임베딩은 임베딩 공간에 있는 데이터의 벡터 표현입니다. 일반적으로 모델은 초기 데이터 벡터의 고차원 공간을 저차원 공간으로 투영하여 잠재적인 임베딩을 찾습니다. 고차원 데이터와 저차원 데이터에 관한 자세한 내용은 범주형 데이터 모듈을 참고하세요.
임베딩을 사용하면 큰 특성 벡터(예: 직전 섹션에서 살펴본 식사 항목을 나타내는 희소 벡터)에 대해 머신러닝을 진행하기가 쉬워집니다. 임베딩 공간에 있는 항목들의 상대 위치가 시맨틱 관계를 가지는 경우도 있지만, 많은 경우 저차원 공간과 그 공간에서의 상대 위치를 찾는 과정은 사람이 해석할 수 없으며, 결과로 생성되는 임베딩을 이해하기가 어렵습니다.
그렇긴 해도, 임베딩 벡터가 정보를 나타내는 방식을 대략적으로나마 알아보기 위해, 핫도그(hot dog), 피자(pizza), 샐러드(salad), 샤와르마(shawarma), 보르시(borscht)라는 음식들을 '전혀 샌드위치 같지 않음'부터 '가장 샌드위치 같음'까지의 축 위에 늘어놓은 1차원 표현을 살펴보겠습니다. 이 하나의 차원은 '샌드위치다움'이라는 허구의 척도입니다.
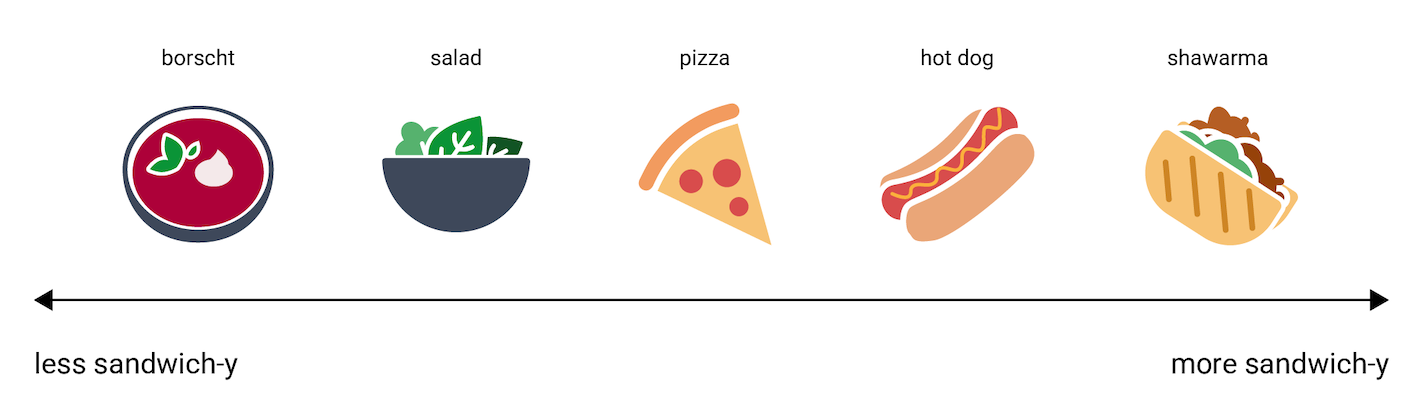
그렇다면 아펠슈트루델(apple strudel)은 이 선에서 어디에 위치할까요? 논쟁의 여지가 있겠지만 아마도 hot dog와 shawarma 사이에 올 수 있을 것입니다. 그런데 아펠슈트루델에는 달콤함 또는 디저트다움이라는 추가적인 차원이 있다고도 볼 수 있으므로 다른 옵션들과 특성이 무척 달라집니다.
다음 그림은 '디저트다움' 차원을 추가하여 이를 시각화한 것을 보여줍니다.
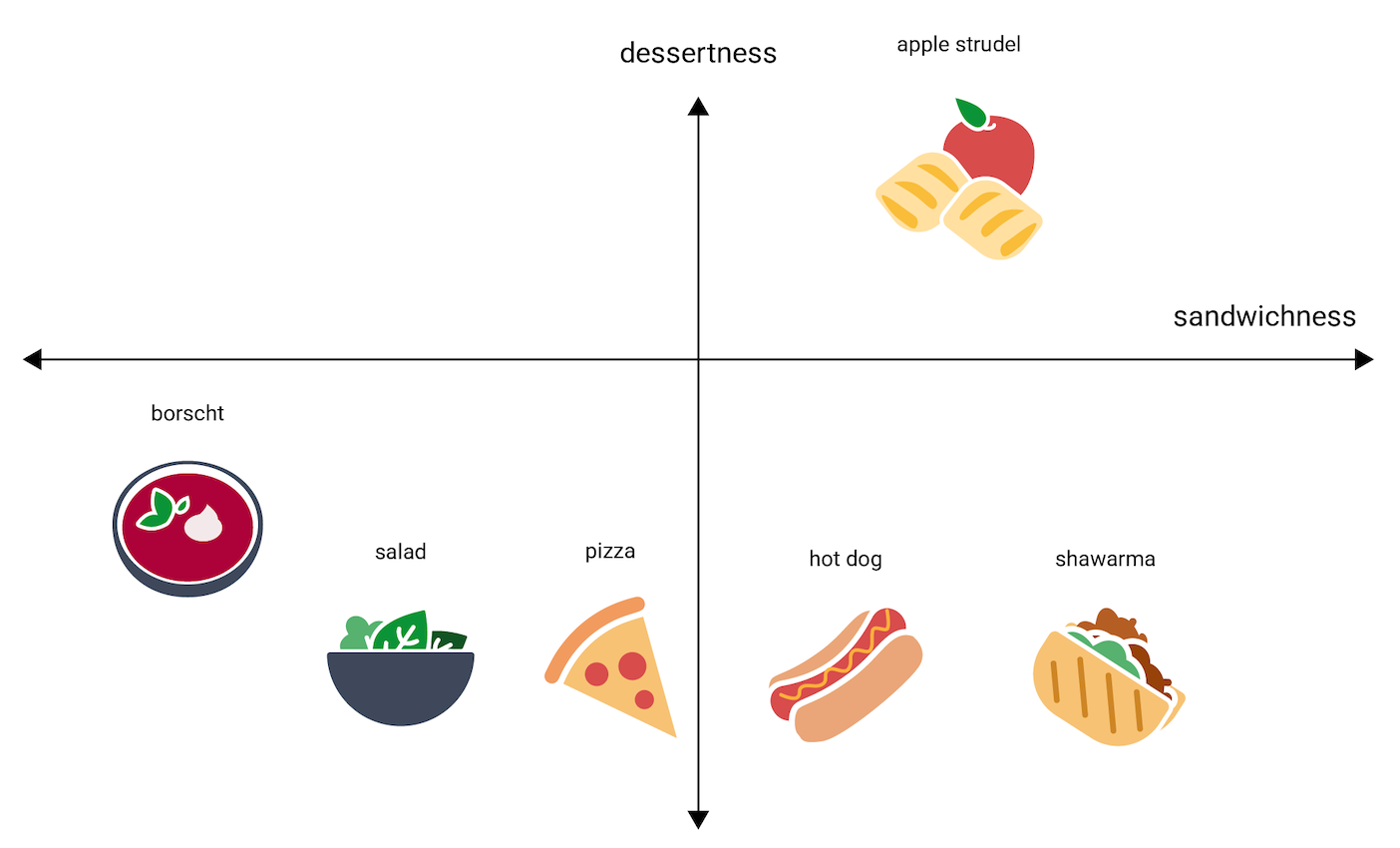
임베딩은 보통 –1~1 또는 0~1 사이의 부동 소수점 n개를 가지는 n차원 공간에서 각 항목을 나타냅니다. 그림 3의 임베딩은 각 음식을 하나의 좌표를 갖는 1차원 공간에서 각 음식을 나타내고, 그림 4는 두 개의 좌표를 갖는 2차원 공간에서 각 음식을 나타냅니다. 그림 4에서 '아펠슈트루델'은 그래프의 오른쪽 상단 사분면에 있고 점 (0.5, 0.3)이 할당될 수 있는 반면 '핫도그'는 그래프의 오른쪽 하단 사분면에 있고 점 (0.2, –0.5)가 할당될 수 있습니다.
임베딩에서 두 항목 사이의 거리는 산술적으로 계산될 수 있으며, 이 거리는 두 항목 간의 상대적 유사도에 대한 척도로 해석될 수 있습니다. 그림 4의 shawarma와 hot dog 같이 서로 가까이 있는 두 항목은 apple strudel과 borscht 같이 서로 멀리 있는 두 항목보다 모델의 데이터 표현에서 더 밀접하게 관련되어 있습니다.
그림 4의 2차원 공간에서 apple strudel은 shawarma와 hot dog로부터 1차원 공간에서 측정했을 경우의 거리보다 더 멀리 있는 것을 볼 수 있습니다. 이는 apple strudel와 핫도그 또는 샤와르마 간의 유사도는 핫도그와 샤와르마 간의 유사도보다 작을 것이라는 직관에 부합합니다.
이번에는 다른 항목에 비해 수프 같은 특징이 있는 보르시를 살펴보겠습니다. 수프 같다는 특징이 등장했으니 음식이 수프 같은 정도를 나타내는 세 번째 차원인 수프다움이 필요하겠죠. 이 차원을 추가하면 항목들은 3차원에서 다음과 같이 시각화될 수 있습니다.
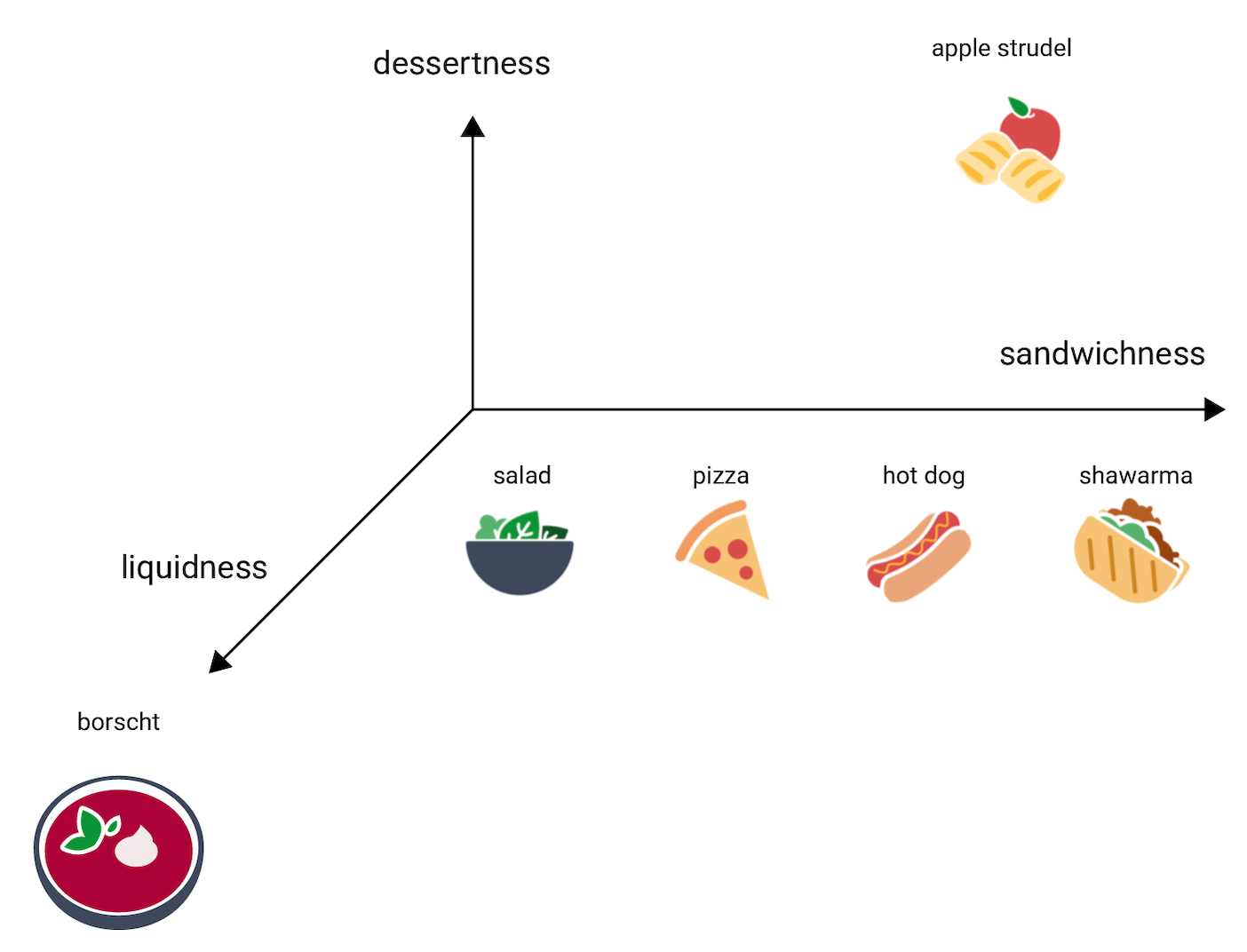
그렇다면 탕위안(tangyuan)은 이 3차원 공간에서 어디에 위치할까요? 탕위안은 보르시처럼 수프에 가깝고, 아펠슈트루델처럼 달콤한 디저트이며, 어떻게 보아도 샌드위치는 아닙니다. 따라서 다음과 같이 배치할 수 있을 것입니다.
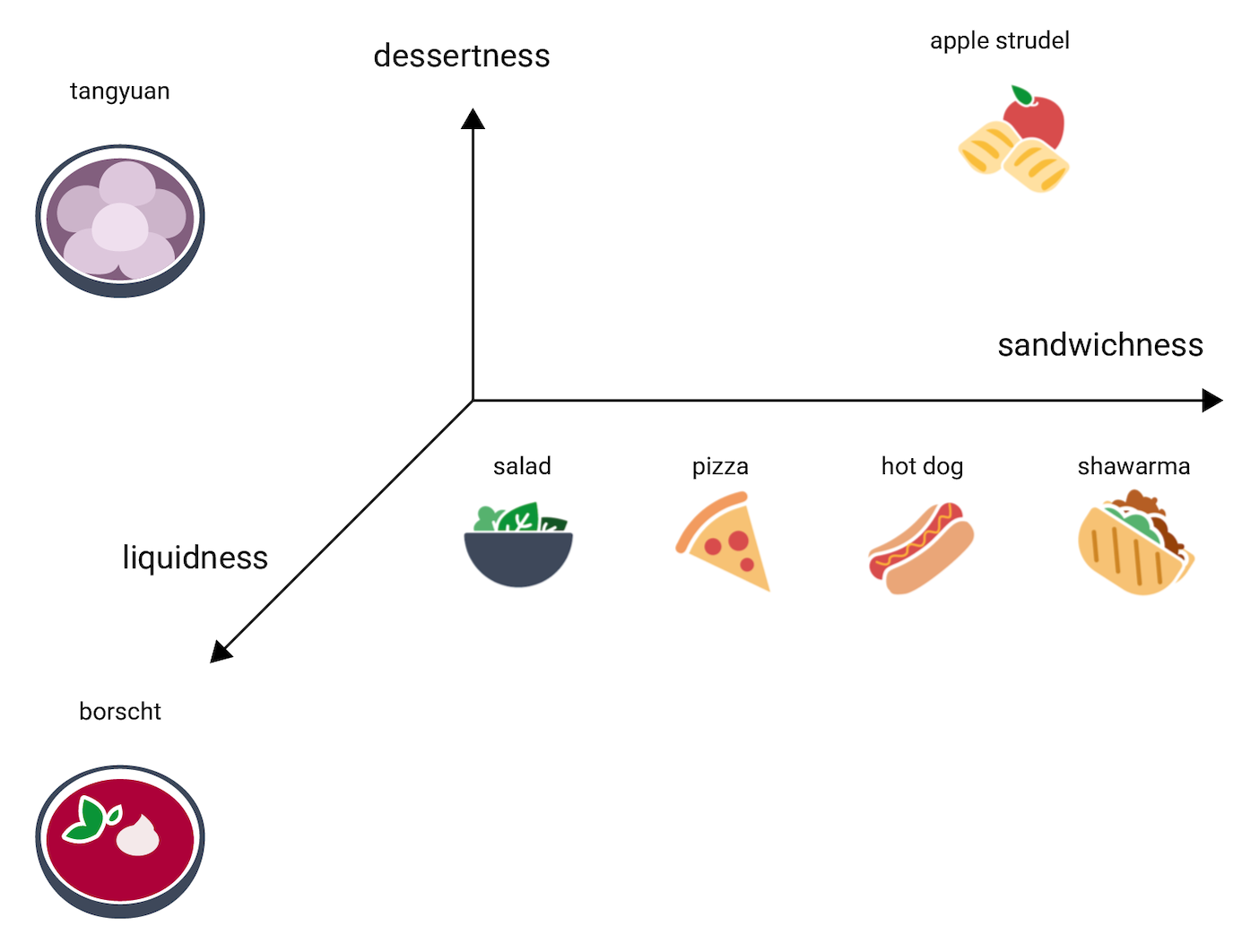
이 세 개의 차원으로 얼마나 많은 정보가 표현되고 있는지 살펴보세요. 여기에 음식의 '고기다움'이나 '구움 정도' 같은 더 많은 차원을 추가하는 것도 가능할 것입니다. 물론 4차원, 5차원 또는 그보다 고차원 공간은 시각화하기 어렵겠죠.
실제 세계의 임베딩 공간
실제 세계에서 임베딩 공간은 d차원입니다. 여기서 d는 3보다 훨씬 크고 데이터의 차원성보다는 작습니다. 그리고 여러 데이터 포인트 간의 관계는 위에서 살펴본 인공적인 예시만큼 직관적이지 않습니다. (단어 임베딩의 경우 d는 보통 256, 512 또는 1024입니다.1)
실전에서는 보통 ML 실무자가 구체적인 태스크와 임베딩 차원의 수를 설정합니다. 그러면 모델이 지정된 차원의 수를 사용하여 임베딩 공간에서 학습 예시들이 서로 가깝게 배치되도록 시도하거나, d가 고정된 수가 아닌 경우 차원의 수를 튜닝합니다. 이때 개별 차원들은 '디저트다움'이나 '수프다움'처럼 쉽게 이해할 수 있는 경우가 매우 드뭅니다. 차원들이 무엇을 '의미'하는지 추론할 수 있는 경우도 있긴 하지만, 항상 그런 것은 아닙니다.
임베딩은 일반적으로 해당 태스크에 특화되어 있으며, 태스크가 달라지면 임베딩도 달라집니다. 예를 들어, 채식 요리와 비 채식 요리를 구분하는 분류 모델이 생성한 임베딩은 하루 중 식사 시간이나 계절에 따라 요리를 추천하는 모델이 생성한 임베딩과 다를 것입니다. '시리얼'과 '아침 식사용 소시지'는 하루 중 식사 시간에 따라 요리를 추천하는 모델의 임베딩 공간에서는 서로 가깝겠지만 채식 요리와 비 채식 요리를 구분하는 모델의 임베딩 공간에서는 서로 멀 것입니다.
정적 임베딩
임베딩이 태스크에 따라 달라지는 것은 사실이지만, 범용성 있는 태스크도 있습니다. 바로 단어의 컨텍스트를 예측하는 태스크입니다. 단어의 컨텍스트를 예측하도록 학습된 모델은 비슷한 컨텍스트에서 등장하는 단어들은 시맨틱 관계를 갖는다고 가정합니다. 예를 들어, 'They rode a burro down into the Grand Canyon'이라는 문장과 'They rode a horse down into the canyon'이라는 문장을 둘 다 포함하는 학습 데이터는 'horse'는 'burro'와 비슷한 컨텍스트에서 등장한다는 사실을 암시합니다. 실제 결과를 보면 시맨틱 유사성을 기반으로 하는 임베딩은 여러 일반적인 언어 태스크에서 효과적으로 작동합니다.
비교적 오래되었고 거의 다른 모델에 의해 대체되긴 했으나, word2vec 모델은 이러한 상황을 설명하는 데 효과적입니다. word2vec은 수많은 문서로 된 코퍼스를 학습하여 단어당 하나의 전역 임베딩을 획득합니다. 각 단어 또는 데이터 포인트가 하나의 임베딩 벡터를 갖는 경우를 정적 임베딩이라고 합니다. 다음 동영상에서는 word2vec 학습의 단순화된 예시를 단계별로 설명합니다.
연구 결과를 보면 학습된 정적 임베딩은 특히 단어와 단어 사이의 관계에서 어느 정도의 시맨틱 정보를 인코딩한다고 합니다. 즉, 비슷한 컨텍스트에서 사용되는 단어들은 임베딩 공간에서 서로 가까이 있습니다. 구체적으로 어떤 임베딩이 생성되는지는 학습에 사용된 코퍼스에 따라 달라집니다. 자세한 내용은 T. Mikolov et al (2013), 'Efficient estimation of word representations in vector space'를 참고하세요.
-
François Chollet, Deep Learning with Python (Shelter Island, NY: Manning, 2017), 6.1.2. ↩