একটি এম্বেডিং একটি অপেক্ষাকৃত নিম্ন-মাত্রিক স্থান যেখানে আপনি উচ্চ-মাত্রিক ভেক্টর অনুবাদ করতে পারেন। উচ্চ-মাত্রিক বনাম নিম্ন-মাত্রিক ডেটার আলোচনার জন্য, ক্যাটেগরিক্যাল ডেটা মডিউলটি দেখুন।
এমবেডিংগুলি বৃহৎ বৈশিষ্ট্য ভেক্টরগুলিতে মেশিন লার্নিং করা সহজ করে তোলে, যেমন স্পার্স ভেক্টর পূর্ববর্তী বিভাগে আলোচনা করা খাবারের আইটেমগুলিকে উপস্থাপন করে৷ আদর্শভাবে, একটি এমবেডিং ইনপুটগুলির কিছু শব্দার্থকে ক্যাপচার করে যেগুলি এমবেডিং স্পেসে একত্রে কাছাকাছি থাকা অর্থে একই রকম। উদাহরণস্বরূপ, একটি ভাল এম্বেডিং "কার" শব্দটিকে "হাতি" এর চেয়ে "গ্যারেজ" এর কাছাকাছি রাখবে। একটি এমবেডিং প্রশিক্ষিত এবং মডেল জুড়ে পুনরায় ব্যবহার করা যেতে পারে।
এম্বেডিং ভেক্টরগুলি কীভাবে তথ্য উপস্থাপন করে তার একটি ধারণা দিতে, "অন্তত স্যান্ডউইচের মতো" থেকে "অধিকাংশ স্যান্ডউইচের মতো" স্কেলে হট ডগ , পিৎজা , সালাদ , শাওয়ার্মা এবং বোর্শট খাবারের একটি মাত্রিক উপস্থাপনা বিবেচনা করুন। " "স্যান্ডউইচনেস" হল একক মাত্রা।
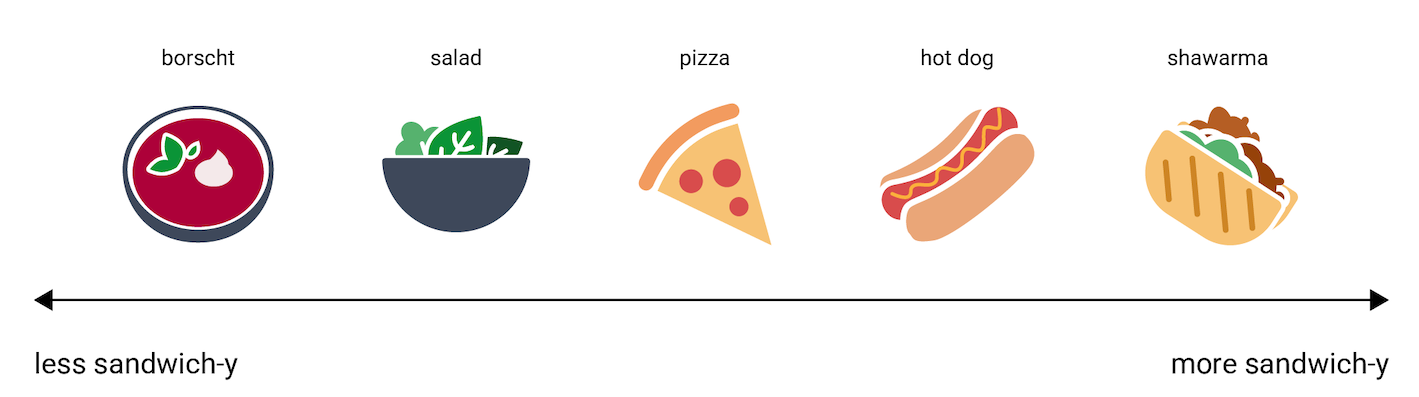
এই লাইনে একটি আপেল স্ট্রডেল কোথায় পড়বে? তর্কাতীতভাবে, এটি hot dog এবং shawarma মধ্যে স্থাপন করা যেতে পারে। কিন্তু আপেল স্ট্রুডেলও মিষ্টির একটি অতিরিক্ত মাত্রা (খাবার কতটা মিষ্টি) বা ডেজার্টনেস (খাবার কতটা ডেজার্টের মতো) আছে বলে মনে হয় যা এটিকে অন্যান্য বিকল্প থেকে খুব আলাদা করে তোলে। নিম্নলিখিত চিত্রটি একটি "ডেজার্টনেস" মাত্রা যোগ করে এটিকে কল্পনা করে:
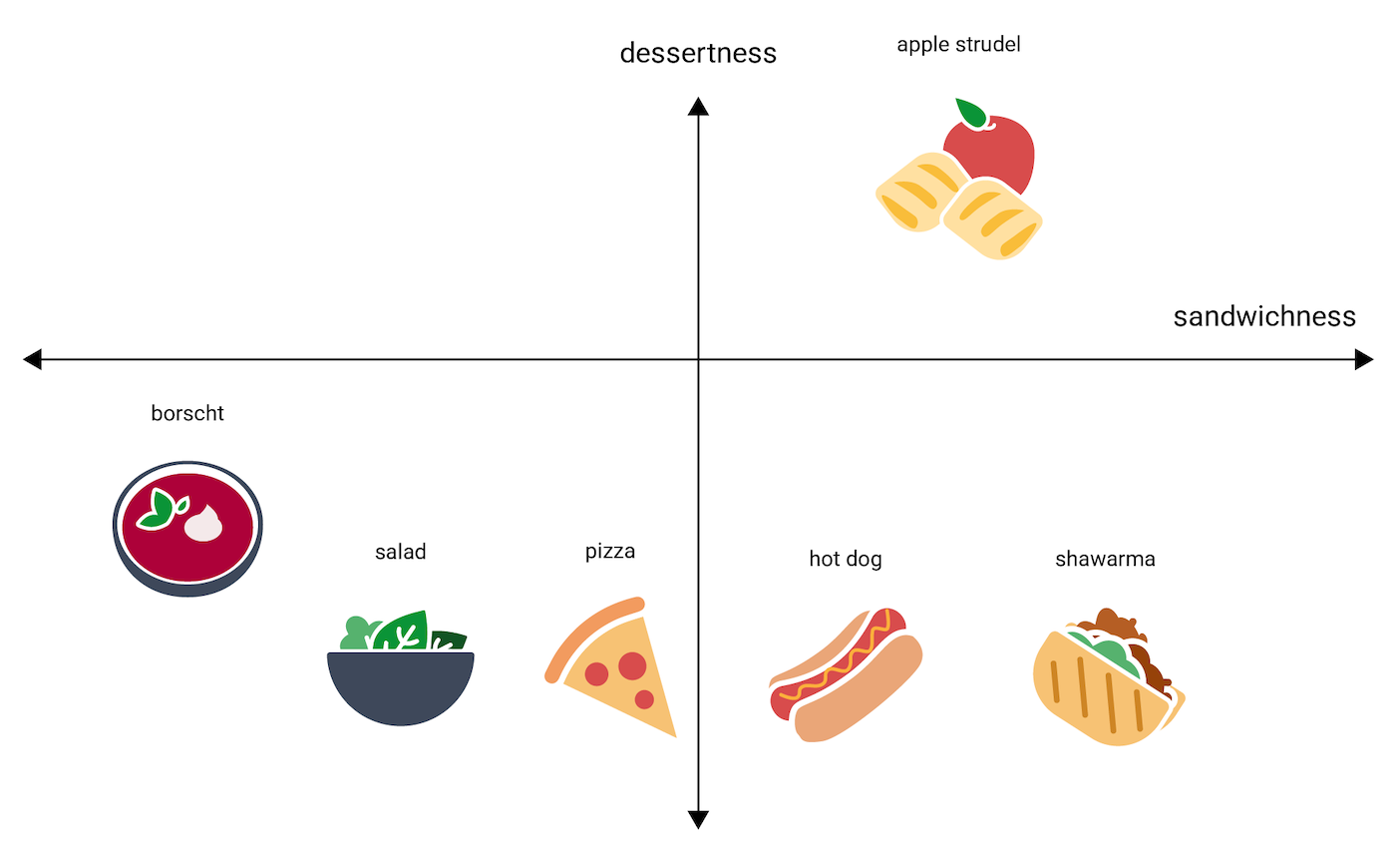
একটি এমবেডিং প্রতিটি আইটেমকে n- মাত্রিক স্থানের মধ্যে n ফ্লোটিং-পয়েন্ট সংখ্যার সাথে প্রতিনিধিত্ব করে (সাধারণত -1 থেকে 1 বা 0 থেকে 1 পর্যন্ত পরিসরে)। উদাহরণস্বরূপ, চিত্র 4 এ এমবেডিং দুটি স্থানাঙ্ক সহ দ্বি-মাত্রিক স্থানে প্রতিটি খাবারের আইটেমকে উপস্থাপন করে। আইটেম "আপেল স্ট্রুডেল" গ্রাফের উপরের-ডান চতুর্ভুজটিতে রয়েছে এবং বিন্দু বরাদ্দ করা যেতে পারে (0.5, 0.3), যেখানে "হট ডগ" গ্রাফের নীচে-ডান চতুর্ভুজটিতে রয়েছে এবং বিন্দু বরাদ্দ করা যেতে পারে ( 0.2, –0.5)।
একটি এমবেডিং-এ, যেকোনো দুটি আইটেমের মধ্যে দূরত্ব গাণিতিকভাবে গণনা করা যেতে পারে, এবং সেই দুটি আইটেমের আপেক্ষিক মিল হিসাবে ব্যাখ্যা করা যেতে পারে। দুটি জিনিস যা একে অপরের কাছাকাছি, যেমন চিত্র 4-এ shawarma এবং hot dog , দুটি জিনিস একে অপরের থেকে অনেক বেশি দূরের, যেমন apple strudel এবং borscht চেয়ে বেশি ঘনিষ্ঠভাবে সম্পর্কিত।
আরও লক্ষ্য করুন যে চিত্র 4-এর 2D স্পেসে, apple strudel shawarma এবং hot dog থেকে 1D স্পেসের চেয়ে অনেক বেশি দূরে, যা অন্তর্দৃষ্টির সাথে মেলে: apple strudel হট ডগ বা শাওয়ারমা হট ডগের মতো নয়। এবং shawarmas একে অপরের হয়.
এখন বোর্শট বিবেচনা করুন, যা অন্যান্য আইটেমগুলির তুলনায় অনেক বেশি তরল। এটি একটি তৃতীয় মাত্রার পরামর্শ দেয়, তরলতা (খাবার কতটা তরল)। সেই মাত্রা যোগ করে, আইটেমগুলিকে এইভাবে 3D তে ভিজ্যুয়ালাইজ করা যেতে পারে:
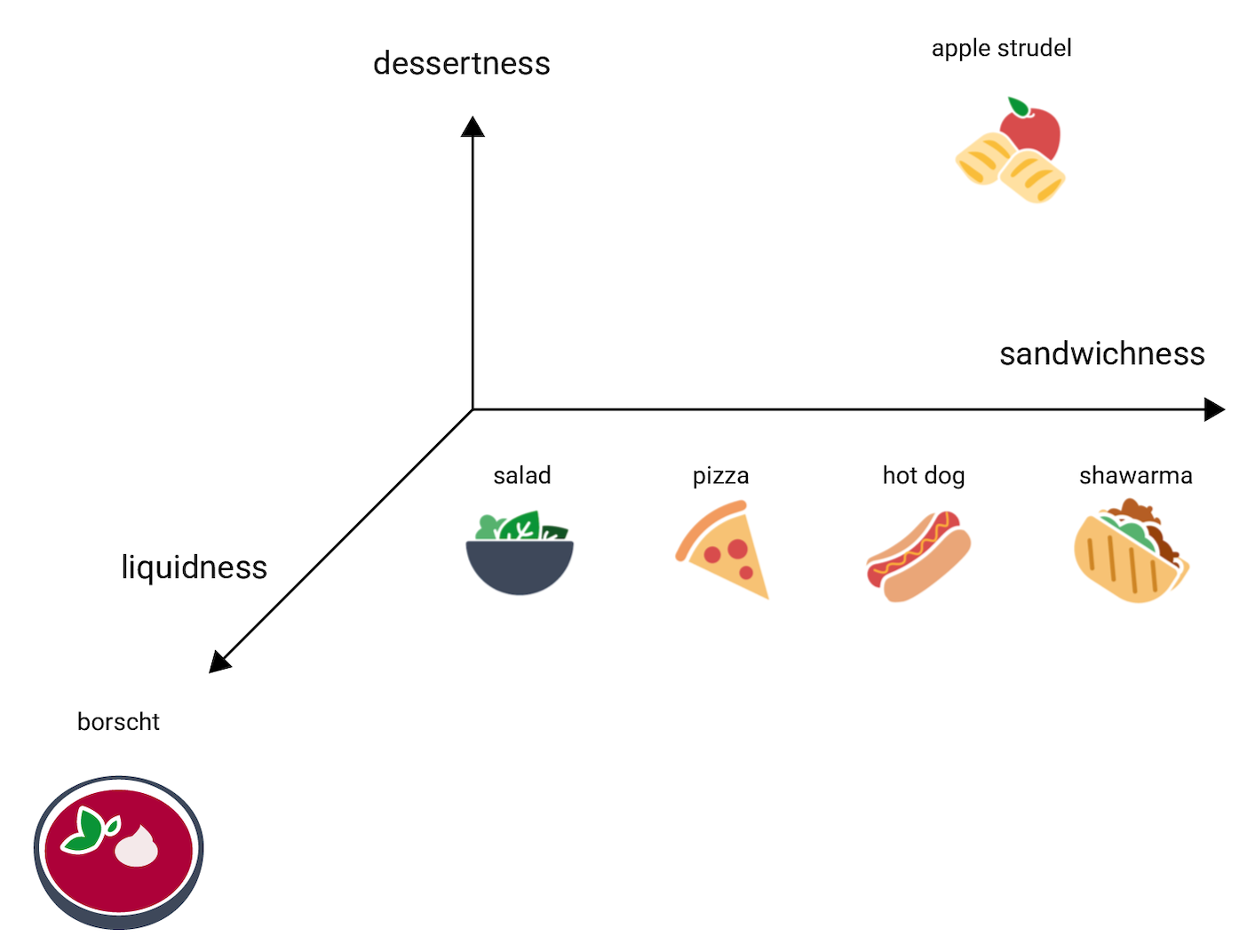
এই 3D স্পেসে ট্যাংইয়ুয়ান কোথায় যাবে? এটি স্যুপি, বোর্শটের মতো, এবং একটি মিষ্টি ডেজার্ট, আপেল স্ট্রডেলের মতো, এবং অবশ্যই একটি স্যান্ডউইচ নয়। এখানে একটি সম্ভাব্য স্থান নির্ধারণ করা হয়েছে:
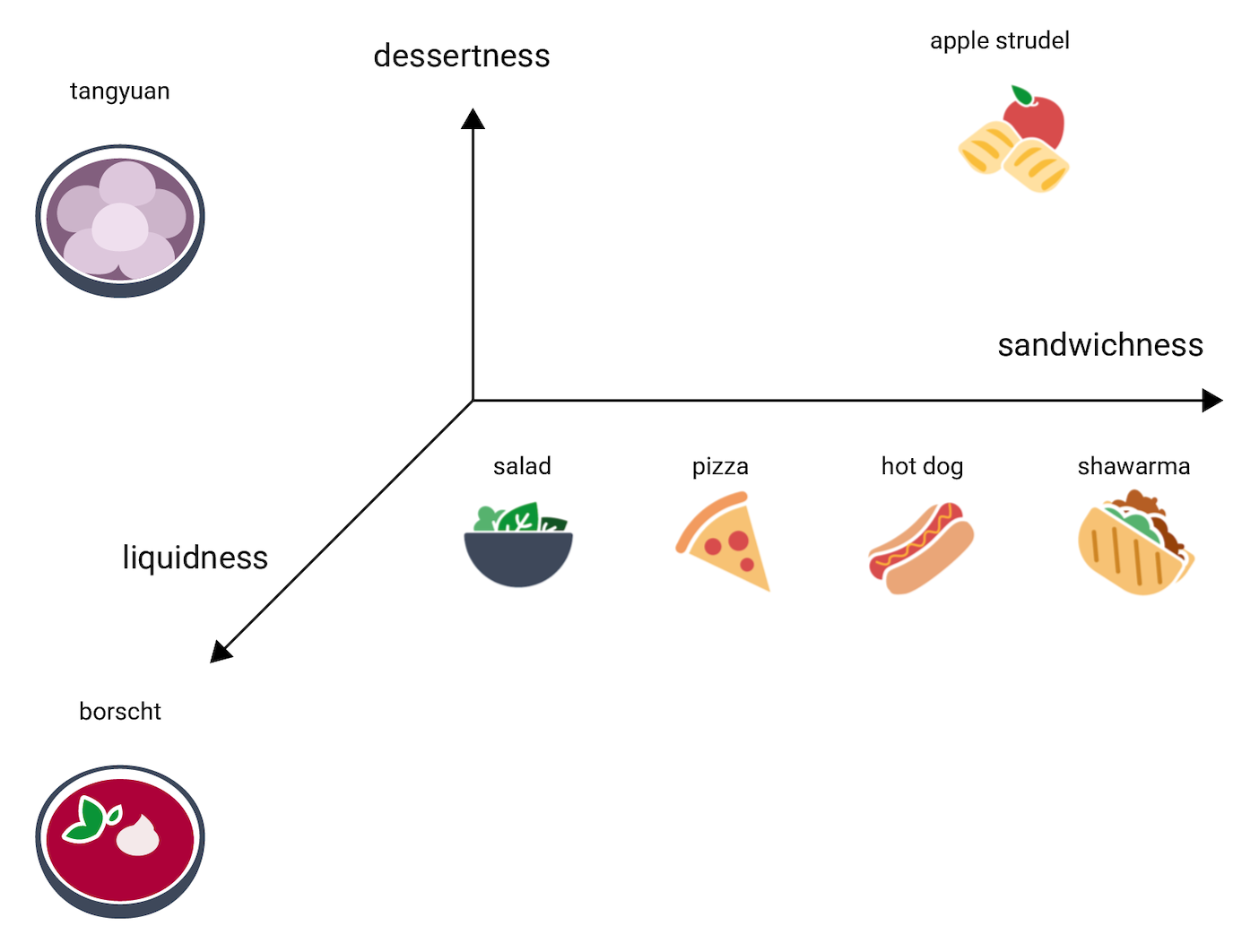
এই তিনটি মাত্রায় কত তথ্য প্রকাশ করা হয়েছে লক্ষ্য করুন। আপনি অতিরিক্ত মাত্রা কল্পনা করতে পারেন, যেমন মাংসলতা বা বেকডনেস ।
বাস্তব-বিশ্ব এম্বেডিং স্পেস
আপনি উপরের খাবারের উদাহরণগুলিতে যেমন দেখেছেন, এমনকি একটি ছোট বহুমাত্রিক স্থান শব্দার্থগতভাবে অনুরূপ আইটেমগুলিকে একত্রে গোষ্ঠীবদ্ধ করার এবং ভিন্ন ভিন্ন আইটেমগুলিকে দূরে রাখার স্বাধীনতা প্রদান করে। ভেক্টর স্পেসে অবস্থান (দূরত্ব এবং দিক) একটি ভাল এমবেডিংয়ে শব্দার্থবিদ্যা এনকোড করতে পারে। উদাহরণ স্বরূপ, বাস্তব এম্বেডিংয়ের নিম্নলিখিত ভিজ্যুয়ালাইজেশনগুলি একটি দেশ এবং এর রাজধানী শব্দগুলির মধ্যে জ্যামিতিক সম্পর্ককে চিত্রিত করে৷ আপনি দেখতে পাচ্ছেন যে "কানাডা" থেকে "অটোয়া" এর দূরত্ব "তুরস্ক" থেকে "আঙ্কারা" এর দূরত্বের সমান।

একটি অর্থপূর্ণ এমবেডিং স্পেস একটি মেশিন লার্নিং মডেলকে প্রশিক্ষণের সময় প্যাটার্ন সনাক্ত করতে সহায়তা করে।
ব্যায়াম
এই অনুশীলনে, আপনি এম্বেডিং প্রজেক্টর টুল ব্যবহার করবেন word2vec নামক একটি শব্দ এমবেডিং কল্পনা করতে যা ভেক্টর স্পেসে সংখ্যাগতভাবে 70,000 টিরও বেশি ইংরেজি শব্দ উপস্থাপন করে।
টাস্ক 1
নিম্নলিখিত কাজগুলি সম্পাদন করুন, এবং তারপর নীচের প্রশ্নের উত্তর দিন।
এমবেডিং প্রজেক্টর টুল খুলুন।
ডান প্যানেলে, অনুসন্ধান ক্ষেত্রে শব্দ পরমাণু লিখুন। তারপর নিচের ফলাফল থেকে শব্দ পরমাণু ক্লিক করুন ( 4 ম্যাচের নিচে)। আপনার পর্দা চিত্র 8 এর মত হওয়া উচিত।

চিত্র 8 । এম্বেডিং প্রজেক্টর টুল, সার্চ ফিল্ডে "এটম" শব্দ যোগ করা হয়েছে (লাল বৃত্তাকারে)। আবার, ডান প্যানেলে, পরমাণুর নিকটতম 100 শব্দ দেখাতে আইসোলেট 101 পয়েন্ট বোতামে ক্লিক করুন ( অনুসন্ধান ক্ষেত্রের উপরে)। আপনার পর্দা চিত্র 9 এর মত হওয়া উচিত।

চিত্র 9 । এম্বেডিং প্রজেক্টর টুল, এখন "আইসোলেট 101 পয়েন্ট" ক্লিক করা হয়েছে (লাল বৃত্তাকারে)।
এখন, মূল স্থানের নিকটবর্তী পয়েন্টের অধীনে তালিকাভুক্ত শব্দগুলি পর্যালোচনা করুন। আপনি এই শব্দগুলি কিভাবে বর্ণনা করবেন?
আমাদের উত্তরের জন্য এখানে ক্লিক করুন
বেশিরভাগ নিকটতম শব্দগুলি হল শব্দ যা সাধারণত পরমাণু শব্দের সাথে যুক্ত থাকে, যেমন বহুবচন রূপ "পরমাণু," এবং শব্দগুলি "ইলেক্ট্রন," "অণু," এবং "নিউক্লিয়াস"।
টাস্ক 2
নিম্নলিখিত কাজগুলি সম্পাদন করুন এবং তারপরে নীচের প্রশ্নের উত্তর দিন:
টাস্ক 1 থেকে ডেটা ভিজ্যুয়ালাইজেশন রিসেট করতে ডান প্যানেলে সমস্ত ডেটা দেখান বোতামে ক্লিক করুন।
ডান প্যানেলে, অনুসন্ধান ক্ষেত্রে ইউরেনিয়াম শব্দটি লিখুন। আপনার পর্দা চিত্র 10 এর মত হওয়া উচিত।

চিত্র 10 । এম্বেডিং প্রজেক্টর টুল, সার্চ ফিল্ডে "ইউরেনিয়াম" শব্দ যোগ করা হয়েছে।
মূল স্থানের নিকটবর্তী পয়েন্টের অধীনে তালিকাভুক্ত শব্দগুলি পর্যালোচনা করুন। কিভাবে এই শব্দগুলি পরমাণুর নিকটতম শব্দের চেয়ে আলাদা?
আমাদের উত্তরের জন্য এখানে ক্লিক করুন
ইউরেনিয়াম একটি নির্দিষ্ট তেজস্ক্রিয় রাসায়নিক উপাদানকে বোঝায় এবং নিকটতম শব্দগুলির মধ্যে অনেকগুলি অন্যান্য উপাদান, যেমন জিঙ্ক, ম্যাঙ্গানিজ, তামা এবং অ্যালুমিনিয়াম।
টাস্ক 3
নিম্নলিখিত কাজগুলি সম্পাদন করুন এবং তারপরে নীচের প্রশ্নের উত্তর দিন:
টাস্ক 2 থেকে ডেটা ভিজ্যুয়ালাইজেশন রিসেট করতে ডান প্যানেলে সমস্ত ডেটা দেখান বোতামে ক্লিক করুন।
ডান প্যানেলে, অনুসন্ধান ক্ষেত্রে কমলা শব্দটি লিখুন। আপনার পর্দা চিত্র 11 এর মত হওয়া উচিত।

চিত্র 11 । প্রজেক্টর টুল এম্বেড করা, অনুসন্ধান ক্ষেত্রে "কমলা" শব্দটি যোগ করা হয়েছে।
মূল স্থানের নিকটবর্তী পয়েন্টের অধীনে তালিকাভুক্ত শব্দগুলি পর্যালোচনা করুন। এখানে দেখানো শব্দের ধরন সম্পর্কে আপনি কী লক্ষ্য করেন এবং এখানে দেখানো হয়নি
আমাদের উত্তরের জন্য এখানে ক্লিক করুন
প্রায় সব নিকটতম শব্দ অন্যান্য রং, যেমন "হলুদ," "সবুজ," "নীল," "বেগুনি," এবং "লাল।" নিকটতম শব্দগুলির মধ্যে শুধুমাত্র একটি ("রস") শব্দের অন্য অর্থ (একটি সাইট্রাস ফল) বোঝায়। অন্যান্য ফল যা আপনি দেখতে আশা করতে পারেন, যেমন "আপেল" এবং "কলা," নিকটতম পদের তালিকা তৈরি করেনি।
এই উদাহরণটি word2vec-এর মতো স্ট্যাটিক এম্বেডিংয়ের মূল ত্রুটিগুলির একটিকে চিত্রিত করে। একটি শব্দের সমস্ত সম্ভাব্য অর্থ ভেক্টর স্থানের একটি একক বিন্দু দ্বারা উপস্থাপিত হয়, তাই আপনি যখন "কমলা" এর জন্য একটি সাদৃশ্য বিশ্লেষণ করেন, তখন শব্দের একটি নির্দিষ্ট বর্ণনার জন্য নিকটতম বিন্দুগুলিকে আলাদা করা সম্ভব নয়, যেমন "কমলা" (ফল) কিন্তু "কমলা" (রঙ) নয়।