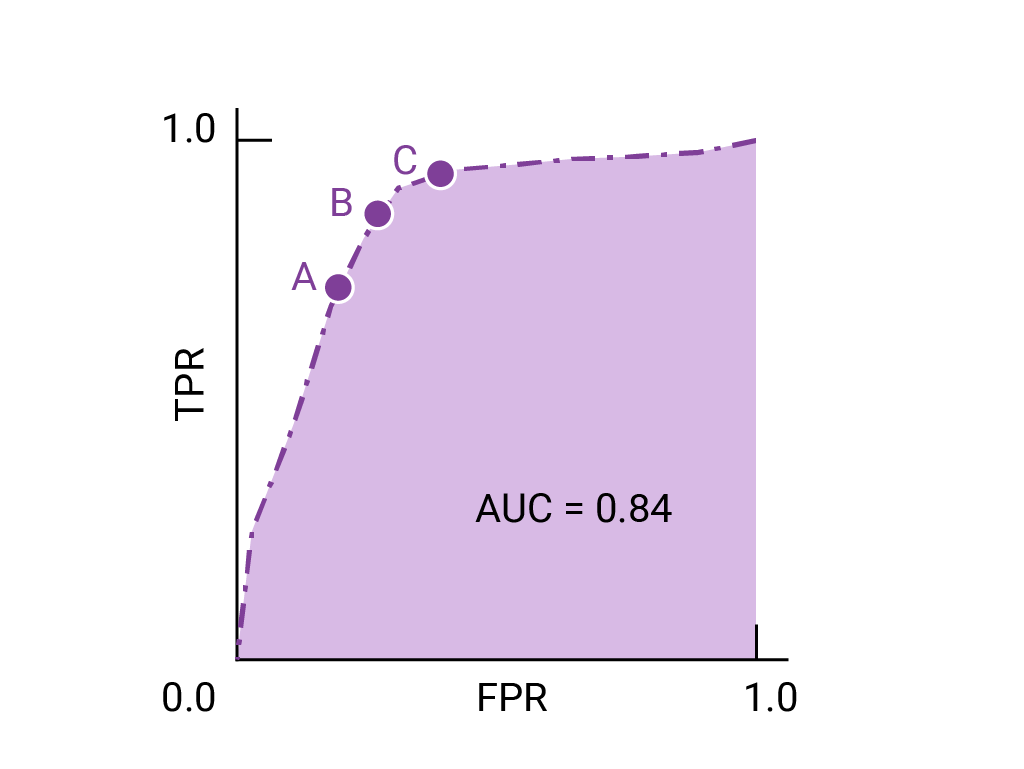
오탐 (오탐)에 많은 비용이 많이 드는 경우, TPR이 있더라도 A 지점에서처럼 더 낮은 FPR을 제공하는 임곗값을 선택합니다. 감소합니다 반대로 거짓양성이 비용이 적게 들고 거짓음성인 경우 많은 비용이 들며, 포인트 C의 임곗값은 TPR을 최대화하는 것이 바람직할 수 있습니다. 비용이 거의 동일하다면 B 포인트입니다. TPR과 FPR 사이의 최적의 균형을 제공할 수 있습니다.
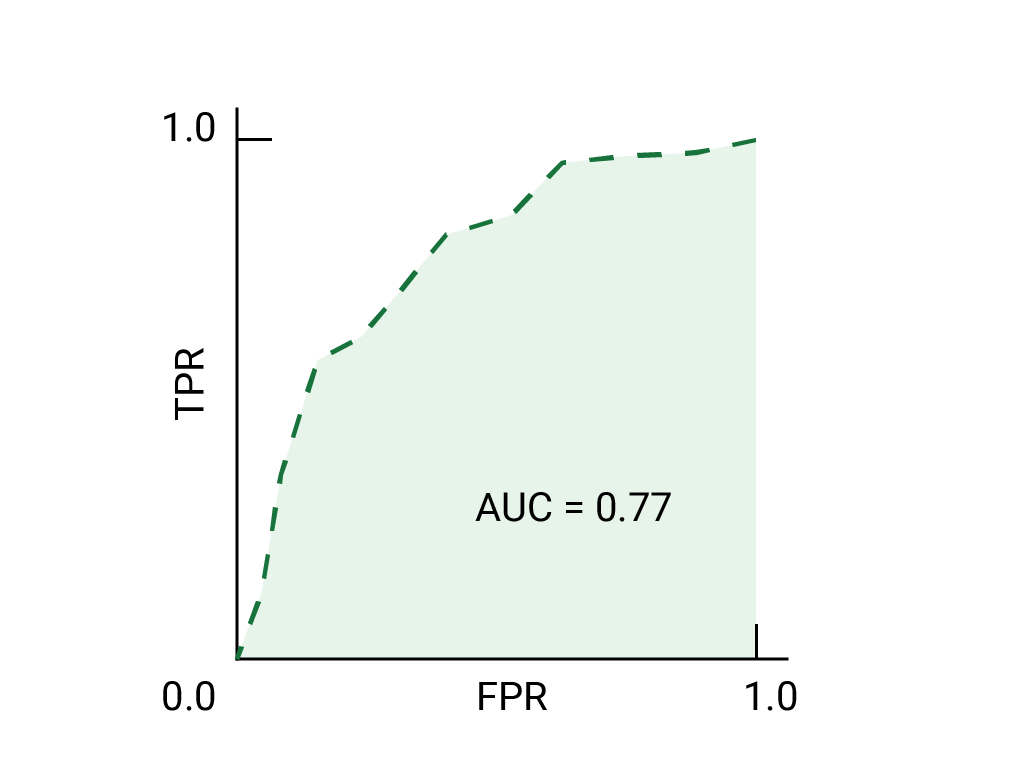
다음은 이전에 확인한 데이터의 ROC 곡선입니다.
연습문제: 학습 내용 점검하기
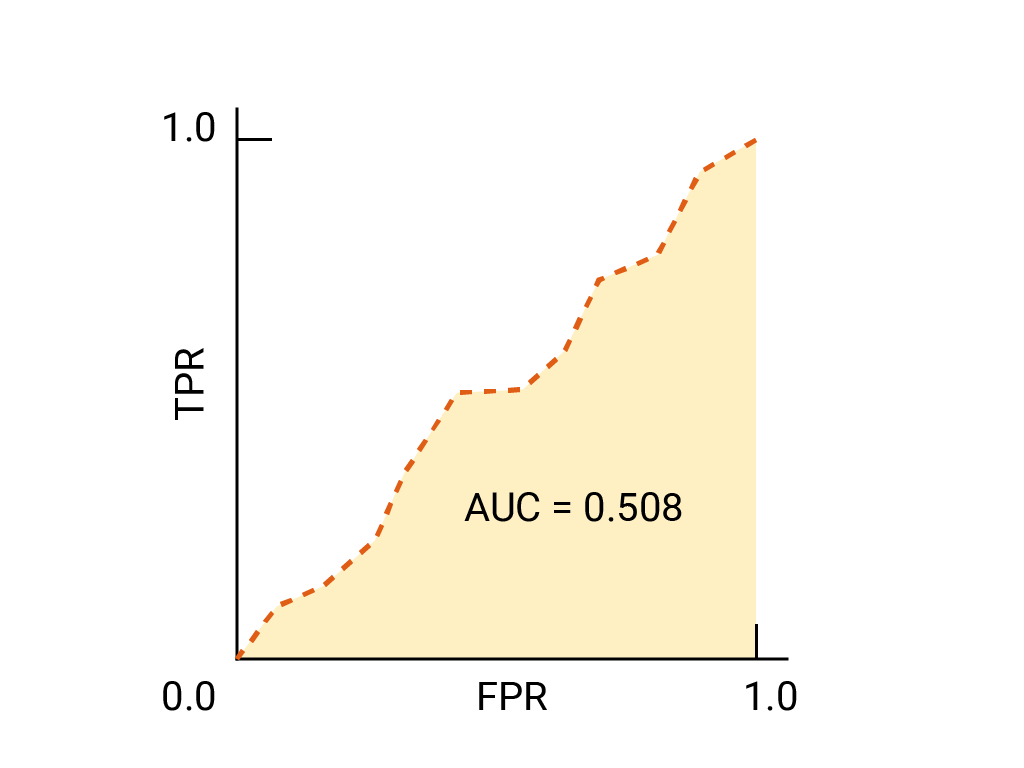
(선택사항, 고급) 보너스 질문
어떤 스팸이 스팸이 18,000원에 도달하는 것이 더 좋은 사용하는 것이 더 낫습니다. 이미 포지티브 클래스가 네거티브 클래스는 스팸이 아닙니다 다음 중 어느 점 어느 것이 더 낫습니까?