بخش قبلی مجموعهای از معیارهای مدل را ارائه میکند که همگی در یک مقدار آستانه طبقهبندی محاسبه شدهاند. اما اگر می خواهید کیفیت یک مدل را در تمام آستانه های ممکن ارزیابی کنید، به ابزارهای مختلفی نیاز دارید.
منحنی مشخصه عملکرد گیرنده (ROC)
منحنی ROC یک نمایش بصری از عملکرد مدل در تمام آستانه ها است. نسخه طولانی این نام، مشخصه عملکرد گیرنده، از کشف راداری جنگ جهانی دوم باقی مانده است.
منحنی ROC با محاسبه نرخ مثبت واقعی (TPR) و نرخ مثبت کاذب (FPR) در هر آستانه ممکن (در عمل، در فواصل زمانی انتخاب شده)، سپس نمودار TPR بر روی FPR ترسیم می شود. یک مدل کامل، که در برخی از آستانه ها دارای TPR 1.0 و FPR 0.0 است، می تواند با یک نقطه در (0، 1) در صورتی که همه آستانه های دیگر نادیده گرفته شوند، یا با موارد زیر نشان داده شود:

مساحت زیر منحنی (AUC)
سطح زیر منحنی ROC (AUC) نشان دهنده این احتمال است که مدل، اگر به طور تصادفی یک مثال مثبت و منفی انتخاب شود، مثبت را بالاتر از منفی قرار دهد.
مدل کامل بالا، شامل مربعی با اضلاع به طول 1، دارای مساحت زیر منحنی (AUC) 1.0 است. این به این معنی است که احتمال 100٪ وجود دارد که مدل به درستی یک مثال مثبت انتخاب شده به طور تصادفی را بالاتر از یک مثال منفی تصادفی انتخاب کند. به عبارت دیگر، با نگاهی به گسترش نقاط داده در زیر، AUC این احتمال را می دهد که مدل یک مربع به طور تصادفی انتخاب شده را در سمت راست دایره ای که به طور تصادفی انتخاب شده است، مستقل از جایی که آستانه تنظیم شده است، قرار دهد.

به عبارت دقیق تر، یک طبقه بندی کننده هرزنامه با AUC 1.0 همیشه به یک ایمیل هرزنامه تصادفی احتمال بیشتری نسبت به ایمیل های قانونی تصادفی برای اسپم بودن اختصاص می دهد. طبقه بندی واقعی هر ایمیل به آستانه ای که انتخاب می کنید بستگی دارد.
برای یک طبقهبندیکننده باینری، مدلی که دقیقاً به خوبی حدسهای تصادفی یا چرخش سکه انجام میدهد، دارای یک ROC است که یک خط مورب از (۰،۰) تا (۱،۱) است. AUC 0.5 است که نشان دهنده 50% احتمال رتبه بندی صحیح یک مثال تصادفی مثبت و منفی است.
در مثال طبقهبندی کننده هرزنامه، یک طبقهبندی کننده هرزنامه با AUC 0.5 به یک ایمیل هرزنامه تصادفی احتمال بیشتری برای اسپم بودن نسبت به ایمیلهای قانونی تصادفی اختصاص میدهد.

(اختیاری، پیشرفته) منحنی فراخوان دقیق
AUC و ROC برای مقایسه مدلها زمانی که مجموعه داده تقریباً بین کلاسها متعادل است، به خوبی کار میکنند. هنگامی که مجموعه داده نامتعادل است، منحنی های فراخوان دقیق (PRC) و ناحیه زیر آن منحنی ها ممکن است تجسم مقایسه ای بهتری از عملکرد مدل ارائه دهند. منحنیهای فراخوان دقیق با ترسیم دقت بر روی محور y و فراخوانی در محور x در تمام آستانهها ایجاد میشوند.

AUC و ROC برای انتخاب مدل و آستانه
AUC یک معیار مفید برای مقایسه عملکرد دو مدل مختلف است، تا زمانی که مجموعه داده تقریباً متعادل باشد. مدلی که سطح زیر منحنی بیشتری دارد معمولاً مدل بهتری است.


نقاط روی یک منحنی ROC نزدیکترین به (0،1) طیفی از آستانههای با بهترین عملکرد را برای مدل داده شده نشان میدهند. همانطور که در بخش آستانه ها ، ماتریس سردرگمی و انتخاب متریک و مبادلات بحث شد، آستانه ای که انتخاب می کنید بستگی به این دارد که کدام متریک برای مورد استفاده خاص مهم است. نقاط A، B و C را در نمودار زیر در نظر بگیرید که هر کدام یک آستانه را نشان می دهند:

اگر موارد مثبت کاذب (آژیرهای کاذب) بسیار پرهزینه هستند، ممکن است منطقی باشد که آستانه ای را انتخاب کنید که FPR کمتری می دهد، مانند آنچه در نقطه A است، حتی اگر TPR کاهش یابد. برعکس، اگر مثبت های کاذب ارزان و منفی های کاذب (مثبت های واقعی از دست رفته) بسیار پرهزینه باشند، آستانه نقطه C، که TPR را به حداکثر می رساند، ممکن است ارجح باشد. اگر هزینه ها تقریباً معادل باشند، نقطه B ممکن است بهترین تعادل را بین TPR و FPR ارائه دهد.
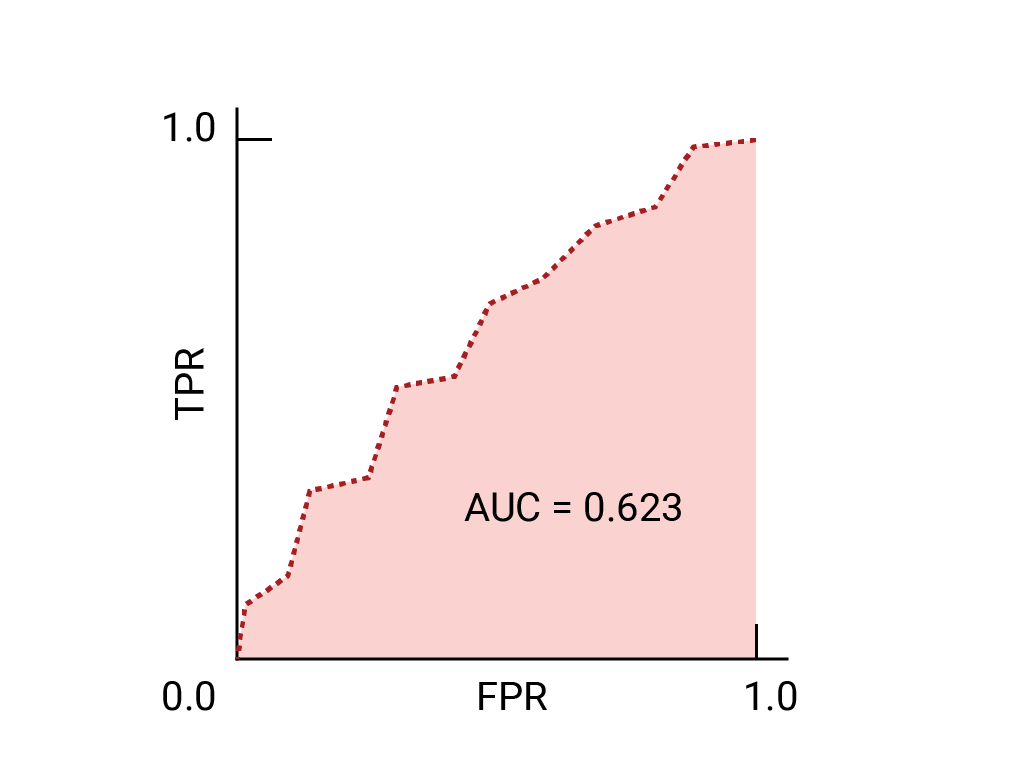
در اینجا منحنی ROC برای دادههایی که قبلا دیدهایم است:
تمرین: درک خود را بررسی کنید




(اختیاری، پیشرفته) سوال جایزه
وضعیتی را تصور کنید که در آن بهتر است اجازه دهید مقداری هرزنامه به صندوق ورودی برسد تا اینکه یک ایمیل مهم تجاری به پوشه هرزنامه ارسال کنید. شما یک طبقهبندی کننده هرزنامه را برای این وضعیت آموزش دادهاید که در آن کلاس مثبت هرزنامه است و کلاس منفی هرزنامه نیست. کدام یک از نقاط زیر در منحنی ROC برای طبقه بندی کننده شما ارجح است؟