Embedding adalah representasi vektor dari data dalam ruang sematan. Umumnya, sebuah model menemukan calon embedding dengan memproyeksikan ruang berdimensi tinggi dari vektor data awal ke ruang berdimensi lebih rendah. Untuk melihat diskusi tentang perbedaan antara data berdimensi tinggi dan rendah, lihat modul Data Kategorik.
Embedding memudahkan penerapan machine learning pada vektor fitur berukuran besar, seperti vektor renggang yang merepresentasikan item makanan yang dibahas di bagian sebelumnya. Terkadang, posisi relatif item dalam ruang sematan berpotensi memiliki hubungan semantik. Namun sering kali, proses penentuan ruang berdimensi rendah dan posisi relatif dalam ruang tersebut tidak dapat ditafsirkan oleh manusia, sehingga embedding yang dihasilkan sulit dipahami.
Meskipun begitu, agar mudah dipahami, serta memberikan gambaran bagaimana vektor embedding merepresentasikan informasi, perhatikan representasi makanan satu dimensi berikut hot dog, pizza, salad, shawarma, dan borscht, pada skala "paling tidak mirip roti lapis" hingga "paling mirip roti lapis". Dimensi tunggalnya adalah ukuran imajiner "roti lapis".
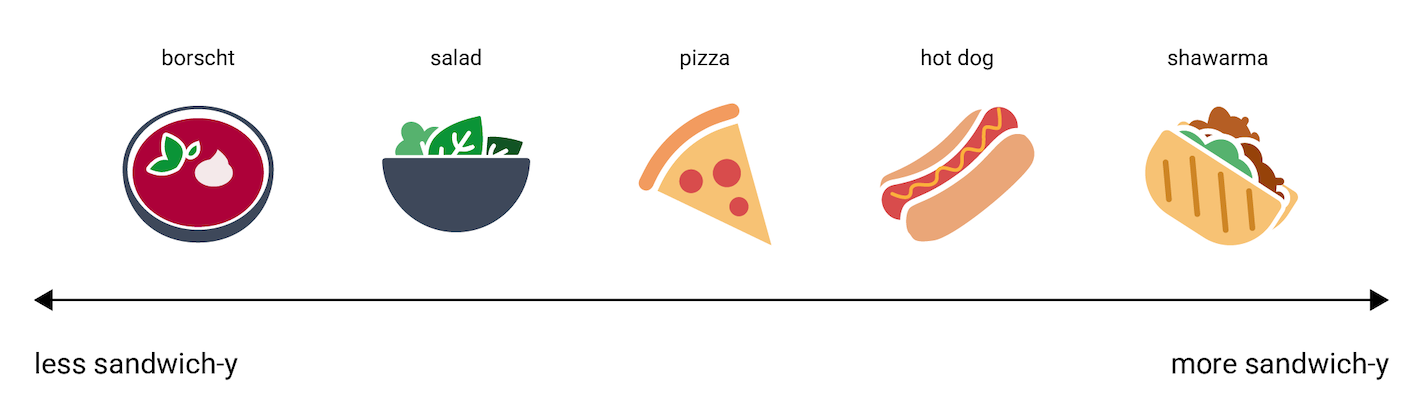
Di mana posisi
strudel apel
pada sumbu tersebut? Menurut saya, mungkin bisa ditempatkan di antara hot dog dan shawarma. Namun, strudel
apel tampaknya juga memiliki dimensi lain yaitu makanan manis
atau hidangan penutup yang menjadikannya sangat berbeda dari opsi lainnya.
Gambar berikut memvisualisasikannya dengan menambahkan dimensi "hidangan penutup":

Embedding merepresentasikan setiap item dalam ruang dimensi n dengan angka floating point n (biasanya dalam rentang –1 hingga 1 atau 0 hingga 1). Embedding pada Gambar 3 merepresentasikan setiap makanan dalam ruang satu dimensi dengan satu koordinat, sedangkan Gambar 4 merepresentasikan setiap makanan dalam ruang dua dimensi dengan dua koordinat. Di Gambar 4, "strudel apel" berada di kuadran kanan atas grafik dan dapat ditetapkan ke titik (0,5, 0,3), sedangkan "hot dog" berada di kuadran kanan bawah grafik dan dapat ditetapkan ke titik (0,2, –0,5).
Dalam sebuah embedding, jarak antara dua item apa saja dapat dihitung
secara matematis, dan dapat ditafsirkan sebagai ukuran kemiripan relatif
antara kedua item tersebut. Dua hal yang saling berdekatan, seperti
shawarma dan hot dog di Gambar 4, menunjukkan keduanya berkaitan erat dalam representasi data
model dibandingkan dua hal yang saling
berjauhan, seperti apple strudel dan borscht.
Perhatikan juga embedding dalam ruang 2D pada Gambar 4, selisih jarak apple strudel
dari shawarma dan hot dog akan sangat jauh dibandingkan jaraknya dalam ruang 1D, yang selaras dengan
intuisi bahwa apple strudel tidak semirip hot dog atau shawarma, tidak seperti hot
dog dan shawarma yang memang mirip satu sama lain.
Sekarang perhatikan borscht, yang sifatnya paling berkuah dibandingkan item makanan lain. Hal ini memicu munculnya dimensi ketiga, makanan berkuah, atau seberapa banyak kuah sebuah makanan. Dengan menambahkan dimensi ketiga, item tersebut dapat divisualisasikan secara 3D dengan cara berikut:

Di mana posisi tangyuan pada ruang 3D ini? Sifatnya seperti sup, mirip borscht, dan makanan manis sebagai hidangan penutup, mirip strudel apel, dan yang pasti bukan roti lapis. Penempatannya mungkin sebagai berikut:

Perhatikan seberapa banyak informasi yang Anda peroleh dari tiga dimensi ini. Anda juga bisa menambahkan, misalnya, lebih banyak dimensi seperti seberapa banyak kandungan dagingnya atau seberapa matang sebuah makanan, walaupun makin tinggi dimensinya (4D, 5D, dst.) makin sulit juga untuk divisualisasikan.
Ruang sematan dunia nyata
Di dunia nyata, ruang sematan adalah dimensi d, dengan d jauh lebih tinggi dari 3, meskipun tetap lebih rendah dari dimensi data, dan hubungan antartitik data belum tentu seintuitif contoh ilustrasi di atas. (Untuk embedding kata, d sering kali berjumlah 256, 512, atau 1024.1)
Dalam praktiknya, praktisi ML biasanya menetapkan tugas tertentu dan jumlah dimensi embedding. Kemudian, model akan mencoba mengatur contoh pelatihan yang posisinya berdekatan dalam ruang sematan dengan jumlah dimensi yang ditetapkan, atau menyesuaikan dengan jumlah dimensinya, jika d tidak ditetapkan. Tiap-tiap dimensinya sering kali tidak mudah dipahami, tidak seperti "hidangan penutup" atau "makanan berkuah". Mungkin terkadang "makna"-nya dapat disimpulkan, tetapi tidak selalu demikian.
Embedding biasanya akan ditujukan spesifik untuk tugas tertentu, dan akan berbeda satu sama lain jika tugasnya berbeda. Misalnya, embedding yang dibuat oleh mode klasifikasi vegetarian versus nonvegetarian akan berbeda dengan embedding yang dibuat oleh model yang menilai makanan berdasarkan musim atau waktu untuk memakannya. Misalnya, "sereal" dan "sosis sarapan" mungkin akan berdekatan dalam ruang sematan berdasarkan model waktu untuk memakannya, tetapi akan sangat berjauhan dalam ruang sematan berdasarkan model vegetarian versus nonvegetarian.
Embedding statis
Meskipun embedding berbeda dari satu tugas ke tugas lain, satu tugas memiliki beberapa karakteristik yang berlaku secara umum: memprediksi konteks sebuah kata adalah kuncinya. Model dilatih untuk memprediksi konteks sebuah kata, dengan asumsi bahwa kelompok kata yang muncul dalam konteks yang mirip memang berkaitan secara semantik. Misalnya, data pelatihan yang berisi kalimat "Mereka turun ke Grand Canyon dengan menunggangi seekor keledai." dan "Mereka turun ke dalam ngarai dengan menunggangi seekor kuda." menyiratkan bahwa "kuda" muncul dalam konteks yang mirip dengan "keledai". Ternyata, embedding yang didasarkan pada kemiripan semantiknya cocok digunakan untuk banyak tugas bahasa umum.
Meskipun ini contoh lama, dan kebanyakan sudah tergantikan oleh model lain, model
word2vec tetap bagus untuk dijadikan ilustrasi. word2vec melatih sebuah
korpus dokumen untuk memperoleh satu
embedding global per kata. Setiap kata atau titik data yang memiliki satu vektor
embedding disebut embedding statis. Video berikut menjelaskan
lewat ilustrasi pelatihan word2vec yang sudah disederhanakan.
Riset menunjukkan bahwa embedding statis ini, setelah dilatih, mengenkode sejumlah informasi semantik, terutama dalam hubungan antarkata. Yaitu, kata yang digunakan dalam konteks yang mirip akan berdekatan dalam ruang sematan. Vektor embedding spesifik yang dihasilkan akan bergantung pada korpus yang digunakan untuk pelatihan. Lihat detailnya di T. Mikolov et al (2013), "Efficient estimation of word representations in vector space".
-
François Chollet, Deep Learning with Python (Shelter Island, NY: Manning, 2017), 6.1.2. ↩