Um embedding é uma representação vetorial de dados em um espaço de embedding. No geral, um modelo encontra embeddings em potencial projetando o espaço de muitas dimensões dos vetores de dados iniciais em um espaço com menos dimensões. Para ver uma discussão sobre dados de alta dimensão em comparação com dados de baixa dimensão, acesse o módulo sobre Dados categóricos.
Com embeddings, fica mais fácil fazer aprendizado de máquina em grandes vetores de atributos, como os vetores esparsos que representam os alimentos discutidos na seção anterior. Às vezes, as posições relativas de itens no espaço de embedding têm uma relação semântica potencial, mas geralmente o processo de encontrar um espaço com menos dimensões (e as posições relativas nesse espaço) não é interpretável por humanos, e os embeddings resultantes são difíceis de entender.
Contudo, para tentarmos compreender como vetores de embedding representam informações, considere a seguinte representação unidimensional dos alimentos cachorro-quente, pizza, salada, shawarma e borscht, em uma escala de "menos parecido com um sanduíche" a "mais parecido com um sanduíche". A única dimensão é uma medida imaginária da "sanduicheza" dos alimentos.
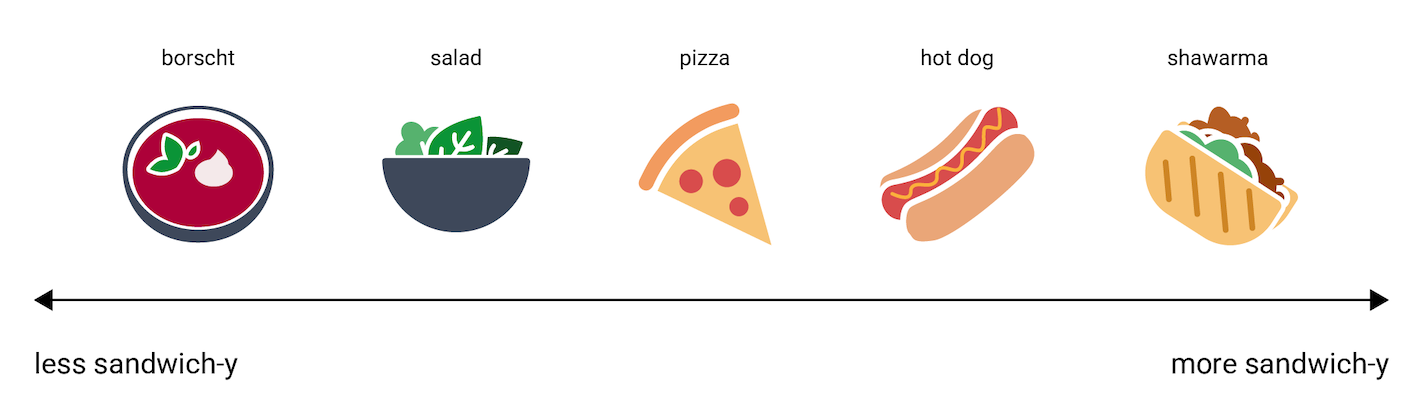
Em que altura dessa linha um
strudel de maçã
se encaixaria? Possivelmente, entre hot dog e shawarma. Mas um strudel
de maçã também parece ter uma dimensão adicional de doçura
ou de "sobremesura" que o diferencia bastante das outras opções.
A figura a seguir representa isso, adicionando uma dimensão de "sobremesura":
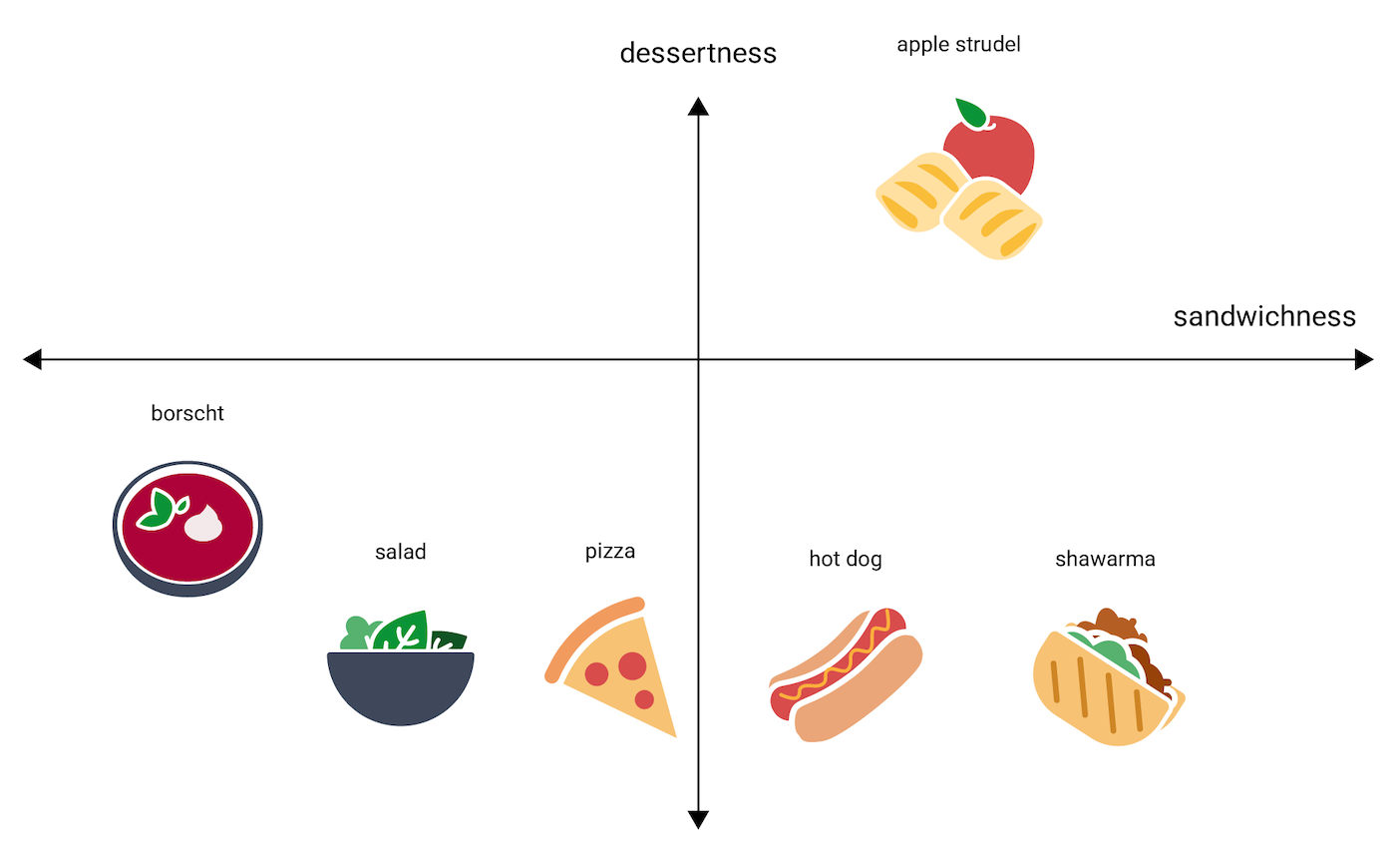
Um embedding representa cada item em um espaço n-dimensional com n números de pontos flutuantes, geralmente no intervalo –1 a 1 ou 0 a 1. O embedding na Figura 3 representa cada alimento em um espaço unidimensional com uma única coordenada, enquanto a Figura 4 representa cada alimento em um espaço bidimensional com duas coordenadas. Na Figura 4, "strudel de maçã" está no quadrante superior direito do gráfico e poderia receber o ponto (0,5; 0,3). O "cachorro-quente", por sua vez, está no quadrante inferior direito do gráfico e poderia receber o ponto (0,2; –0,5).
Em um embedding, a distância entre dois itens pode ser calculada
matematicamente e interpretada como uma medida da semelhança
relativa entre esses dois itens. Duas coisas que estão próximas, como
shawarma e hot dog na Figura 4, são mais estreitamente relacionadas na representação
dos dados feita pelo modelo do que duas coisas mais distantes,
como apple strudel e borscht.
Veja também que, no espaço 2D da Figura 4, apple strudel está bem mais longe
de shawarma e de hot dog do que estaria no espaço unidimensional, o que está de acordo com nossa
intuição: apple strudel não é tão parecido com um cachorro-quente ou um shawarma quanto cachorros-quentes
e shawarmas são parecidos uns com os outros.
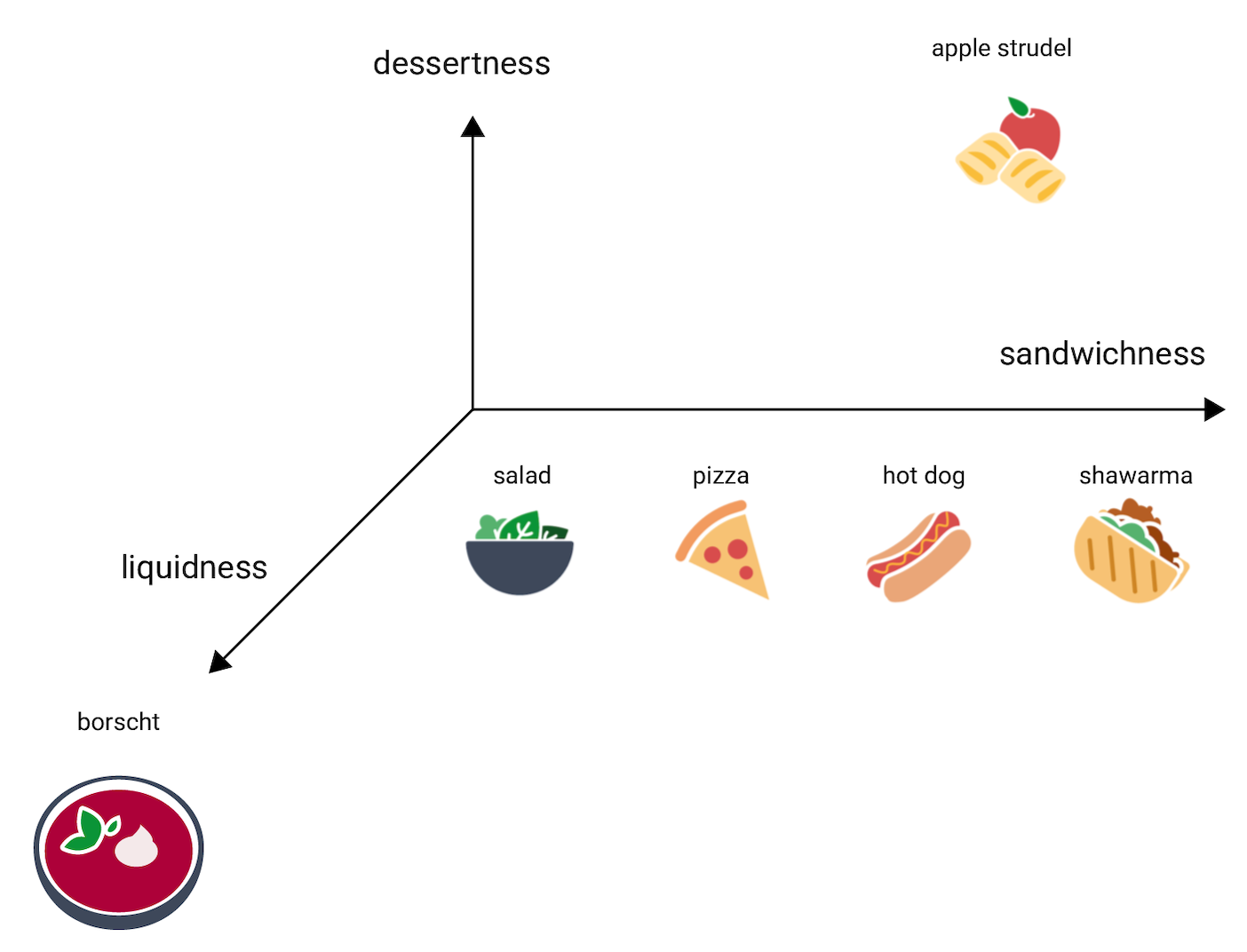
Agora pense no borscht, que é muito mais líquido do que os outros itens. Isso sugere uma terceira dimensão, a liquidez, ou seja, se um alimento é muito ou pouco líquido. Adicionando essa dimensão, os itens poderiam ser representados em 3D assim:
Em que parte desse espaço 3D ficaria um tangyuan? Ele é líquido, como o borscht, e uma sobremesa doce, como o strudel de maçã, e com certeza não é um sanduíche. Esta é uma possível colocação:
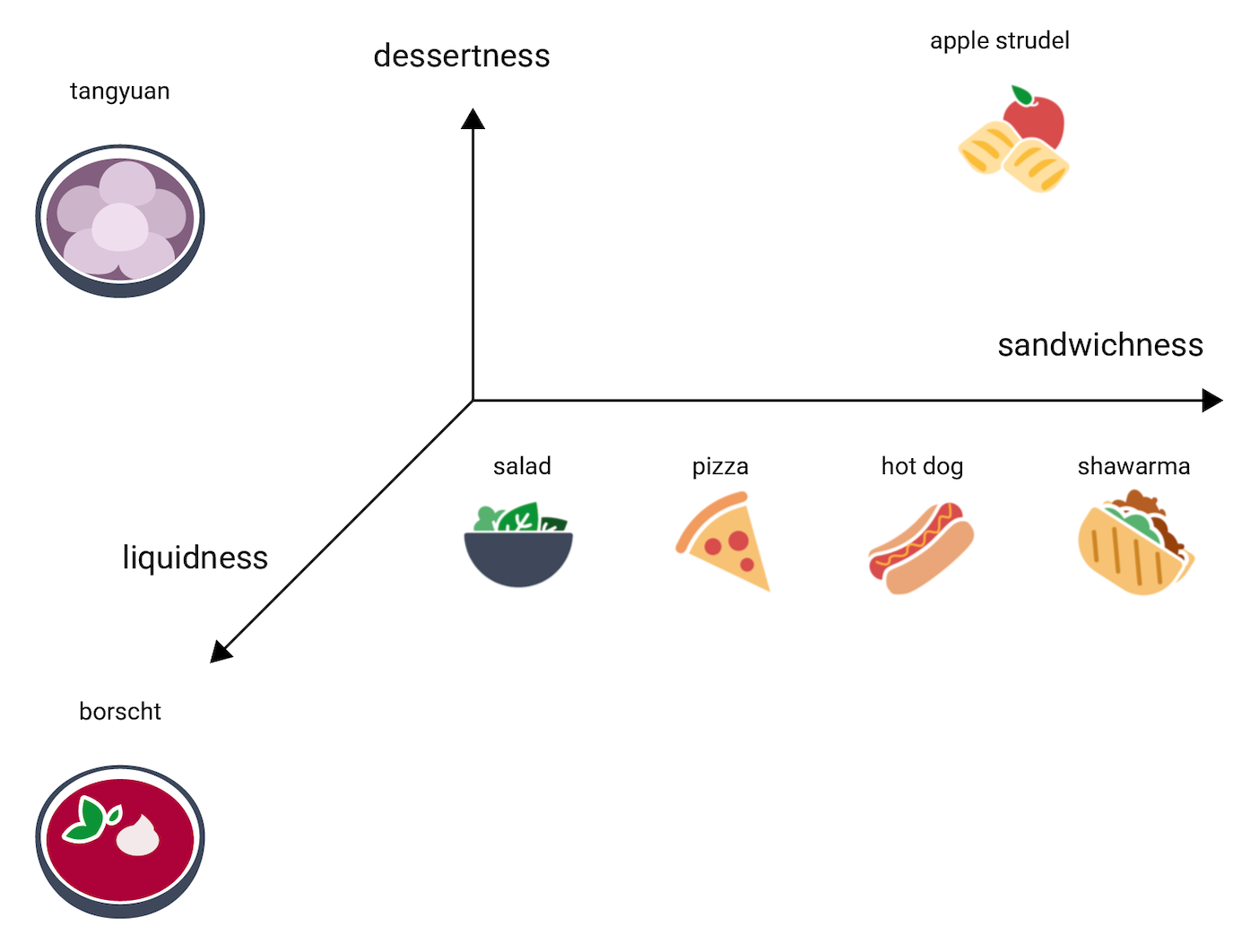
Veja quantas informações são expressas nessas três dimensões. Imagine que adicionamos mais dimensões, como o quanto um alimento pode ser "carnudo" ou "assável". Espaços com quatro, cinco ou mais dimensões são difíceis de visualizar.
Espaços de embedding no mundo real
No mundo real, espaços de embedding têm d dimensões, em que d é muito maior do que 3, mas menor do que a dimensionalidade dos dados. Além disso, as relações entre os pontos de dados não são necessariamente tão intuitivas quanto as que inventamos na ilustração acima. Para embeddings da palavra, d costuma ser 256, 512 ou 10241.
Na prática, o profissional de ML costuma definir a tarefa específica e o número de dimensões de embedding. Então, o modelo tenta organizar os exemplos de treinamento para ficarem próximos em um espaço de embedding com o número especificado de dimensões, ou se ajustar de acordo com o número de dimensões, caso d não seja fixado. As dimensões individuais raramente são tão compreensíveis quanto "sobremesura" ou "liquidez". Às vezes, o que elas "significam" pode ser inferido, mas isso nem sempre é o caso.
Os embeddings geralmente serão específicos a cada tarefa, e vão se diferenciar quando a tarefa for diferente. Por exemplo, os embeddings gerados por um modelo de classificação vegetariano comparado a um não vegetariano serão diferentes dos embeddings gerados por um modelo que sugere pratos com base na hora do dia ou na estação. "Cereal" e "salsicha de café da manhã" provavelmente ficariam próximos no espaço de embedding de um modelo "horário do dia", mas bem longe no espaço de embedding do modelo vegetariano versus não vegetariano, por exemplo.
Embeddings estáticos
Apesar de os embeddings se diferenciarem de acordo com a tarefa, uma delas tem uma aplicação generalizada: prever o contexto de uma palavra. Modelos treinados para prever o contexto de uma palavra presumem que palavras que aparecem em contextos semelhantes têm relações semânticas. Por exemplo, dados de treinamento que incluem as frases "Eles desceram o Grand Canyon montados em um burro" e "Eles desceram o cânion montados em um cavalo" sugerem que "cavalo" aparece em contextos semelhantes a "burro". Embeddings baseados em semelhança semântica funcionam bem para várias tarefas linguísticas gerais.
Apesar de ser um exemplo antigo, largamente ultrapassado por outros modelos, o modelo
word2vec continua útil para uma explicação. word2vec é treinado com base em um
corpus de documentos para obter um único
embedding global por palavra. Quando cada palavra ou ponto de dados tem um único vetor de embedding,
chamamos isso de embedding estático. O vídeo a seguir apresenta
uma ilustração simplificada do treinamento do word2vec.
Pesquisas sugerem que, depois de treinados, esses embeddings estáticos codificam algum grau de informação semântica, principalmente em relações entre palavras. Ou seja, palavras usadas em contextos semelhantes ficarão mais próximas umas das outras no espaço de embedding. Os vetores de embedding específicos que são gerados vão depender do corpus usado no treinamento. Consulte o artigo em inglês de T. Mikolov et al (2013), "Efficient estimation of word representations in vector space", para saber mais.
-
François Chollet, Deep Learning with Python (Shelter Island, NY: Manning, 2017), 6.1.2. ↩