Loss คือเมตริกตัวเลขที่อธิบายว่าการคาดการณ์ของโมเดลไม่ถูกต้องเพียงใด ค่าการสูญเสียจะวัดระยะห่างระหว่างการคาดการณ์ของโมเดลกับป้ายกำกับจริง เป้าหมายของการฝึกโมเดลคือการลดการสูญเสียให้เหลือน้อยที่สุด โดยลดค่าให้ต่ำที่สุด
ในรูปภาพต่อไปนี้ คุณสามารถเห็นภาพความสูญเสียเป็นลูกศรที่ลากจากจุดข้อมูลไปยังโมเดล รูปลูกศรแสดงระยะห่างระหว่างการคาดการณ์ของโมเดลกับค่าจริง
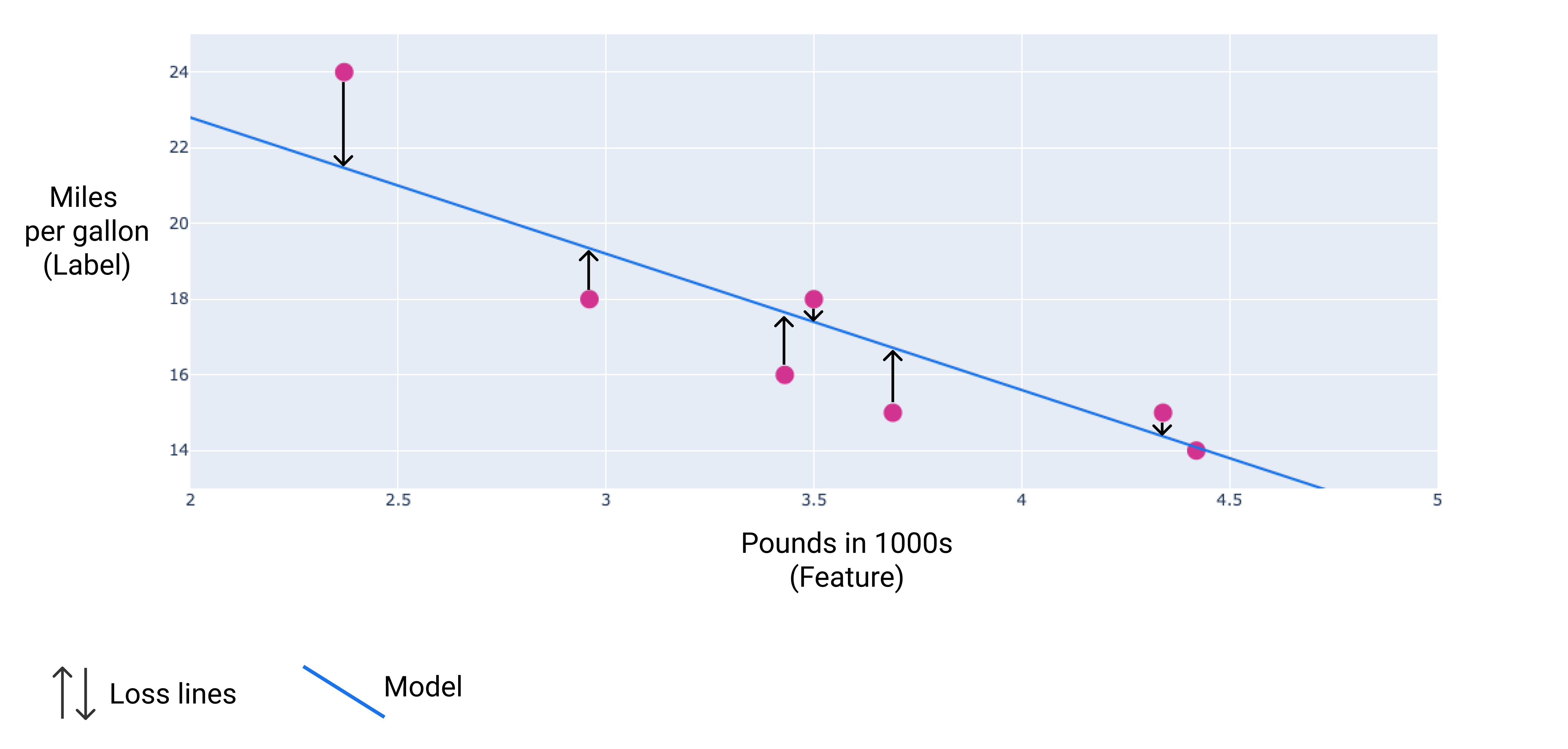
รูปที่ 9 โดยวัดการสูญเสียจากค่าจริงไปยังค่าที่คาดการณ์
ระยะทางของการสูญเสีย
ในสถิติและแมชชีนเลิร์นนิง ผลลัพธ์ที่เสียไปจะวัดความแตกต่างระหว่างค่าที่คาดการณ์ไว้กับค่าจริง การสูญเสียจะมุ่งเน้นที่ระยะห่างระหว่างค่าต่างๆ ไม่ใช่ทิศทาง เช่น หากโมเดลคาดการณ์เป็น 2 แต่ค่าจริงคือ 5 เราจะไม่สนใจว่าค่าสูญเสียเป็นลบ $ -3 $ ($ 2-5=-3 $) แต่สนใจระยะห่างระหว่างค่าคือ $ 3 $ ดังนั้นวิธีการทั้งหมดในการคํานวณการสูญเสียจึงนําเครื่องหมายลบออก
วิธีการ 2 วิธีที่นิยมใช้กันมากที่สุดในการนำป้ายออกมีดังนี้
- นำค่าสัมบูรณ์ของความแตกต่างระหว่างค่าจริงกับการคาดการณ์
- ยกกำลังสองของผลต่างระหว่างค่าจริงกับการคาดการณ์
ประเภทของการสูญเสีย
ในการถดถอยเชิงเส้น จะมีการสูญเสียหลัก 4 ประเภทตามที่ระบุไว้ในตารางต่อไปนี้
| ประเภทการสูญเสีย | คำจำกัดความ | สมการ |
|---|---|---|
| L1 loss | ผลรวมของค่าสัมบูรณ์ของความแตกต่างระหว่างค่าที่คาดการณ์กับค่าจริง | $ ∑ | actual\ value - predicted\ value | $ |
| ค่าเฉลี่ยความคลาดเคลื่อนสัมบูรณ์ (MAE) | ค่าเฉลี่ยของการสูญเสีย L1 ในชุดตัวอย่าง | $ \frac{1}{N} ∑ | actual\ value - predicted\ value | $ |
| L2 loss | ผลรวมของผลต่างกำลังสองระหว่างค่าที่คาดการณ์กับค่าจริง | $ ∑(actual\ value - predicted\ value)^2 $ |
| ความคลาดเคลื่อนเฉลี่ยกำลังสอง (MSE) | ค่าเฉลี่ยของการสูญเสีย L2 ในชุดตัวอย่าง | $ \frac{1}{N} ∑ (actual\ value - predicted\ value)^2 $ |
ความแตกต่างด้านฟังก์ชันระหว่างความสูญเสีย L1 กับความสูญเสีย L2 (หรือระหว่าง MAE กับ MSE) คือการเพิ่มกำลังสอง เมื่อความแตกต่างระหว่างการคาดการณ์กับป้ายกํากับมีขนาดใหญ่ การยกกำลัง 2 จะทําให้ค่า Loss เพิ่มขึ้น เมื่อความแตกต่างมีน้อย (น้อยกว่า 1) การยกกำลัง 2 จะทําให้ผลขาดทุนน้อยลง
เมื่อประมวลผลตัวอย่างหลายรายการพร้อมกัน เราขอแนะนำให้หาค่าเฉลี่ยของค่าสูญเสียในตัวอย่างทั้งหมด ไม่ว่าจะใช้ MAE หรือ MSE
ตัวอย่างการคำนวณการสูญเสีย
เราจะคํานวณการสูญเสีย L2 สําหรับตัวอย่างเดียวโดยใช้เส้นค่าสัมประสิทธิ์การถดถอยที่เหมาะสมที่สุดก่อนหน้านี้ จากเส้นพอดีที่สุด เรามีค่าน้ำหนักและค่าเบี่ยงเบนมาตรฐานดังต่อไปนี้
- $ \small{Weight: -3.6} $
- $ \small{Bias: 30} $
หากโมเดลคาดการณ์ว่ารถที่มีน้ำหนัก 2,370 ปอนด์จะวิ่งได้ 21.5 ไมล์ต่อแกลลอน แต่วิ่งได้ 24 ไมล์ต่อแกลลอน เราจะคำนวณ Loss L2 ดังนี้
| ค่า | สมการ | ผลลัพธ์ |
|---|---|---|
| การคาดการณ์ | $\small{bias + (weight * feature\ value)}$ $\small{30 + (-3.6*2.37)}$ |
$\small{21.5}$ |
| มูลค่าที่แท้จริง | $ \small{ label } $ | $ \small{ 24 } $ |
| อัตราสูญเสีย L2 | $ \small{ (prediction - actual\ value)^2} $ $\small{ (21.5 - 24)^2 }$ |
$\small{6.25}$ |
ในตัวอย่างนี้ อัตราสูญเสีย L2 สำหรับจุดข้อมูลเดียวนั้นคือ 6.25
การเลือกการสูญเสีย
การตัดสินใจว่าจะใช้ MAE หรือ MSE ขึ้นอยู่กับชุดข้อมูลและวิธีที่คุณต้องการจัดการการคาดการณ์บางอย่าง โดยปกติแล้วค่าฟีเจอร์ส่วนใหญ่ในชุดข้อมูลจะอยู่ในช่วงที่ต่างกัน ตัวอย่างเช่น รถยนต์มักจะมีน้ำหนักระหว่าง 2,000 ถึง 5,000 ปอนด์ และวิ่งได้ 8-50 ไมล์ต่อแกลลอน รถที่มีน้ำหนัก 8,000 ปอนด์หรือรถที่วิ่งได้ 100 ไมล์ต่อแกลลอนอยู่นอกช่วงที่พบได้ทั่วไปและจะถือว่าเป็นค่าผิดปกติ
ค่าผิดปกติยังอาจหมายถึงความคลาดเคลื่อนของการคาดการณ์ของโมเดลจากค่าจริงด้วย เช่น 3,000 ปอนด์อยู่ในช่วงน้ำหนักรถทั่วไป และ 40 ไมล์ต่อแกลลอนอยู่ในช่วงการประหยัดเชื้อเพลิงทั่วไป อย่างไรก็ตาม รถ 3,000 ปอนด์ที่วิ่งได้ 40 ไมล์ต่อแกลลอนจะเป็นค่าผิดปกติในแง่ของการคาดการณ์ของโมเดล เนื่องจากโมเดลจะคาดการณ์ว่ารถ 3,000 ปอนด์จะวิ่งได้ 18-20 ไมล์ต่อแกลลอน
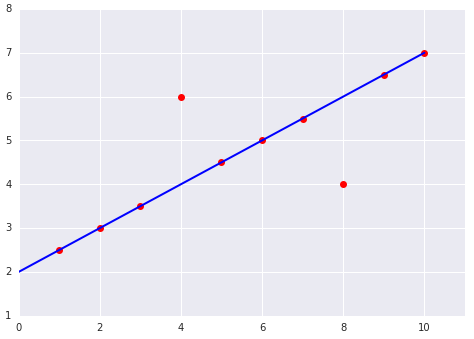
เมื่อเลือกฟังก์ชันการสูญเสียที่ดีที่สุด ให้พิจารณาว่าคุณต้องการให้โมเดลจัดการกับค่าที่ผิดปกติอย่างไร เช่น MSE จะย้ายโมเดลไปทางค่าที่ผิดปกติมากขึ้น ขณะที่ MAE จะไม่ทำเช่นนั้น การสูญเสีย L2 จะมีบทลงโทษสูงกว่ามากสําหรับค่าที่ผิดปกติเมื่อเทียบกับการสูญเสีย L1 ตัวอย่างเช่น รูปภาพต่อไปนี้แสดงโมเดลที่ฝึกโดยใช้ MAE และโมเดลที่ฝึกโดยใช้ MSE เส้นสีแดงแสดงโมเดลที่ผ่านการฝึกอบรมอย่างสมบูรณ์ซึ่งจะใช้ทําการคาดการณ์ ค่าที่ผิดปกติอยู่ใกล้กับรูปแบบที่ฝึกด้วย MSE มากกว่ารูปแบบที่ฝึกด้วย MAE
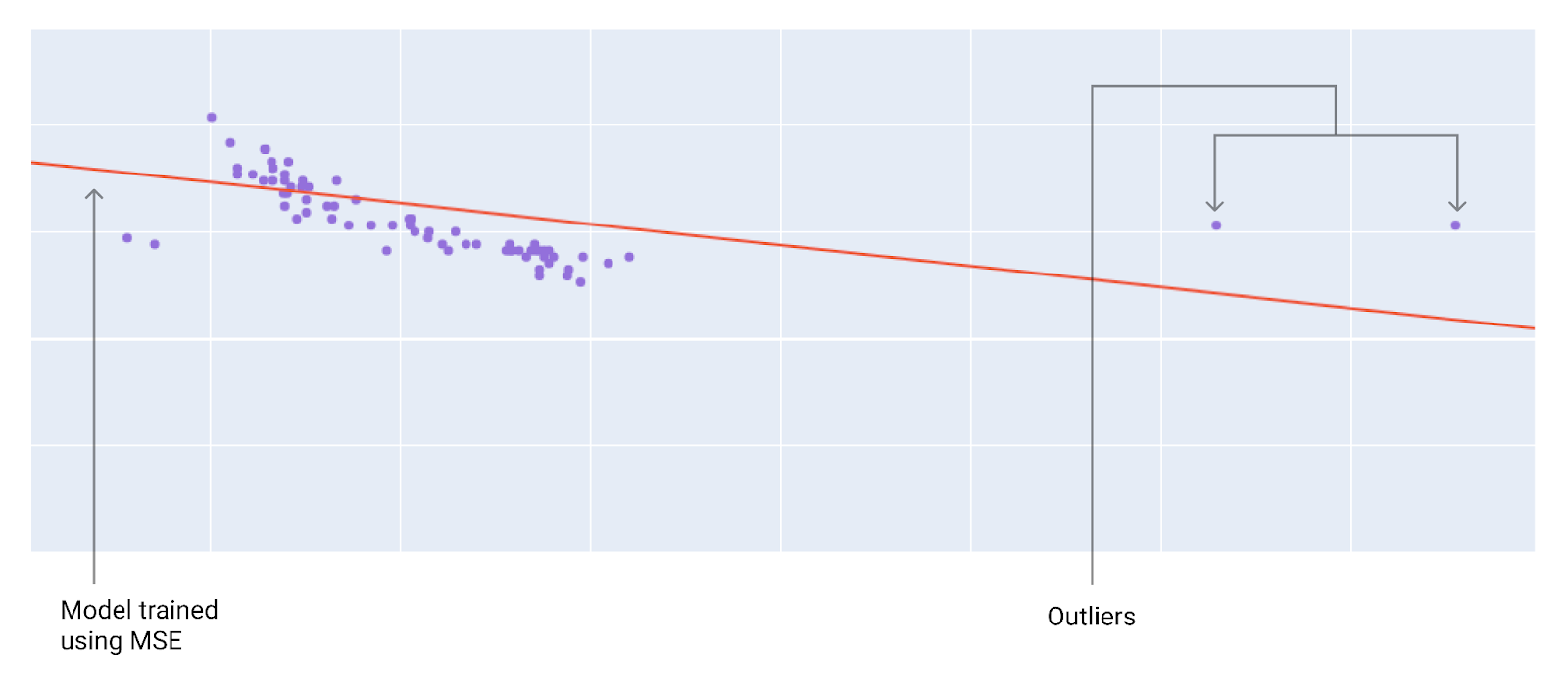
รูปที่ 10 โมเดลที่ฝึกด้วย MSE จะย้ายโมเดลเข้าใกล้ค่าที่ผิดปกติมากขึ้น
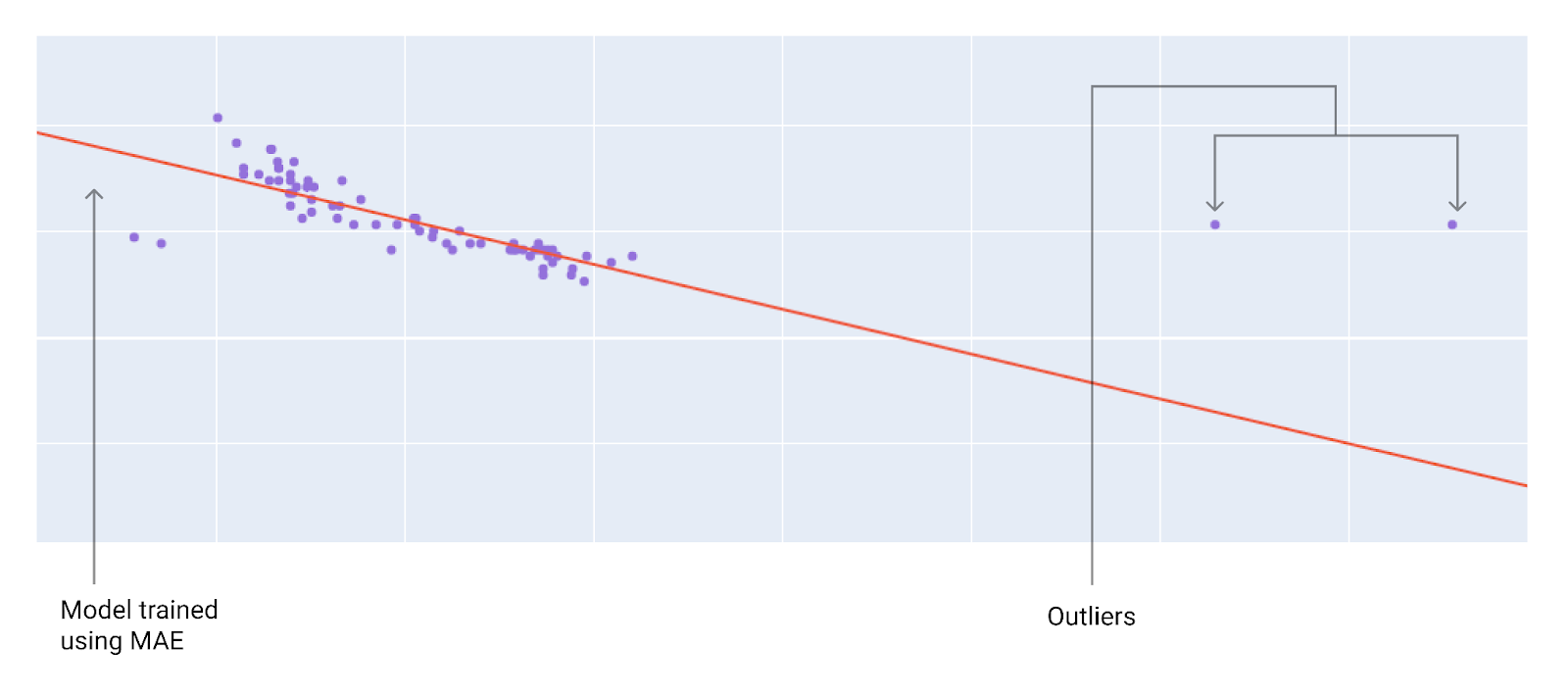
รูปที่ 11 โมเดลที่ฝึกด้วย MAE จะอยู่ห่างจากค่าผิดปกติมากกว่า
โปรดสังเกตความสัมพันธ์ระหว่างรูปแบบกับข้อมูล
MSE โมเดลอยู่ใกล้กับค่าที่ผิดปกติ แต่อยู่ห่างจากจุดข้อมูลอื่นๆ ส่วนใหญ่
MAE โมเดลอยู่ห่างจากค่าที่ผิดปกติ แต่อยู่ใกล้กับจุดข้อมูลอื่นๆ ส่วนใหญ่
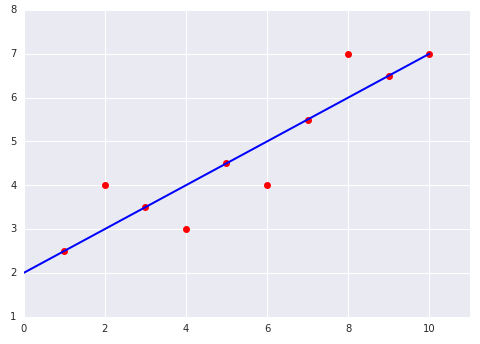
ทดสอบความเข้าใจ
ลองพิจารณาผัง 2 รายการต่อไปนี้
|
|