इस सेक्शन में ऐसे कई तरीके दिए हैं जिनसे एंबेड करने की प्रोसेस पूरी की जा सकती है. साथ ही, इससे स्टैटिक डेटा को संदर्भ के हिसाब से एंबेड करने का तरीका भी समझा जा सकता है.
डाइमेंशन कम करने वाली तकनीकें
गणित की ऐसी कई तकनीकें हैं जिनकी मदद से, ज़्यादा डाइमेंशन वाले स्पेस में मौजूद ज़रूरी डेटा को कम डाइमेंशन वाले स्पेस में स्टोर किया जा सकता है. इसे इस तरह समझा जा सकता है कि इनमें से किसी भी तकनीक का इस्तेमाल करके, मशीन लर्निंग से जुड़े सिस्टम के लिए एंबेड करने की प्रोसेस को तैयार किया जा सकता है.
उदाहरण के लिए, मुख्य कॉम्पोनेंट के विश्लेषण (पीसीए) की तकनीक का इस्तेमाल, शब्दों को एंबेड करने के लिए किया गया है. पीसीए, शब्दों की सूची जैसे वेक्टर में, ऐसे डाइमेंशन ढूंढने की कोशिश करता है जो एक-दूसरे से बहुत ज़्यादा मेल खाते हैं. फिर ये, मिलते-जुलते डाइमेंशन को एक ही डाइमेंशन में स्टोर करता है.
न्यूरल नेटवर्क के हिस्से के तौर पर एंबेड करने की प्रोसेस को ट्रेन करना
आपके पास अपने टास्क को पूरा करने के लिए, न्यूरल नेटवर्क को ट्रेन करने के दौरान एंबेड करने की प्रोसेस को तैयार करने की सुविधा होती है. इससे, खास आपके सिस्टम की ज़रूरतों के हिसाब से एंबेड करने की प्रोसेस को तैयार करने में मदद मिलती है. हालांकि, एंबेड करने की प्रोसेस को अलग से ट्रेन करने के मुकाबले इसमें ज़्यादा समय लग सकता है.
आम तौर पर, आपके पास अपने न्यूरल नेटवर्क में d साइज़ की एक छिपी हुई लेयर बनाने का विकल्प होता है. इसे एंबेड करने की प्रोसेस को स्टोर करने के लिए बनी लेयर कहते हैं. d से यह पता चलता है कि उस लेयर में कितने नोड हैं और एंबेड करने की प्रोसेस को स्टोर करने की स्पेस में कितने डाइमेंशन हैं. एंबेड करने की प्रोसेस को स्टोर करने के लिए बनी इस लेयर को, किसी छिपी हुई लेयर और डेटासेट की किसी अन्य विशेषता के साथ जोड़कर इस्तेमाल किया जा सकता है. हर डीप न्यूरल नेटवर्क की तरह, इस ट्रेनिंग के दौरान भी मॉडल के पैरामीटर ऑप्टिमाइज़ होंगे, ताकि नेटवर्क की आउटपुट वाली लेयर तक आते-आते नोड की संख्या कम न हो.
खाने की चीज़ों का सुझाव देने से जुड़े हमारे उदाहरण में, हमारा मकसद यह अनुमान लगाना है कि खाने में उपयोगकर्ता की मौजूदा पसंदीदा चीज़ों के आधार पर, उसे खाने में और कौनसी चीज़ें पसंद आएंगी. इसके लिए सबसे पहले हम, उपयोगकर्ता की पांच सबसे पसंदीदा खाने की चीज़ों के बारे में अन्य जानकारी इकट्ठा कर सकते हैं. फिर हम इस टास्क को सुपरवाइज़्ड लर्निंग से जुड़ी समस्या के तौर पर मॉडल कर सकते हैं. हम रैंडम तरीके से, खाने की इन पांच चीज़ों में से चार को फ़ीचर डेटा और पांचवी को पॉज़िटिव लेबल के तौर पर सेट करते हैं. हमारा मॉडल इस लेबल का अनुमान लगाने की कोशिश करता है. इससे हमारा मॉडल, सॉफ़्टमैक्स लॉस का इस्तेमाल करके, बेहतर अनुमान लगाने के लिए ऑप्टिमाइज़ होता है.
ट्रेनिंग के दौरान न्यूरल नेटवर्क मॉडल, छिपी हुई पहली लेयर में मौजूद नोड की सही वैल्यू समझ लेता है. यह लेयर, एंबेड करने की प्रोसेस को स्टोर करने के लिए बनी लेयर के तौर पर काम करती है. उदाहरण के लिए, अगर छिपी हुई इस पहली लेयर में तीन नोड हैं, तो हो सकता है कि मॉडल यह तय करे कि सैंडविच जैसा होना, मिठास, और तरल होना, खाने की इन चीज़ों के मुख्य तीन डाइमेंशन हैं. इमेज 12 में, "हॉट डॉग" के लिए वन-हॉट तरीके से एन्कोड की गई इनपुट वैल्यू को, तीन डाइमेंशन वाले वेक्टर में बदलकर दिखाया गया है.
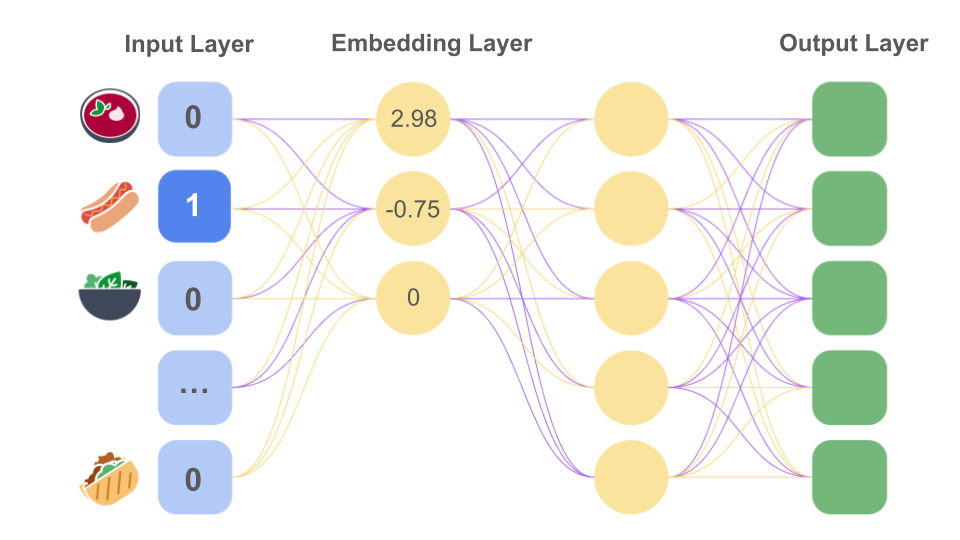
hot dog को वन-हॉट तरीके से एन्कोड करके,
डीप न्यूरल नेटवर्क को इनपुट के रूप में दिया गया है. एंबेड करने की प्रोसेस को स्टोर करने के लिए बनी एक लेयर, इस इनपुट को
तीन डाइमेंशन वाले एंबेड किए जा रहे वेक्टर
[2.98, -0.75, 0] में बदल देती है.
मॉडल की ट्रेनिंग के दौरान, एंबेड करने की प्रोसेस को स्टोर करने के लिए बनी लेयर में मौजूद वैल्यू इस तरह से ऑप्टिमाइज़ की जाएंगी कि मिलते-जुलते एंबेड किए जा रहे वेक्टर, वेक्टर स्पेस में आस-पास रहें. जैसा कि पहले बताया गया था, आम तौर पर असली मॉडल, एंबेड करने की प्रोसेस के लिए जो डाइमेंशन चुनते हैं वे उदाहरण में दिए गए डाइमेंशन जितने सरल या आसानी से समझ में आने वाले नहीं होते.
संदर्भ के हिसाब से एंबेड करना
word2vec वाले स्टैटिक तरीके से एंबेड किए जा रहे वेक्टर के इस्तेमाल में एक कमी यह है कि अलग-अलग संदर्भों
में शब्दों के मतलब अलग हो सकते हैं. सिर्फ़ "हां" और "हां, क्यों नहीं" का मतलब,
एक-दूसरे से बिलकुल अलग होता है. "पोस्ट" शब्द के कई मतलब हो सकते हैं. जैसे, "मेल",
"मेल में कुछ शामिल करना", "ईयररिंग के पीछे का हिस्सा", "वह निशान जहां घोड़ों की दौड़ खत्म होती है",
"पोस्टप्रोडक्शन या प्रोडक्शन के बाद के चरण", "खंभा", "बोर्ड पर सूचना लगाना", "गार्ड या
सैनिक तैनात करना" या "इसके बाद" जैसी कई अन्य चीज़ें.
हालांकि, स्टैटिक तरीके से एंबेड करने की प्रोसेस में हर शब्द को, वेक्टर स्पेस में
एक ही पॉइंट के ज़रिए दिखाया जाता है, फिर चाहे उसके कितने ही मतलब हों.
पिछली यूनिट में
आपने यह देखा था कि स्टैटिक तरीके से एंबेड किए जा रहे नारंगी शब्द के इस्तेमाल में
क्या दिक्कतें आ सकती हैं. यह एक रंग भी हो सकता है और फल भी. स्टैटिक तरीक से
एंबेड करने की एक ही प्रोसेस होने की वजह से, word2vec वाले डेटासेट में मॉडल को ट्रेन करने पर, नारंगी हमेशा
जूस के मुकाबले, रंगों के ज़्यादा करीब होगा.
संदर्भ के हिसाब से एंबेड करने की प्रोसेस, इसी कमी को दूर करने के लिए तैयार की गई हैं. संदर्भ के हिसाब से एंबेड करने की प्रोसेस, किसी शब्द को एंबेड करने की अलग-अलग प्रोसेस की मदद से दिखाती हैं. इनमें उस शब्द और उसके आस-पास के शब्दों के बारे में जानकारी होती है. इसलिए, डेटासेट में नारंगी शब्द के लिए एंबेड करने की प्रोसेस, हर यूनीक वाक्य जिसमें यह शब्द आएगा उसके लिए अलग होगी.
संदर्भ के हिसाब से एंबेड करने की प्रोसेस को तैयार करने की कुछ तकनीकें, जैसे कि
ELMo में, उदाहरण के तौर पर दी गई स्टैटिक
तरीके से किए जा रहे एंबेड में बदली जाती हैं. एंबेड करने की यह प्रोसेस, किसी वाक्य के किसी शब्द के लिए word2vec वाला वेक्टर होता है. एक फ़ंक्शन की मदद से, इसके आस-पास के शब्दों
की जानकारी को इसमें जोड़ दिया जाता है. इससे संदर्भ के हिसाब से किया जा रहा एंबेड तैयार होता है.
संदर्भ के हिसाब से बनाए जा रहे एंबेड के बारे में जानने के लिए यहां क्लिक करें
- खास तौर पर, ELMo मॉडल में, स्टैटिक तरीके से एंबेड करने की प्रोसेस को एंबेड करने की अन्य लेयर के साथ जोड़ा जाता है. एंबेड करने की इन प्रोसेस में, वाक्य को आगे से पीछे और पीछे से आगे पढ़ने से जुड़ी जानकारी, कोड के रूप में मौजूद होती है.
- बीईआरटी मॉडल, इनपुट के तौर पर दिए गए वाक्य के कुछ हिस्से को मास्क कर देता है.
- ट्रांसफ़ॉर्मर मॉडल एक सेल्फ़-अटेंशन लेयर का इस्तेमाल करता है. इससे उसे यह समझने में मदद मिलती है कि किसी सीक्वेंस के एक शब्द के लिए, बाकी शब्द कितने ज़रूरी हैं. साथ ही, यह ट्रेनिंग में अब तक सीखी गई हर टोकन एंबेडिंग के हर एलिमेंट के लिए, पोज़िशनल एंबेडिंग मैट्रिक्स ( पोज़िशनल एन्कोडिंग के बारे में जानें) में काम का कॉलम भी जोड़ता है. इससे इनपुट के तौर पर वह एंबेड तैयार होता है जिस पर मॉडल को सही अनुमान लगाने के लिए ट्रेन किया जाता है. शब्दों के हर अलग सीक्वेंस के लिए बनी यूनीक इनपुट के तौर पर किया जा रहा एंबेड, संदर्भ के हिसाब से बना एंबेड होता है.
ऊपर बताए गए मॉडल लैंग्वेज मॉडल हैं. हालांकि, संदर्भ के हिसाब से बनी एंबेड करने की प्रोसेस, जनरेट करने से जुड़े दूसरे कामों के लिए बहुत मददगार होती हैं. जैसे, इमेज जनरेट करने के लिए. किसी घोड़े की फ़ोटो के पिक्सल की आरजीबी वैल्यू की एंबेडिंग को, अगर हर पिक्सल की पोज़िशनल मैट्रिक्स और इसके आस-पास के पिक्सल के कोड के रूप में मौजूद जानकारी के साथ मिलाया जाए, तो इससे मॉडल को काफ़ी जानकारी मिलती है. संदर्भ के हिसाब से एंबेड करने की यह प्रोसेस, सिर्फ़ इन आरजीबी वैल्यू के लिए बने स्टैटिक एंबेडिंग से ज़्यादा कारगर होती हैं.