上一部分介绍了一组模型指标,这些指标均以 单个分类阈值。但如果您想评估 模型质量在所有可能的阈值下,则需要不同的工具。
接收者操作特征曲线 (ROC)
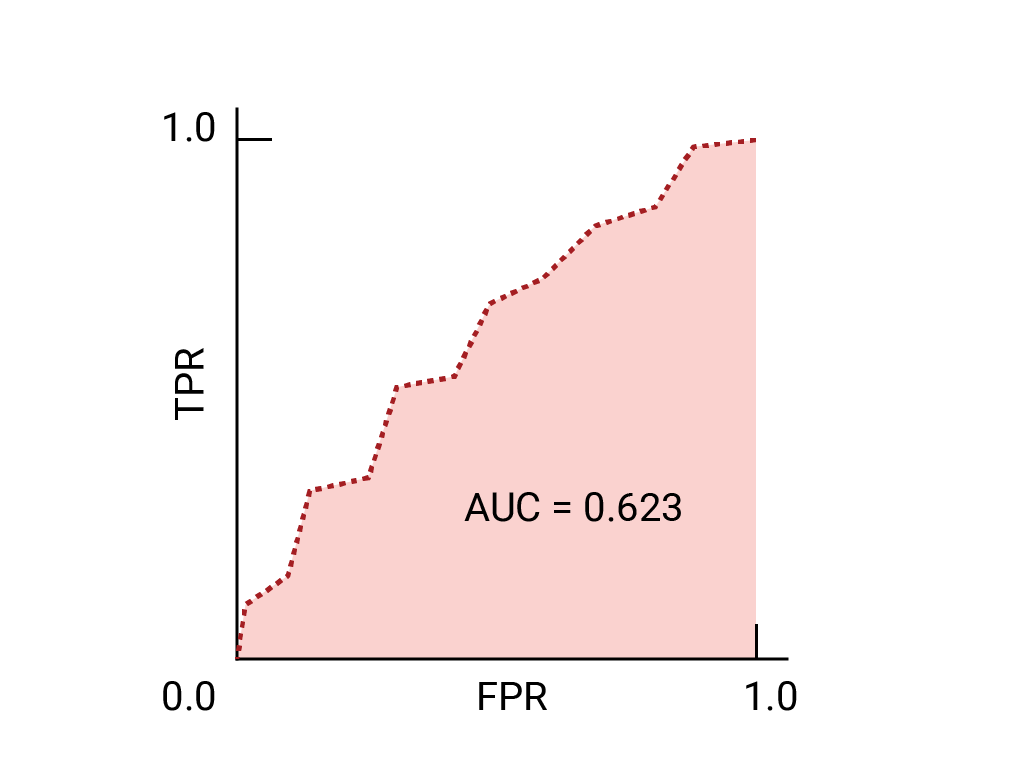
ROC 曲线 是模型在所有阈值上的表现的可视化表示。 这个长版名称(即接收器操作特征) 来自二战雷达侦测工具
ROC 曲线的绘制方法是计算真正例率 (TPR) 和假正例率 (FPR) 值(在实践中, 然后绘制 FPR 的 TPR 图表。完美的模特 在某些阈值下,TPR 为 1.0, FPR 为 0.0, 都表示为 (0, 1)(如果所有其他阈值均被忽略),或者出现以下情况:
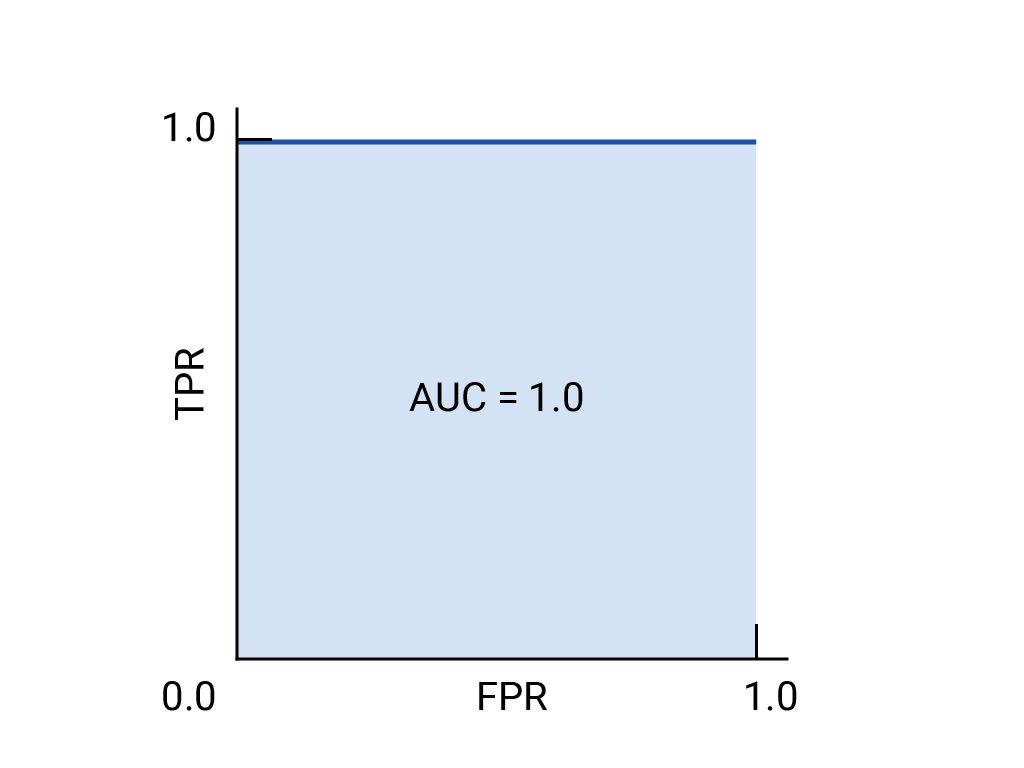
曲线下方面积 (AUC)
ROC 曲线下面积 (AUC) 表示模型的概率, 如果给定一个随机选择的正类别和负类别样本, 正值将大于负值。
上述完美模型包含一个边长为 1 的正方形, 曲线下面积 (AUC) 为 1.0。也就是说,有 100% 的可能性 模型会正确地将随机选择的正例排列在 随机选择的负例。换句话说,如果观察 AUC 给出了模型将 随机选择的圆圈右侧的平方,与 阈值。

具体而言,使用 AUC 的垃圾邮件分类器 则随机分配垃圾邮件的概率始终较高, 随机生成合法电子邮件每个单元的实际分类 取决于您选择的阈值。
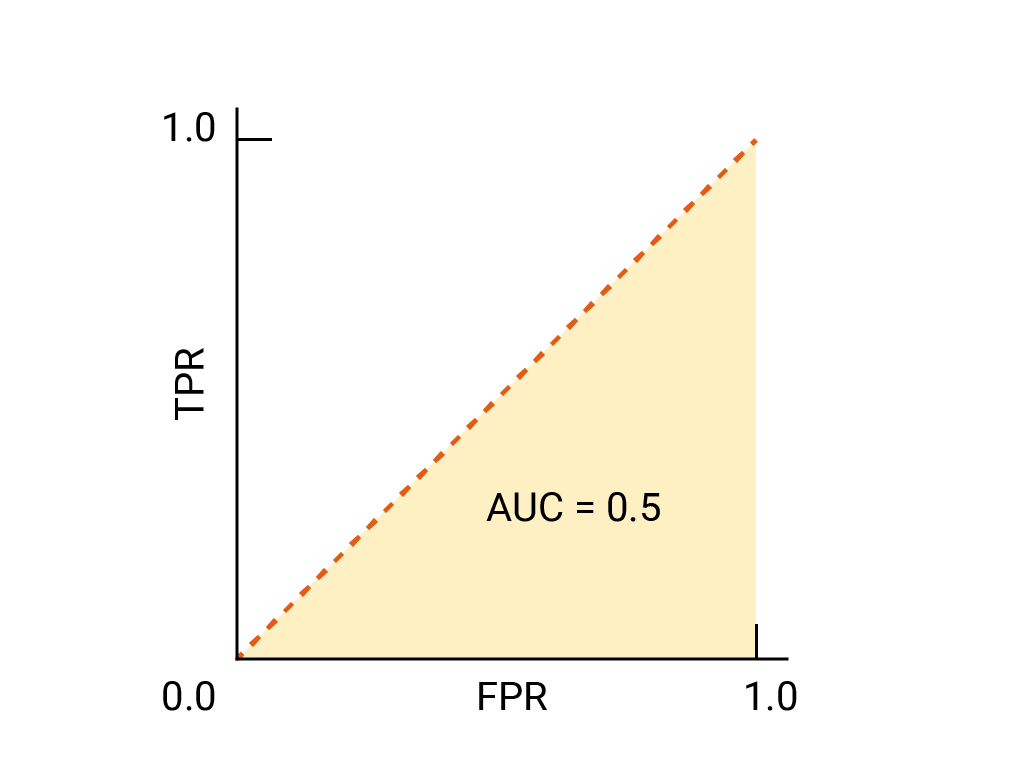
对于二元分类器来说,一个模型与随机猜测或 抛硬币的 ROC,它是一条从 (0,0) 到 (1,1) 的对角线。曲线下面积为 0.5,表示对某个随机正例进行排名的概率为 50%, 反例。
在垃圾邮件分类器示例中,AUC 为 0.5 的垃圾邮件分类器将 随机发送垃圾邮件的概率要高于随机发送的垃圾邮件 合法电子邮件只占一半的时间。
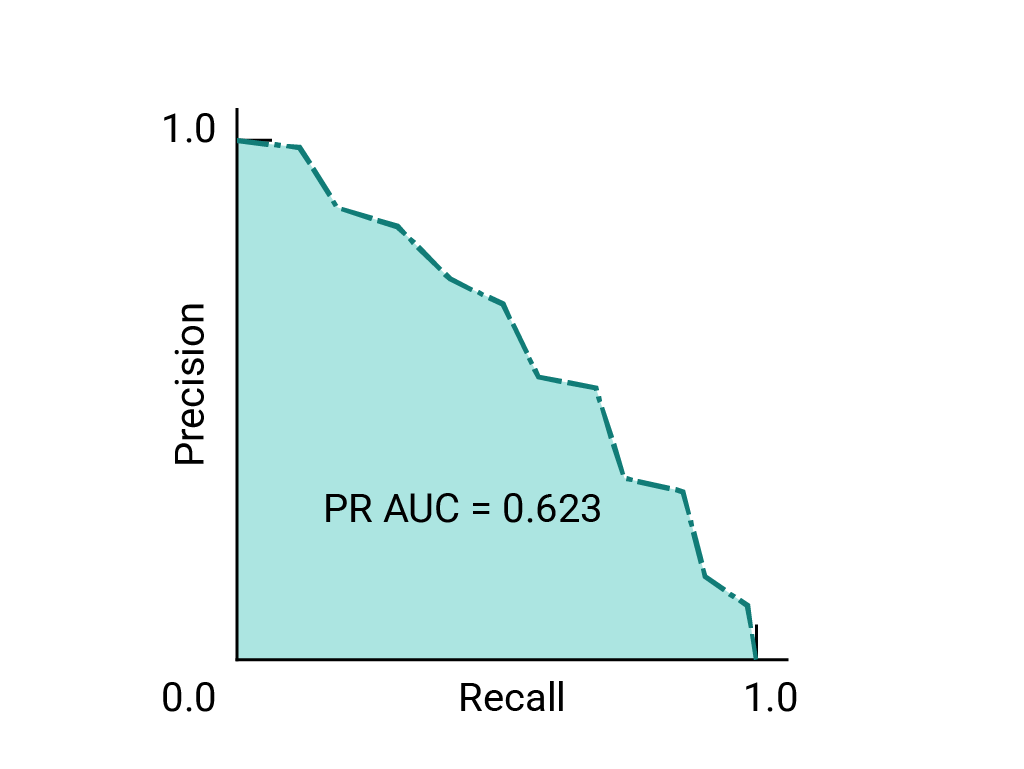
(可选,高级)精确率与召回率曲线
AUC 和 ROC 非常适合在数据集大致如下的情况下比较模型 不同类别之间的平衡。当数据集不平衡时,精确率与召回率 以及这些曲线下方区域的面积可能会提供 直观呈现模型性能精确率/召回率曲线由 y 轴的精确率和 x 轴的召回率 阈值。
用于选择模型和阈值的 AUC 和 ROC
曲线下面积是一个非常有用的指标,用于比较两个不同模型 只要数据集大致均衡即可。(请参阅精确率与召回率曲线, 针对不平衡的数据集。)下方是较大区域 那么曲线通常效果最佳
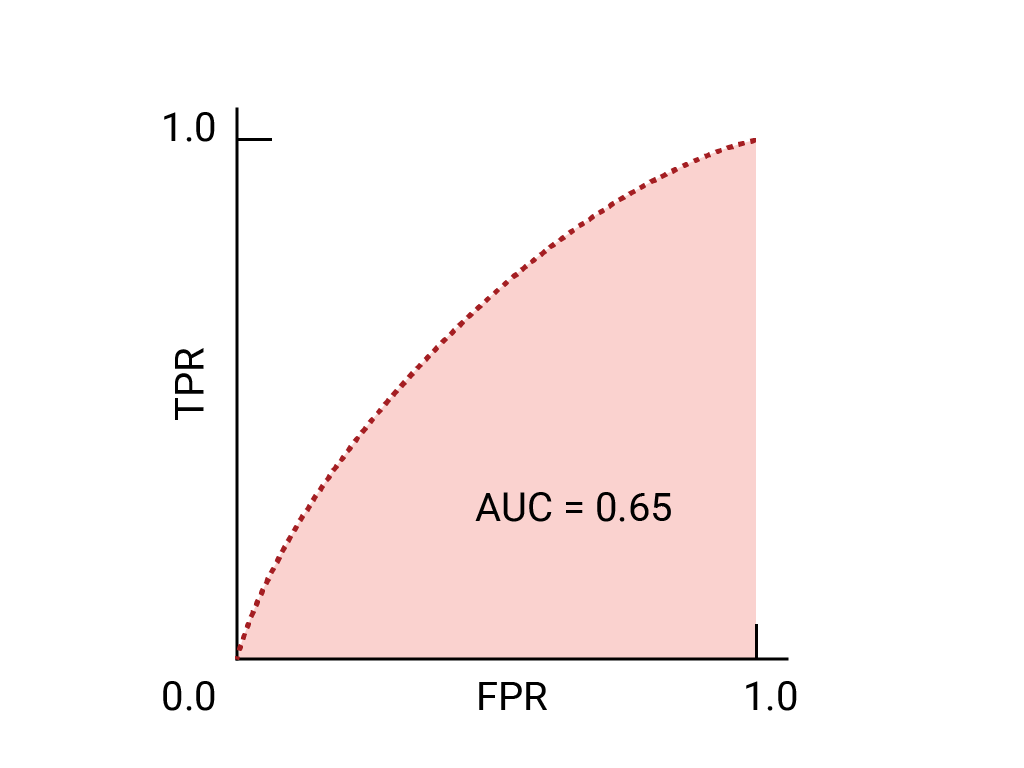
ROC 曲线上最接近 (0,1) 的点表示 指定模型表现最佳的阈值。正如 阈值、 混淆矩阵 和 指标选择和权衡 选择阈值取决于对应用而言最重要的指标 具体用例。请考虑以下要点 A、B 和 C 示意图,每个选项代表一个阈值:
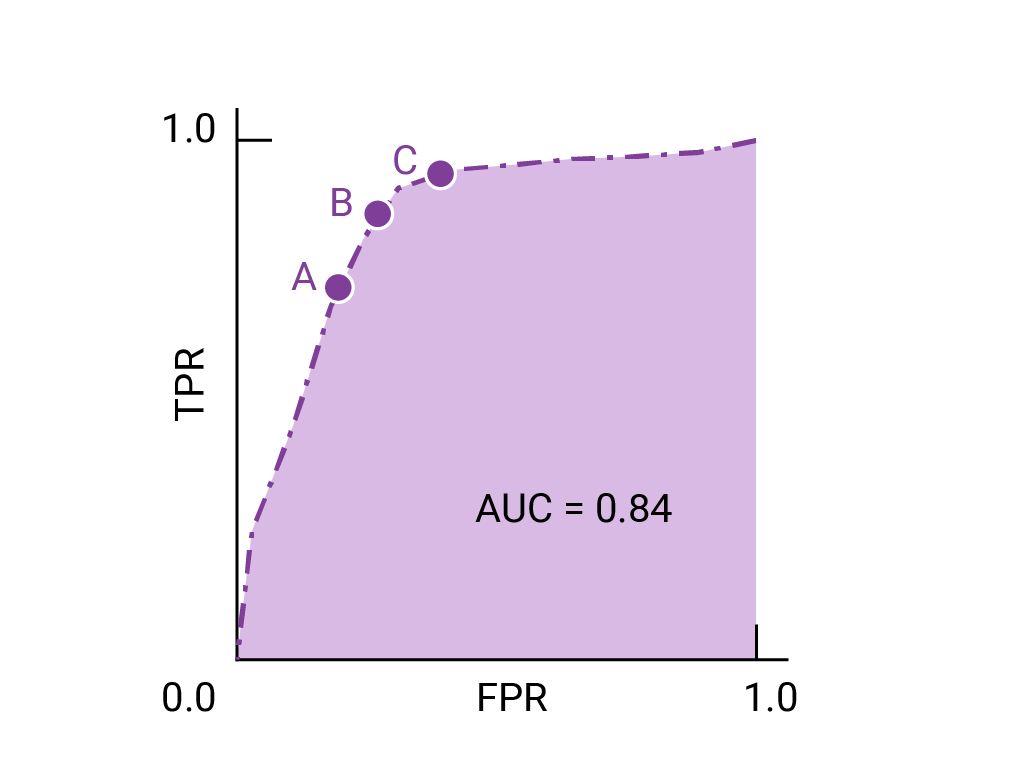
如果误报(误报)的代价很高, 即使 TPR 。相反,如果假正例费用低廉, (错失的真正例)代价很高,C 点的阈值 可以最大限度提高 TPR,可能更合适。如果费用大致相等,请确定 B 点 可在 TPR 和 FPR 之间实现最佳平衡。
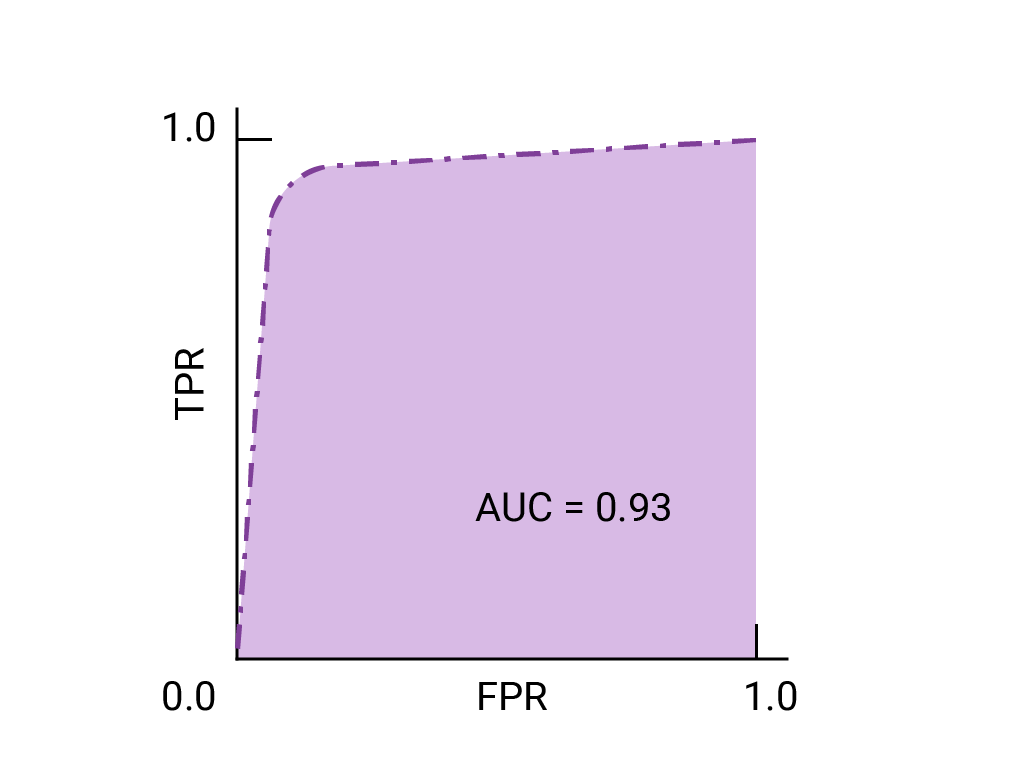
以下是我们之前看到的数据的 ROC 曲线:
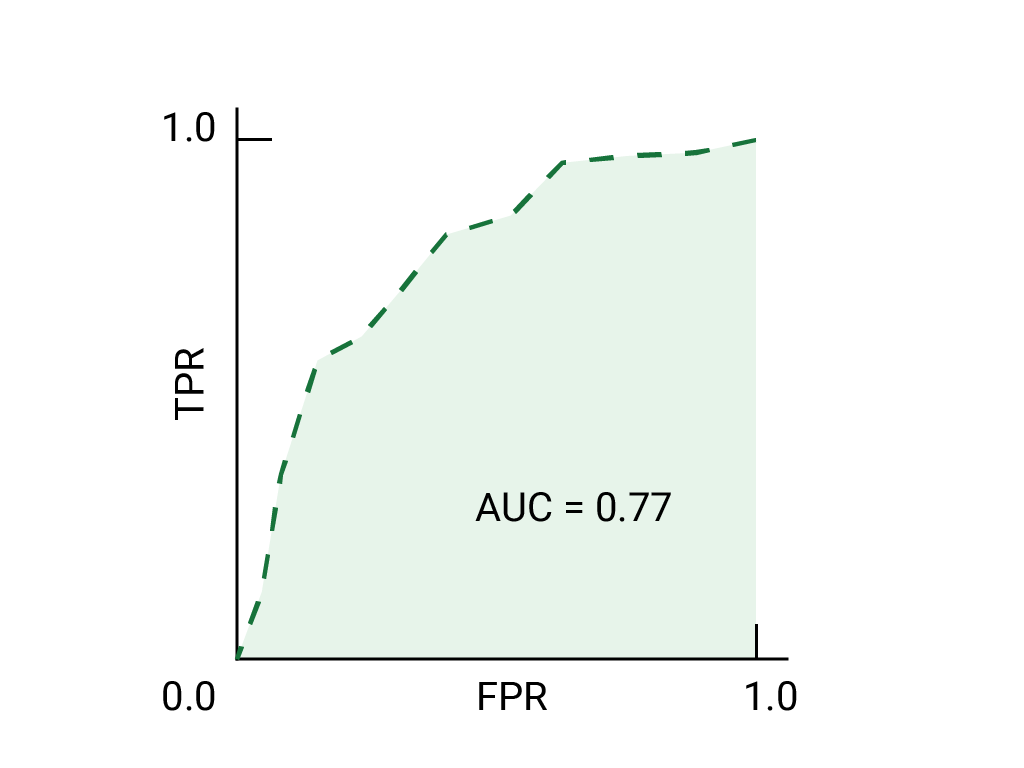
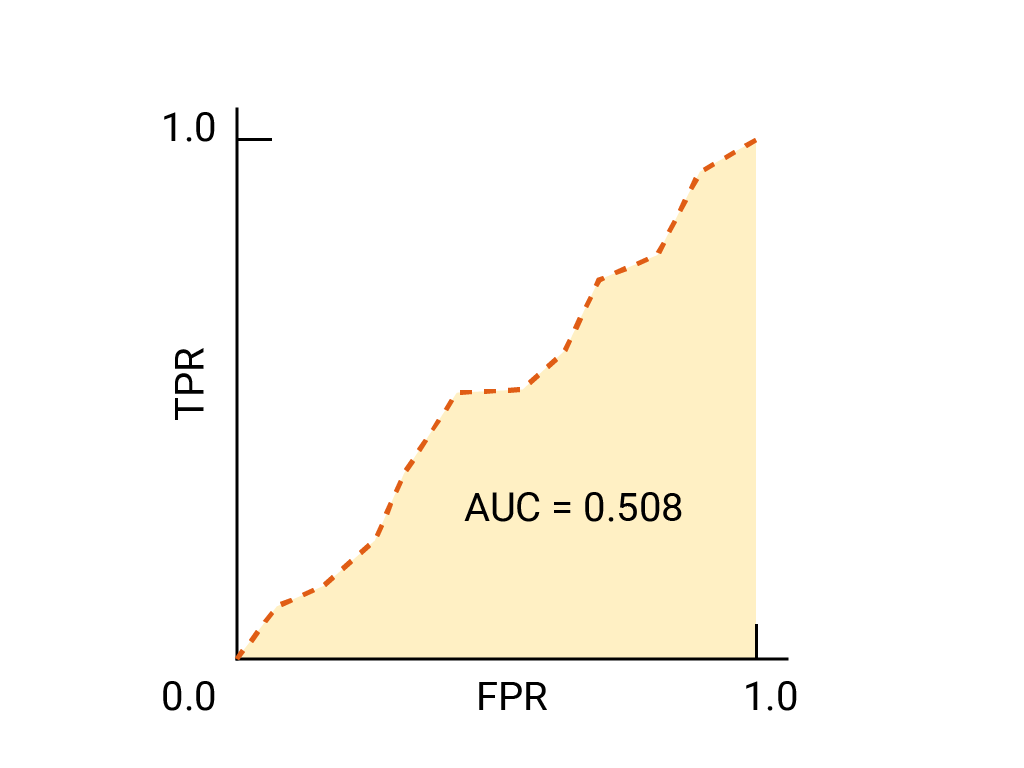
练习:检查您的理解情况
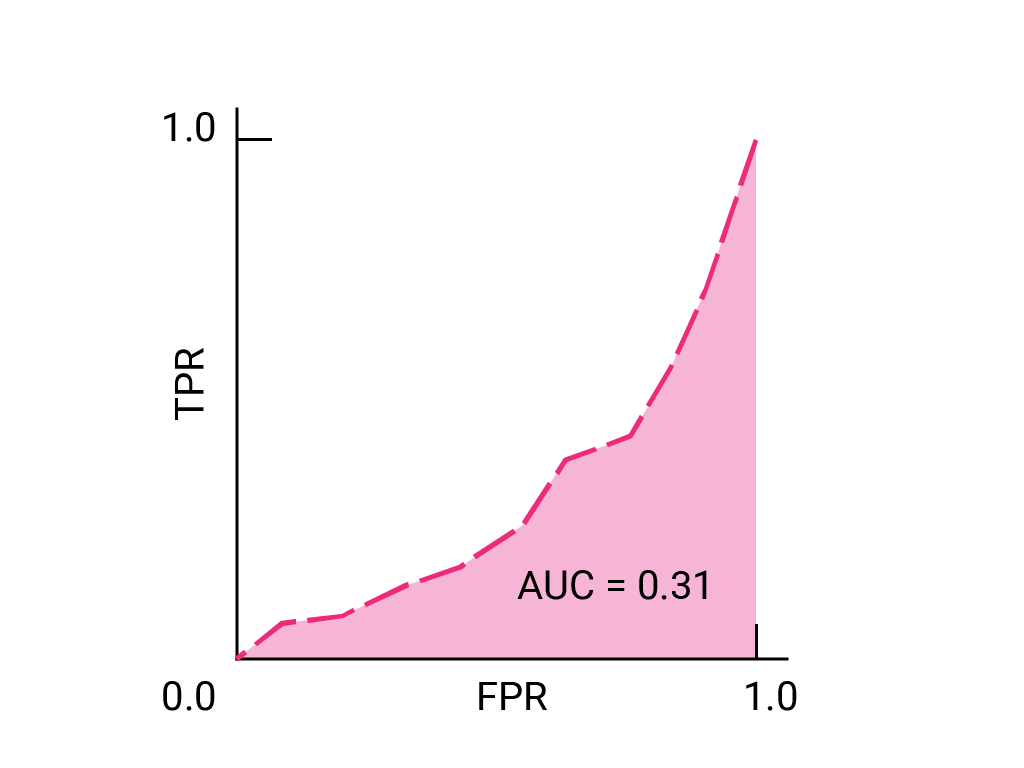
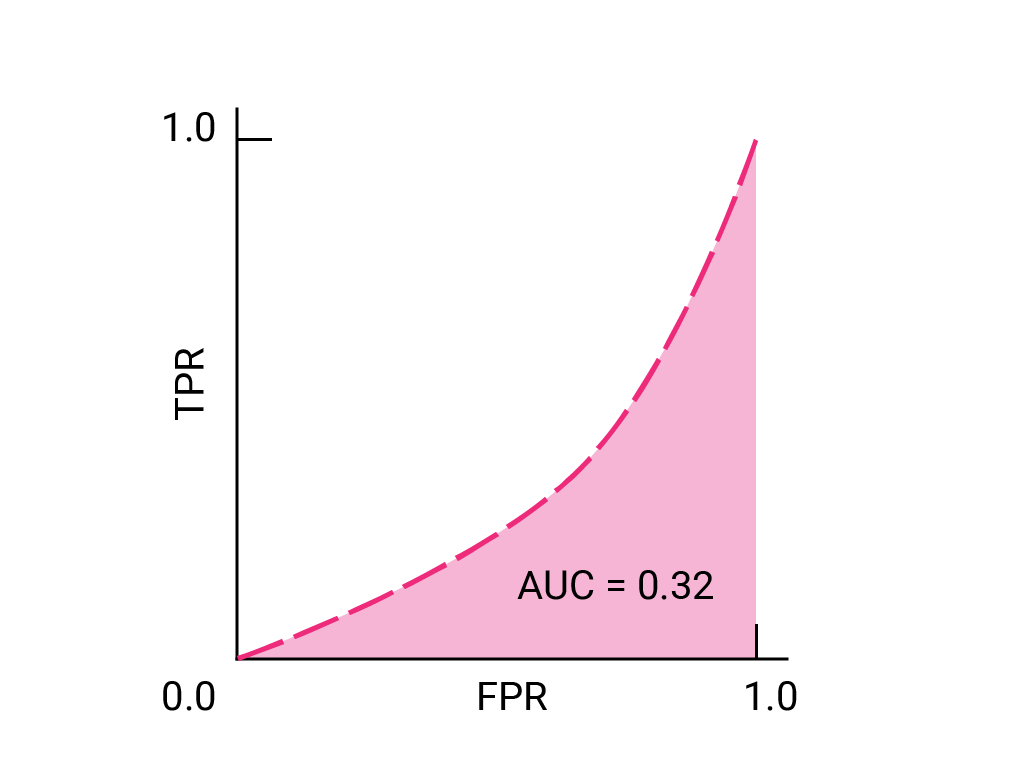
(可选,高级)奖励问题
试想一下,在这样一种情况下,最好让一些垃圾邮件进入 将对业务至关重要的电子邮件发送到垃圾邮件文件夹。您已 针对这种情况,我们训练了一个垃圾邮件分类器, 而负类别则不是垃圾邮件。 以下哪些要点 ROC 曲线上的任何数据是否更合适?