이전 섹션에서는 모두 단일 분류 기준점 값으로 계산된 일련의 모델 측정항목을 제시했습니다. 하지만 가능한 모든 임계값에서 모델의 품질을 평가하려면 다른 도구가 필요합니다.
수신자 조작 특성 곡선 (ROC)
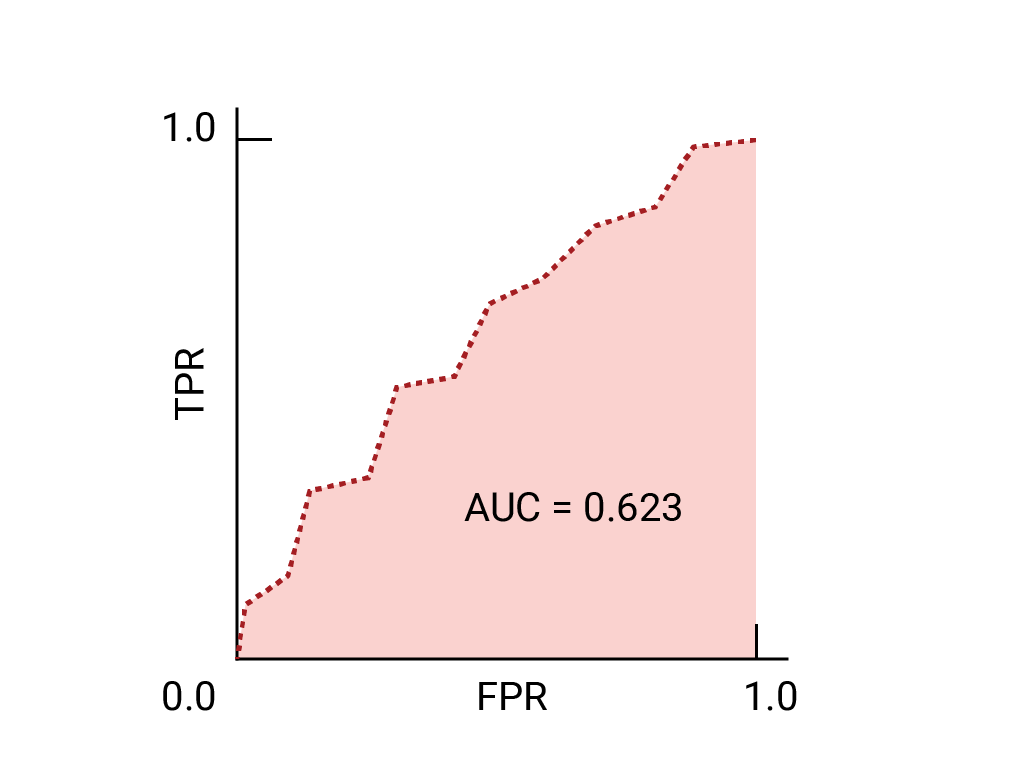
ROC 곡선은 모든 임곗값에서의 모델 성능을 시각적으로 나타냅니다. 이름의 긴 버전인 수신기 작동 특성은 제2차 세계대전 레이더 감지에서 이어져 내려온 것입니다.
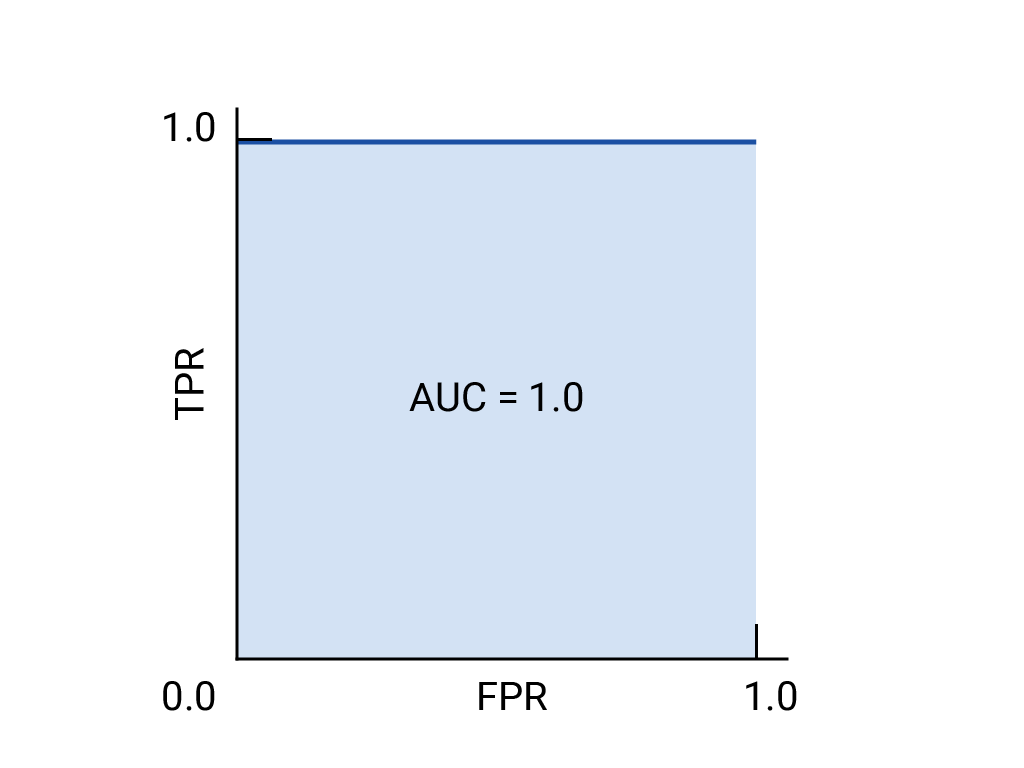
ROC 곡선은 가능한 모든 임곗값 (실제로는 선택한 간격)에서 참양성률 (TPR)과 거짓양성률 (FPR)을 계산한 다음 FPR에 대해 TPR을 그래프로 표시하여 그립니다. 특정 임계값에서 TPR이 1.0이고 FPR이 0.0인 완벽한 모델은 다른 모든 임계값을 무시하는 경우 (0, 1) 지점으로 나타낼 수 있으며, 다음과 같이 나타낼 수도 있습니다.
곡선 아래 영역 (AUC)
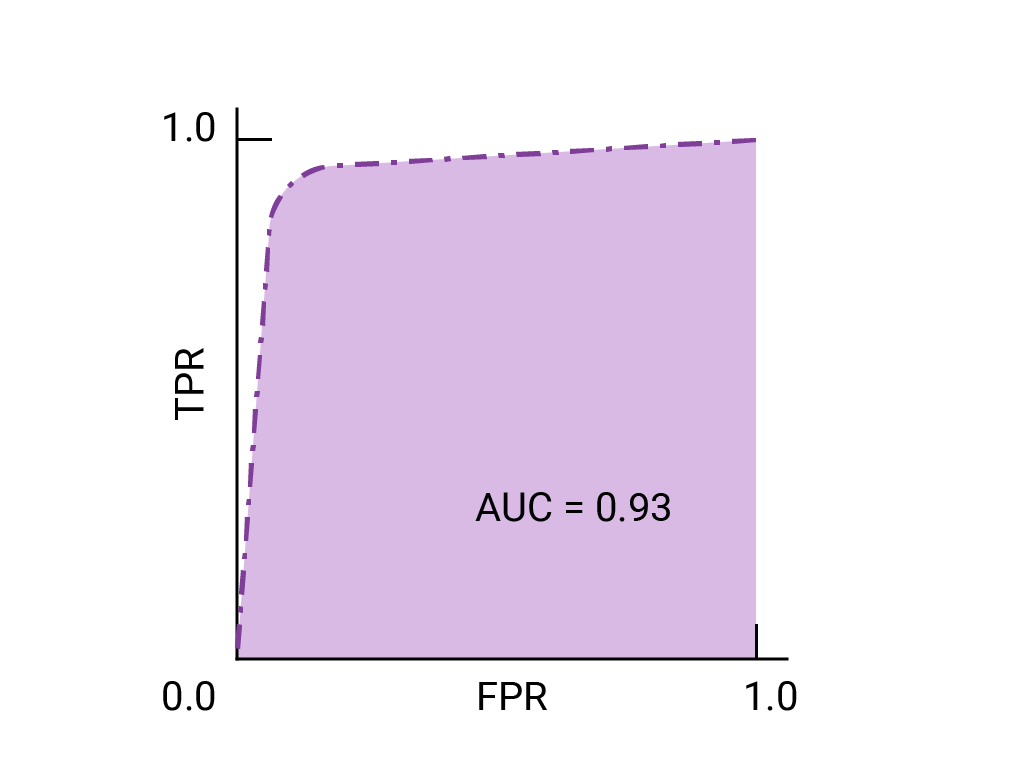
ROC 곡선 아래 영역 (AUC)은 무작위로 선택한 양성 예시와 음성 예시가 주어지면 모델이 양성 예시를 음성 예시보다 높은 순위로 매길 확률을 나타냅니다.
위의 완벽한 모델은 한 변의 길이가 1인 정사각형을 포함하며 곡선 아래 영역 (AUC)이 1.0입니다. 즉, 모델이 무작위로 선택한 양성 예시를 무작위로 선택한 음성 예시보다 정확하게 높은 순위에 올릴 확률은 100% 입니다. 즉, 아래 데이터 포인트의 확산을 보면 AUC는 임계값이 설정된 위치와 관계없이 모델이 무작위로 선택된 정사각형을 무작위로 선택된 원의 오른쪽에 배치할 확률을 나타냅니다.

보다 구체적으로 말하자면 AUC가 1.0인 스팸 분류기는 무작위 스팸 이메일에 무작위로 선택된 정상 이메일보다 스팸일 가능성이 더 높다고 항상 할당합니다. 각 이메일의 실제 분류는 선택한 기준점에 따라 다릅니다.
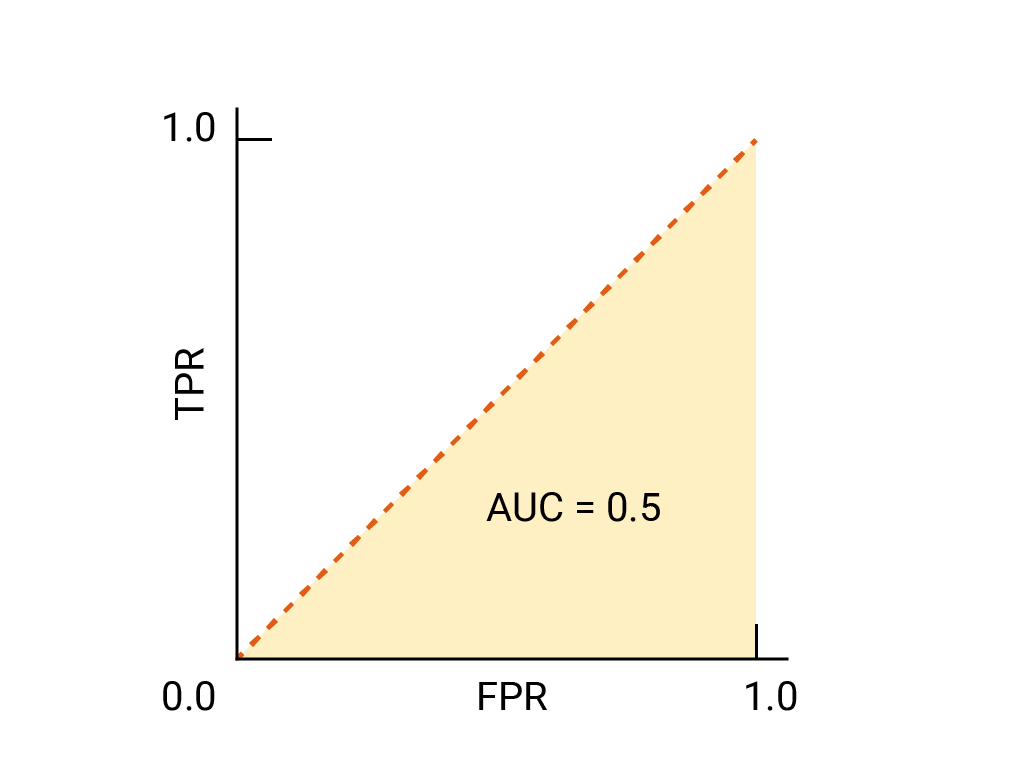
이진 분류기의 경우 무작위 추측이나 동전 던지기와 정확히 동일한 성능을 보이는 모델의 ROC는 (0,0)에서 (1,1)까지의 대각선입니다. AUC는 0.5로, 무작위 양성 예시와 음성 예시를 올바르게 순위 지정할 확률이 50% 임을 나타냅니다.
스팸 분류기 예에서 AUC가 0.5인 스팸 분류기는 무작위 스팸 이메일에 무작위로 선택된 정상 이메일보다 스팸일 확률이 높다는 라벨을 절반의 확률로 할당합니다.
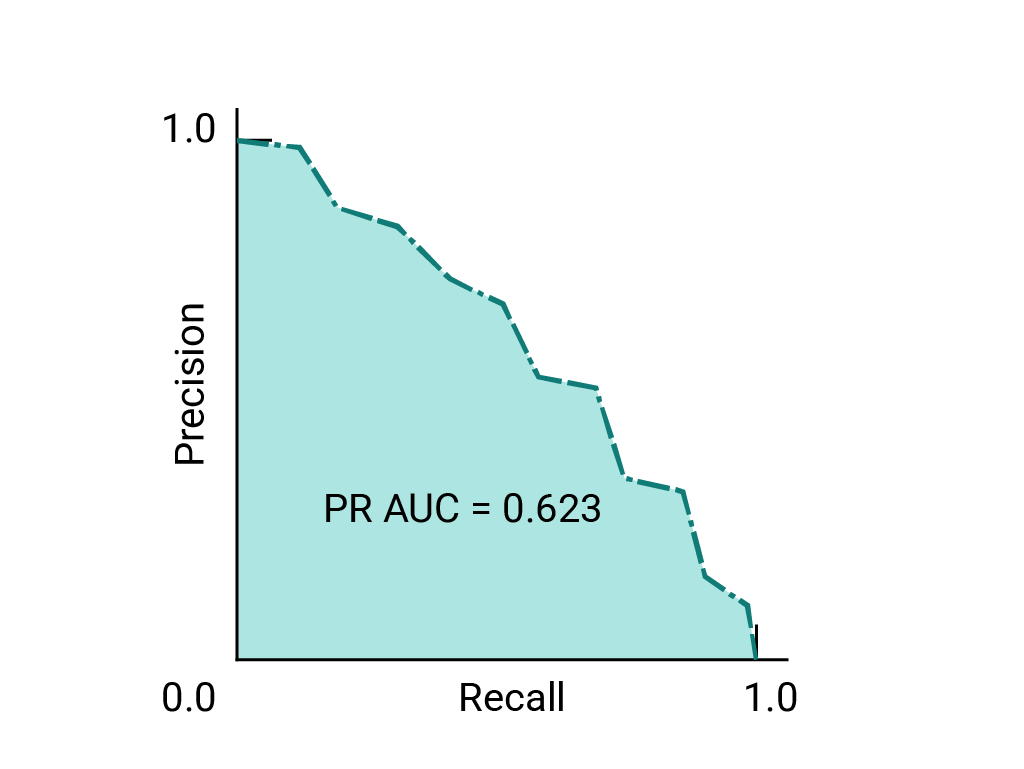
(선택사항, 고급) 정밀도-재현율 곡선
AUC와 ROC는 데이터 세트의 클래스 간에 대략적인 균형이 유지될 때 모델을 비교하는 데 적합합니다. 데이터 세트가 불균형한 경우 정밀도-재현율 곡선 (PRC)과 이러한 곡선 아래의 영역이 모델 성능을 더 잘 비교하여 시각화할 수 있습니다. 정밀도-재현율 곡선은 모든 임곗값에서 정밀도를 y축에, 재현율을 x축에 표시하여 만듭니다.
모델 및 임곗값 선택을 위한 AUC 및 ROC
AUC는 데이터 세트의 균형이 대략 맞는 한 두 가지 모델의 성능을 비교하는 데 유용한 측정항목입니다. 일반적으로 곡선 아래의 면적이 더 큰 모델이 더 좋습니다.
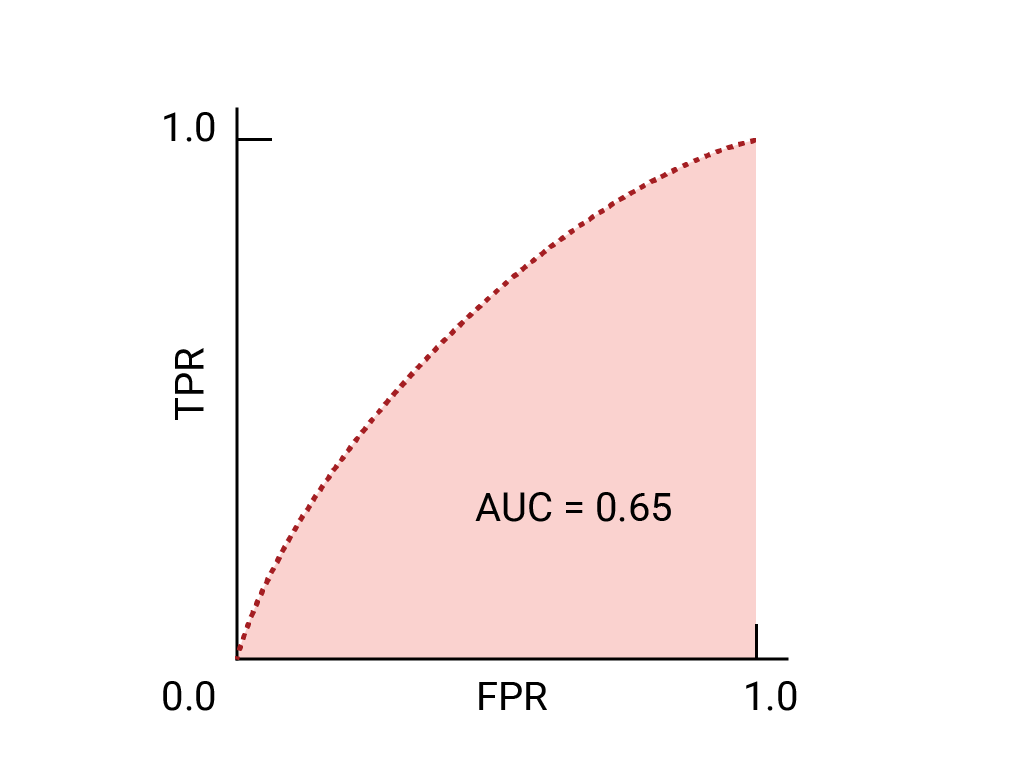
ROC 곡선에서 (0,1)에 가장 가까운 점은 특정 모델에 가장 적합한 임곗값의 범위를 나타냅니다. 기준점, 혼동 행렬, 측정항목 선택 및 절충사항 섹션에서 설명한 대로 선택하는 기준점은 특정 사용 사례에 가장 중요한 측정항목에 따라 다릅니다. 다음 다이어그램의 A, B, C 지점은 각각 임곗값을 나타냅니다.
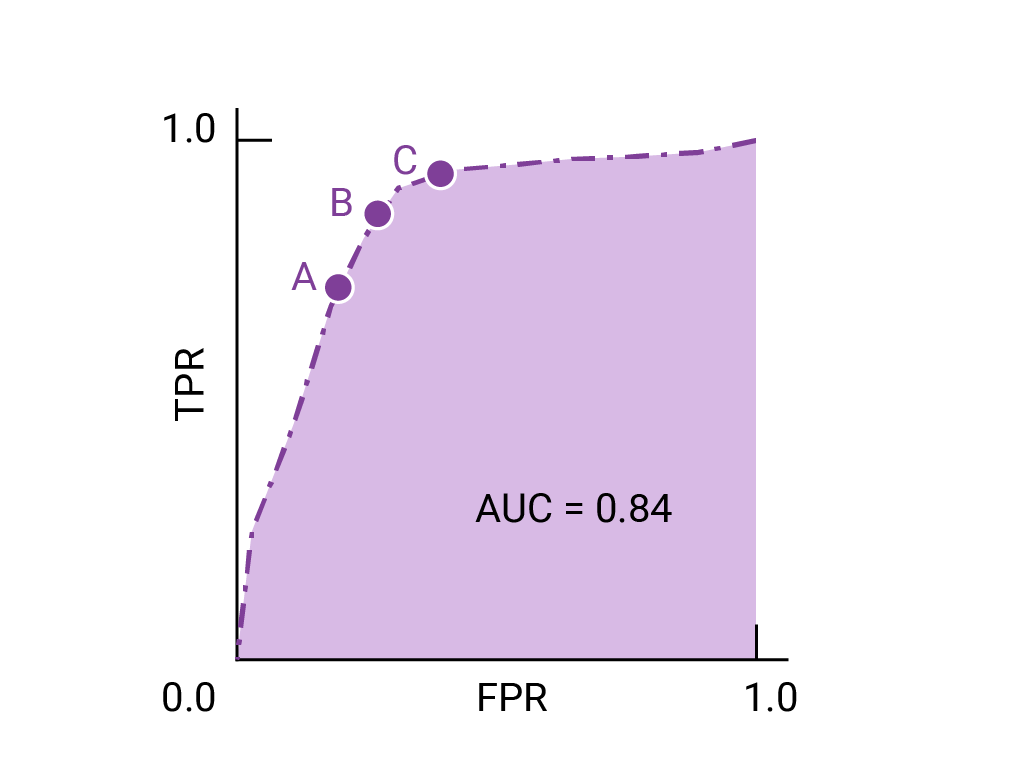
거짓양성 (거짓 경보)의 비용이 매우 큰 경우 TPR이 감소하더라도 A 지점의 임계값과 같이 FPR이 더 낮은 임계값을 선택하는 것이 좋습니다. 반대로 거짓양성은 비용이 적게 들고 거짓음성(누락된 참양성)은 비용이 많이 드는 경우 TPR을 극대화하는 점 C의 기준점이 더 나을 수 있습니다. 비용이 거의 비슷하다면 B 지점이 TPR과 FPR 간의 균형을 가장 잘 유지할 수 있습니다.
이전에 본 데이터의 ROC 곡선은 다음과 같습니다.
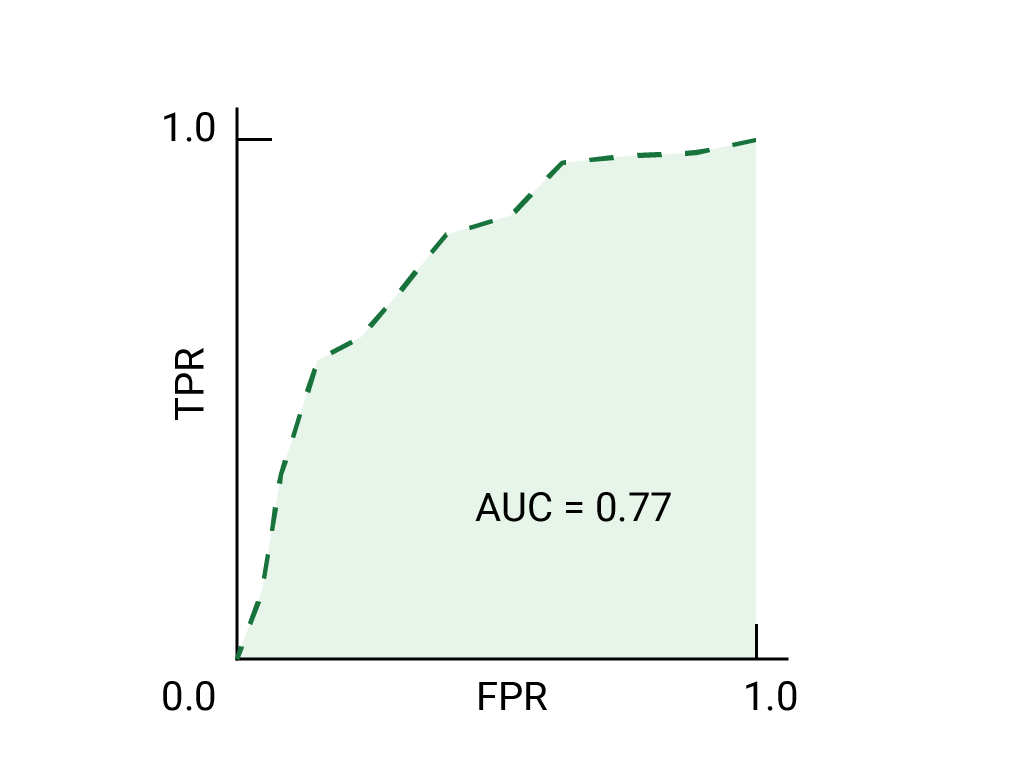
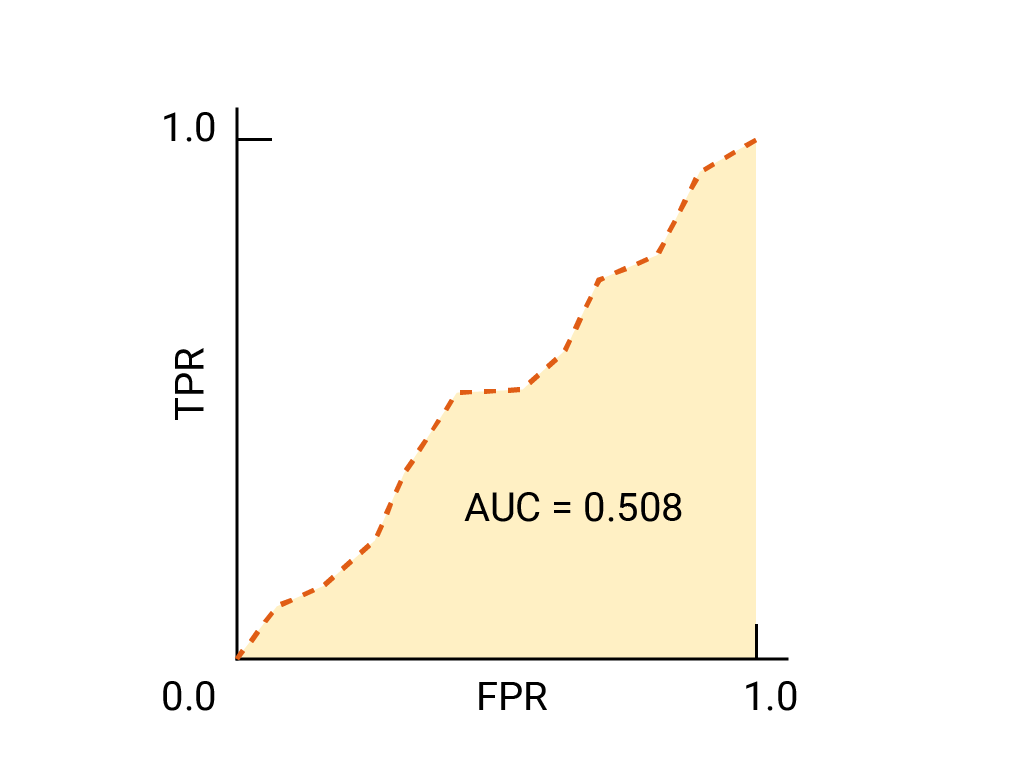
연습: 학습 내용 점검하기
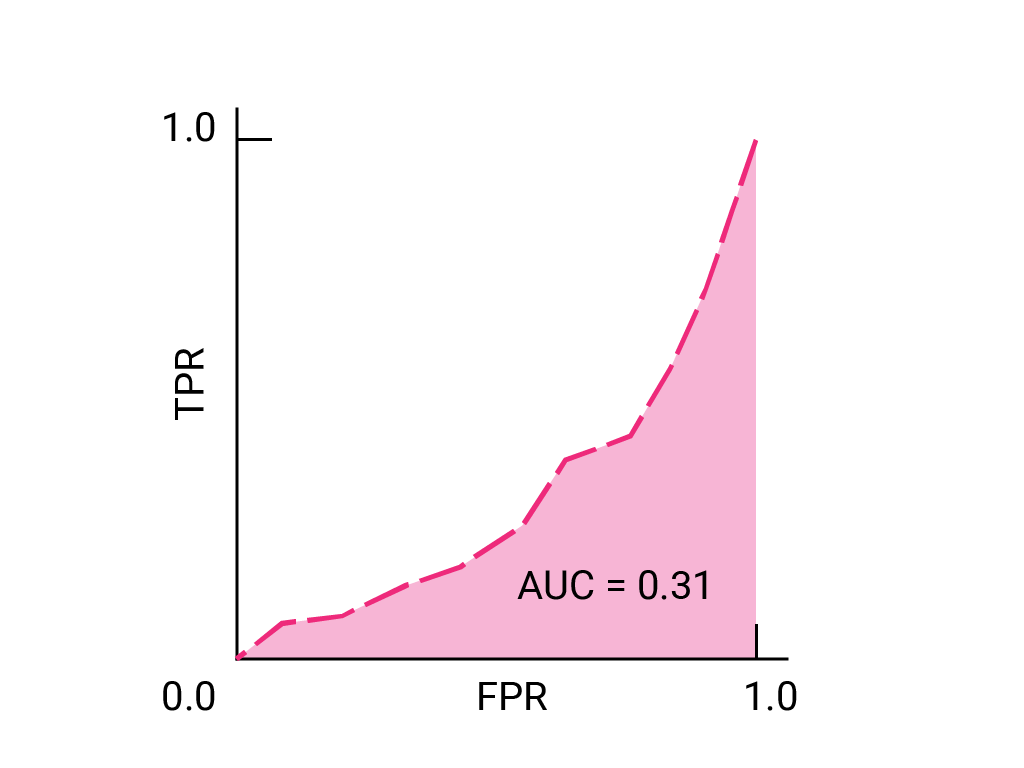
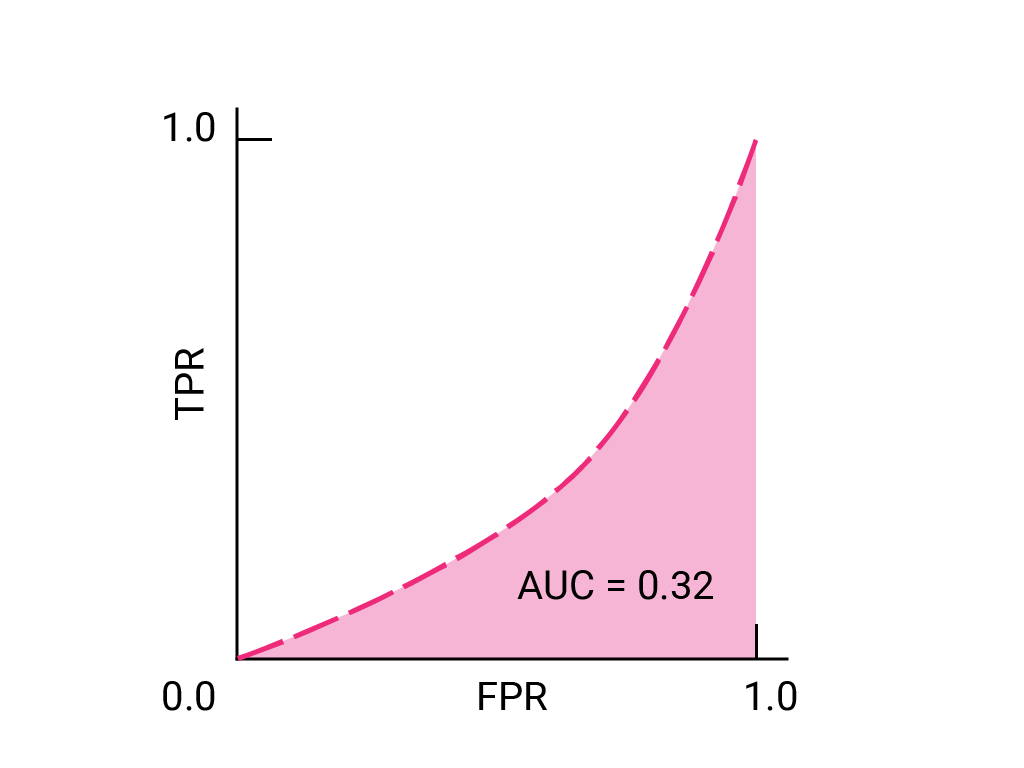
(선택사항, 고급) 보너스 문제
비즈니스상 중요한 이메일을 스팸 폴더로 보내는 것보다 일부 스팸이 받은편지함으로 도착하도록 허용하는 것이 더 나은 상황을 예로 들 수 있습니다. 포지티브 클래스가 스팸이고 네거티브 클래스가 스팸이 아닌 이 상황에 맞게 스팸 분류기를 학습했습니다. 분류기의 ROC 곡선에서 다음 중 어느 지점이 더 바람직한가요?