embedding adalah ruang dimensi yang relatif rendah yang dapat Anda terjemahkan vektor berdimensi tinggi. Untuk diskusi tentang dimensi vs. data dimensi rendah, lihat Kategori Data ruang lingkup modul ini.
Embeddings memudahkan untuk melakukan machine learning pada jaringan vektor fitur, seperti sebagai vektor renggang yang merepresentasikan item makanan yang telah dibahas dalam bagian sebelumnya. Idealnya, embedding menangkap beberapa semantik input dengan menempatkan input yang lebih mirip artinya lebih dekat bersama-sama di ruang embedding. Misalnya, embedding yang baik akan menempatkan kata "mobil" lebih dekat ke "{i>garage<i}" dan "gagal". Embedding dapat dilatih dan digunakan kembali di berbagai model.
Untuk memberikan gambaran tentang bagaimana vektor embedding merepresentasikan informasi, pertimbangkan menampilkan hidangan satu dimensi hot dog, pizza, salad, shawarma, dan borscht, pada skala "paling tidak seperti sandwich" ke "paling seperti roti lapis". "Sandwichness" (Sandwichness) adalah dimensi tunggal.

Di mana pada jalur ini
strudel apel
jatuh? Bisa jadi, elemen ini dapat ditempatkan antara hot dog dan shawarma. Tapi apel
strudel juga tampaknya memiliki dimensi tambahan rasa manis
makanannya) atau makanan penutup (seberapa seperti makanan penutup) yang membuat
itu sangat berbeda
dari opsi lainnya. Gambar berikut memvisualisasikan
dengan menambahkan "hidangan penutup" dimensi:
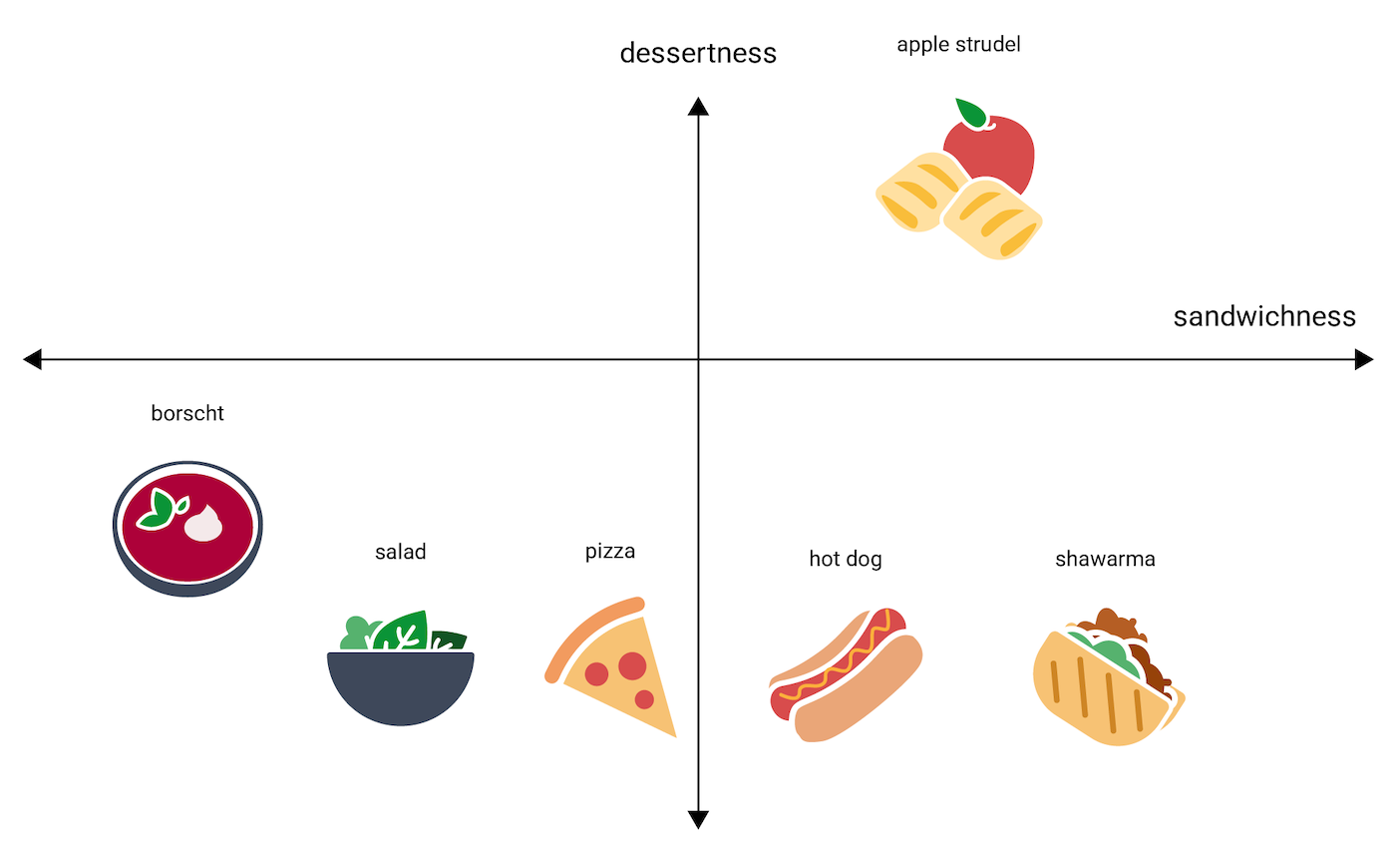
Embedding mewakili setiap item dalam ruang n dimensi dengan n bilangan floating point (biasanya dalam kisaran -1 hingga 1 atau 0 hingga 1). Misalnya, embedding di Gambar 4 merepresentasikan setiap item makanan ruang dua dimensi dengan dua koordinat. Item "apple strudel" berada di di kuadran kanan atas grafik tersebut dan dapat diberi poin (0,5, 0,3), sedangkan "hot dog" ada di kuadran kanan bawah grafik dan diberi poin (0,2, -0,5).
Dalam embedding, jarak antara dua item dapat dihitung
secara matematis,
dan dapat ditafsirkan sebagai kesamaan relatif dari keduanya
item. Dua hal yang berdekatan, seperti shawarma dan hot dog
pada Gambar 4, terkait lebih erat daripada dua hal yang saling berjauhan
lainnya, seperti apple strudel dan borscht.
Perhatikan juga bahwa dalam ruang 2D pada Gambar 4, apple strudel jauh lebih jauh
dari shawarma dan hot dog dibandingkan dengan yang ada di ruang 1D, yang cocok
intuisi: apple strudel tidak semirip hot dog atau shawarma dengan panas
dan shawarma saling berdekatan.
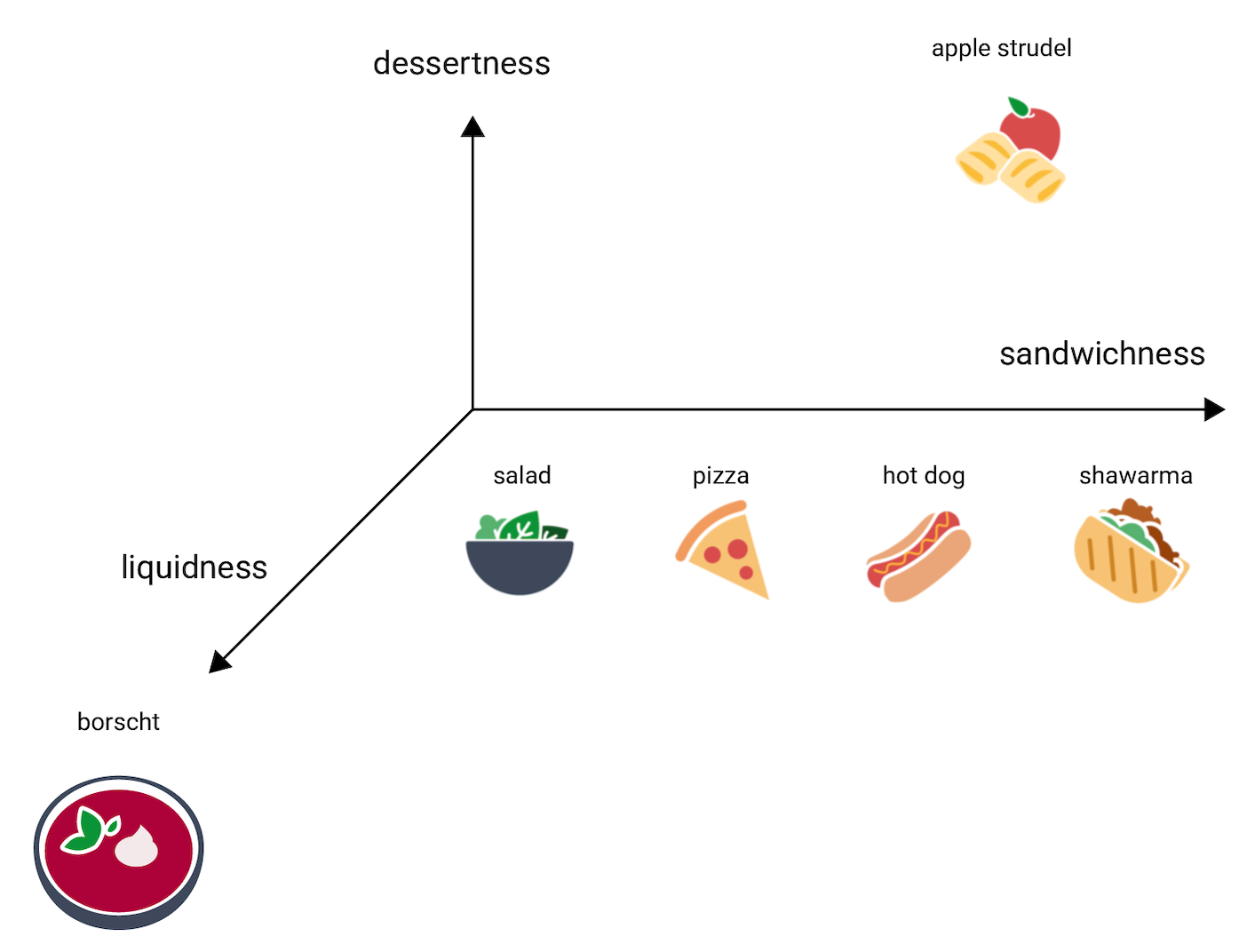
Sekarang pertimbangkan borscht, yang jauh lebih cair daripada barang lainnya. Ini menyarankan dimensi ketiga, likuiditas (seberapa cair makanan). Dengan menambahkan dimensi tersebut, item dapat divisualisasikan dalam 3D dengan cara ini:
Di mana dalam ruang 3D ini akan tangyuan pergi? Penting sup, seperti borscht, dan makanan penutup manis, seperti apel strudel, dan yang pasti bukan sandwich. Berikut adalah satu kemungkinan penempatan:
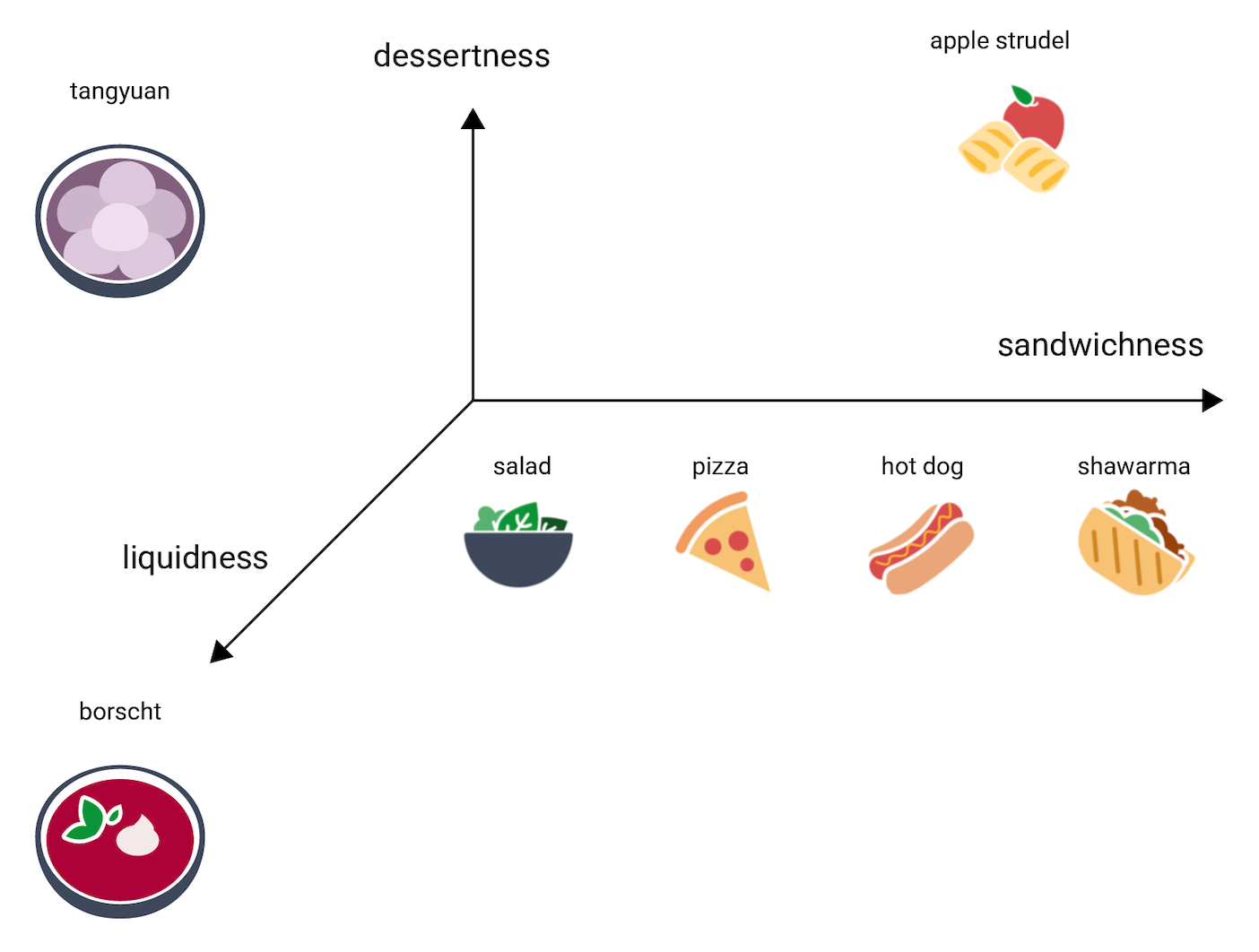
Perhatikan berapa banyak informasi yang dinyatakan dalam ketiga dimensi ini. Anda dapat membayangkan dimensi tambahan, seperti daging atau kematangan.
Ruang embedding di dunia nyata
Seperti yang Anda lihat pada contoh makanan di atas, bahkan ruang multi-dimensi yang kecil memberikan kebebasan untuk mengelompokkan item yang mirip secara semantik item yang berbeda berjauhan. Posisi (jarak dan arah) dalam vektor tertentu dapat mengenkode semantik dalam embedding yang baik. Misalnya, visualisasi embeddings nyata menggambarkan hubungan geometris di antara kata-kata untuk suatu negara dan ibu kotanya. Terlihat bahwa jarak dari "Kanada" ke "Ottawa" hampir sama dengan jarak dari "Turki" dapat "Ankara".

Ruang embedding yang bermakna membantu model machine learning mendeteksi pola selama pelatihan.
Latihan
Dalam latihan ini, Anda akan menggunakan fungsi Penyematan Alat proyektor untuk memvisualisasikan kata penyematan yang disebut word2vec, mewakili lebih dari 70.000 kata bahasa Inggris secara numerik di ruang vektor.
Tugas 1
Lakukan tugas berikut, lalu jawab pertanyaan di bawah ini.
Buka alat Penyematan Proyektor.
Di panel kanan, masukkan kata atom di kolom Telusuri. Selanjutnya klik kata atom dari hasil di bawah (di bawah 4 kecocokan). Nama layar akan terlihat seperti Gambar 8.
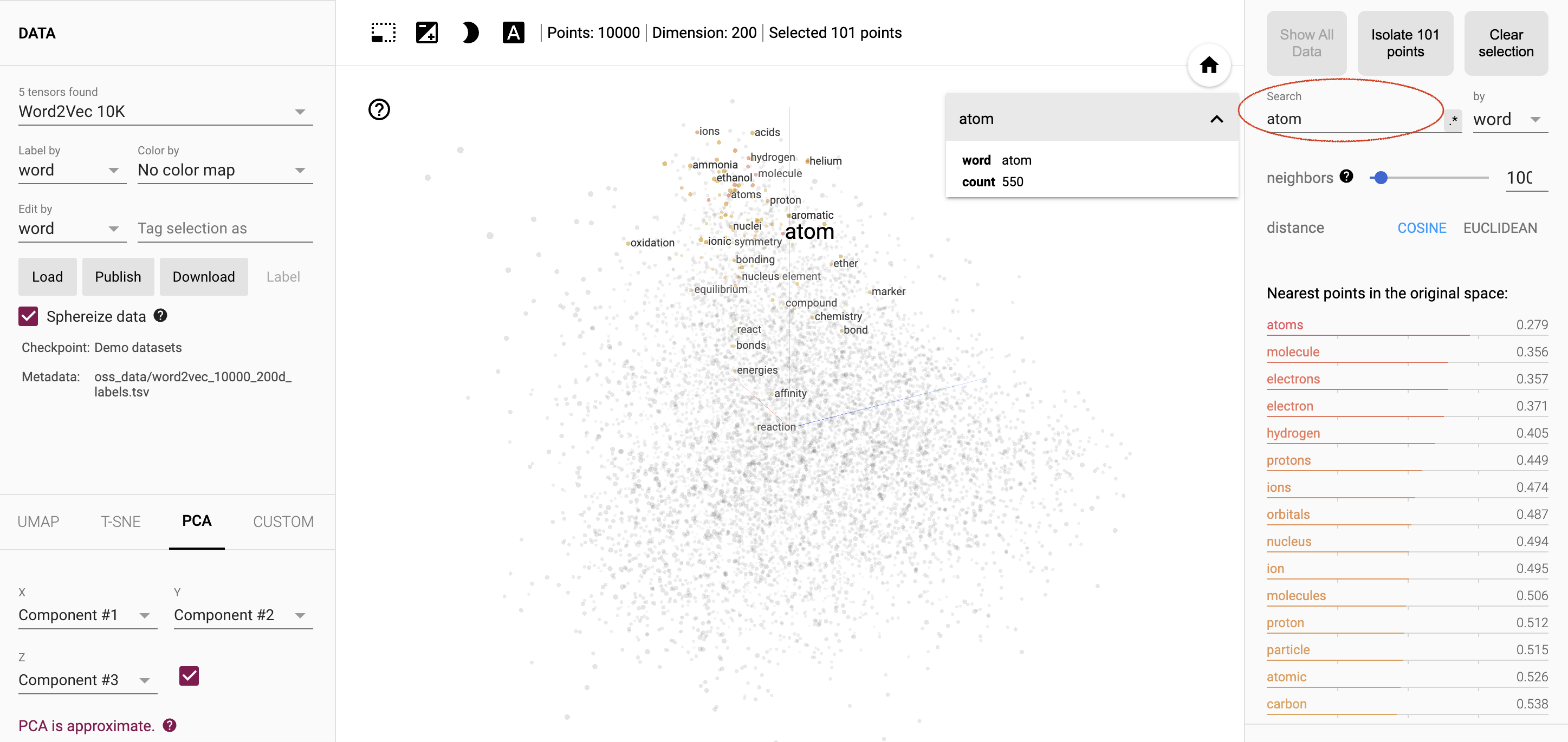
Gambar 8. Menyematkan alat proyektor, dengan kata "atom" ditambahkan di bidang Penelusuran (dilingkari dengan warna merah). Sekali lagi, di panel kanan, klik tombol Isolate 101 points (di atas kolom Telusuri) untuk menampilkan 100 kata terdekat ke atom. Layar Anda akan terlihat seperti Gambar 9.
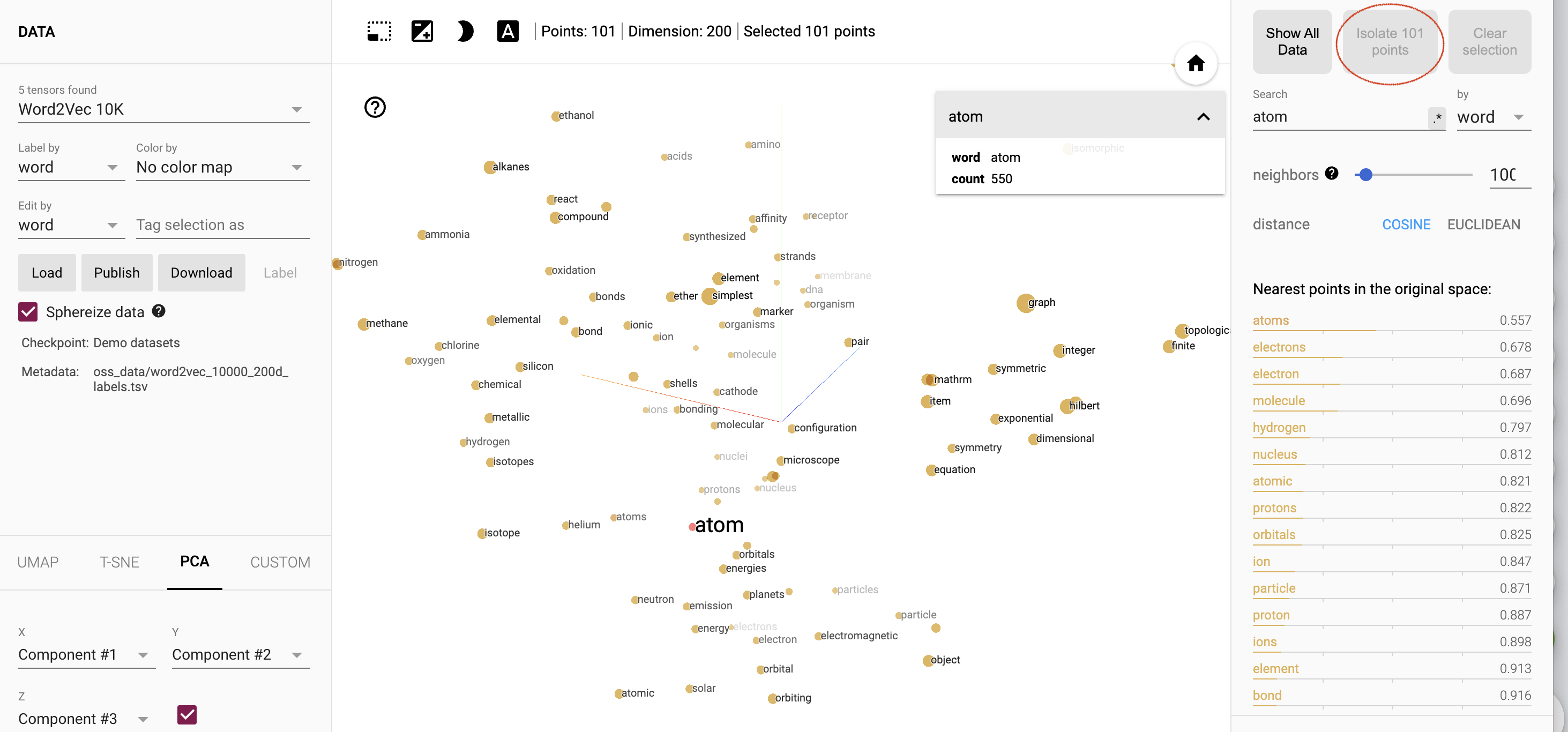
Gambar 9. Menyematkan alat proyektor, kini dengan "Isolasi 101 titik" diklik (dilingkari dengan warna merah).
Sekarang, tinjau kata-kata yang tercantum di bagian Titik terdekat dalam ruang asli. Bagaimana Anda mendeskripsikan kata-kata ini?
Klik di sini untuk melihat jawaban kami
Mayoritas kata terdekat adalah kata-kata yang umumnya terkait dengan kata atom, contohnya bentuk jamak yaitu "atoms," dan kata-kata "elektron", "molekul," dan "inti".
Tugas 2
Lakukan tugas berikut, lalu jawab pertanyaan di bawah ini:
Klik tombol Tampilkan Semua Data di panel kanan untuk mereset data visualisasi dari Tugas 1.
Di panel kanan, masukkan kata uranium di kolom Telusuri. Layar Anda akan terlihat seperti Gambar 10.
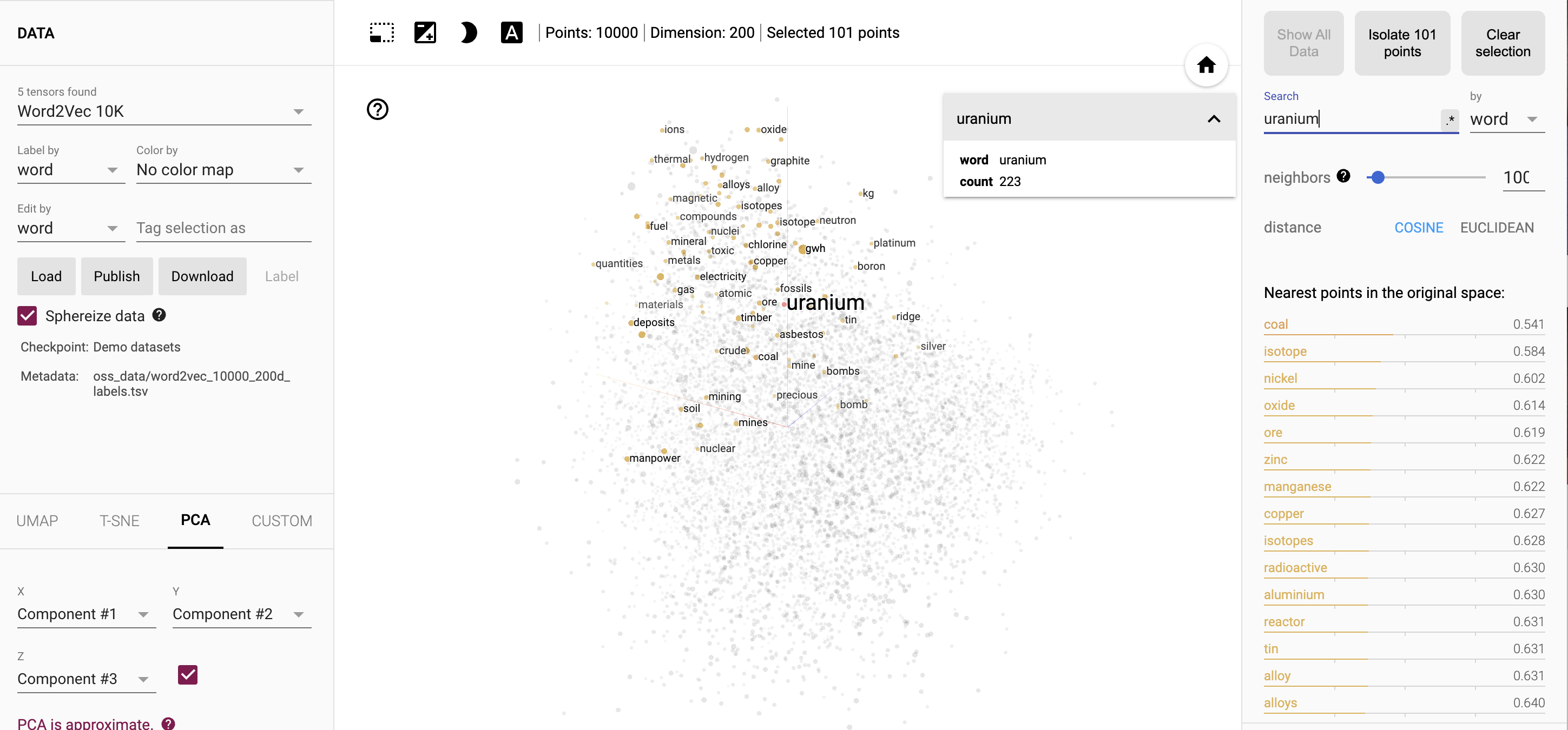
Gambar 10. Menyematkan alat proyektor, dengan kata "uranium" yang ditambahkan di kolom Penelusuran.
Tinjau kata yang tercantum di bagian Titik terdekat dalam ruang asli. Cara apakah kata-kata tersebut berbeda dengan kata terdekat untuk atom?
Klik di sini untuk melihat jawaban kami
Uranium mengacu pada zat radioaktif tertentu elemen kimia, dan banyak kata terdekat adalah unsur-unsur lain, seperti seng, mangan, tembaga, dan aluminium.
Tugas 3
Lakukan tugas berikut, lalu jawab pertanyaan di bawah ini:
Klik tombol Tampilkan Semua Data di panel kanan untuk mereset data visualisasi dari Tugas 2.
Di panel kanan, masukkan kata oranye di kolom Penelusuran. Nama layar akan terlihat seperti Gambar 11.
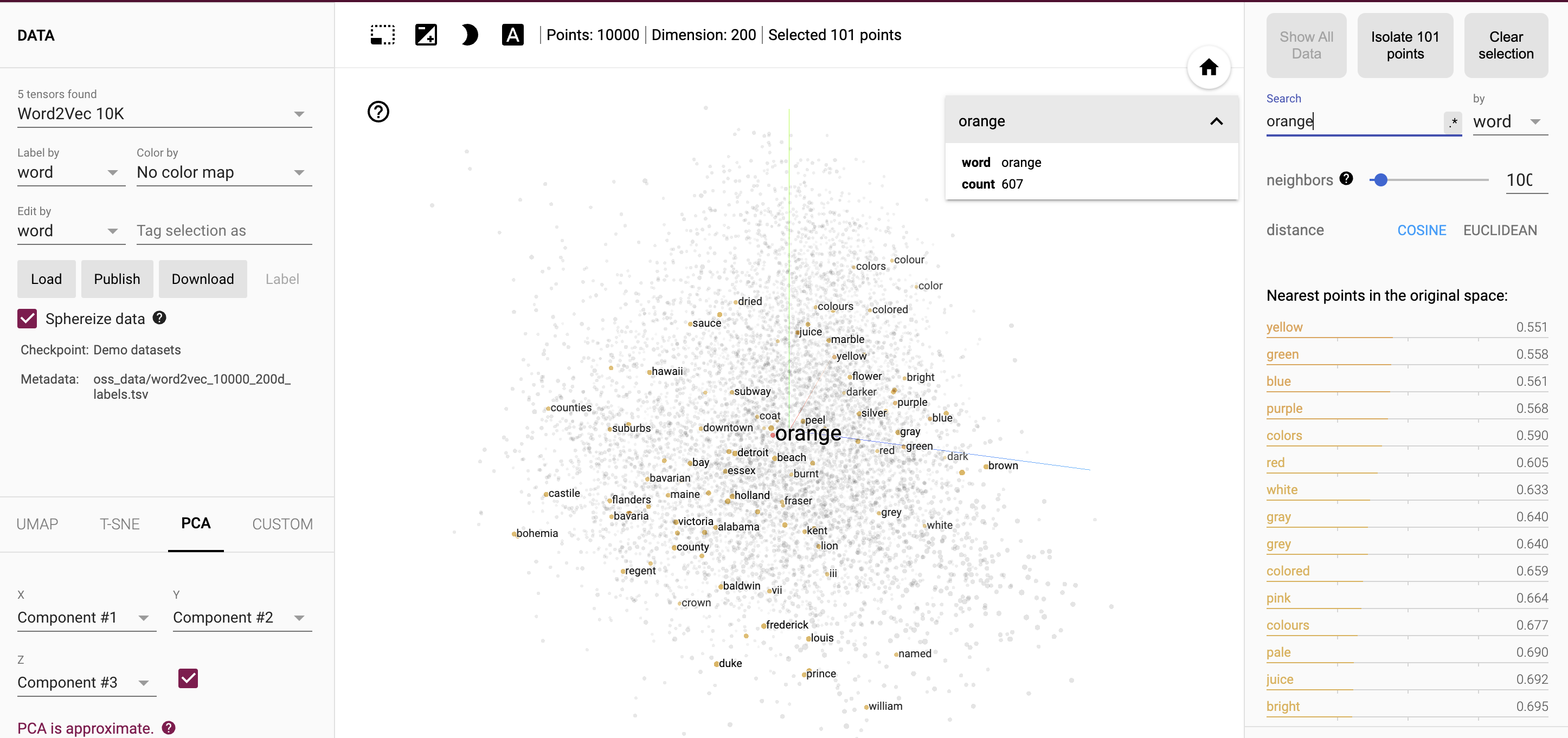
Gambar 11. Menyematkan alat proyektor, dengan kata "oranye" yang ditambahkan di kolom Penelusuran.
Tinjau kata yang tercantum di bagian Titik terdekat dalam ruang asli. Apa yang Anda perhatikan tentang jenis kata yang ditampilkan di sini, dan jenis kata tidak ditampilkan di sini?
Klik di sini untuk melihat jawaban kami
Hampir semua kata terdekat adalah warna lain, seperti "kuning", "hijau", "biru", "ungu," dan "merah". Hanya salah satu dari kata yang terdekat ("jus") merujuk pada arti lain kata tersebut (buah jeruk). Buah lainnya yang mungkin Anda harapkan untuk melihatnya, dan "pisang", tidak tercantum dalam daftar suku terdekat.
Contoh ini mengilustrasikan salah satu kekurangan utama dari embedding statis misalnya, kata 2vec. Semua kemungkinan arti sebuah kata diwakili oleh satu titik di ruang vektor, jadi ketika Anda melakukan analisis kesamaan untuk “oranye,” ini tidak mungkin mengisolasi titik terdekat untuk denotasi tertentu kata, seperti "oranye" (buah) tetapi bukan "oranye" (warna).