Sejauh ini, diskusi kita tentang metrik keadilan mengasumsikan bahwa pelatihan kami dan contoh pengujian berisi data demografis yang komprehensif untuk demografi, subkelompok yang dievaluasi. Namun, sering kali tidak demikian.
Misalkan set data penerimaan kita tidak berisi data demografi lengkap. Sebaliknya, keanggotaan grup demografis dicatat hanya untuk sebagian kecil contoh, seperti siswa yang memilih untuk mengidentifikasi diri mereka sendiri saya bergabung. Dalam hal ini, perincian kelompok kandidat menjadi pernyataan yang disetujui dan siswa yang ditolak kini akan terlihat seperti ini:
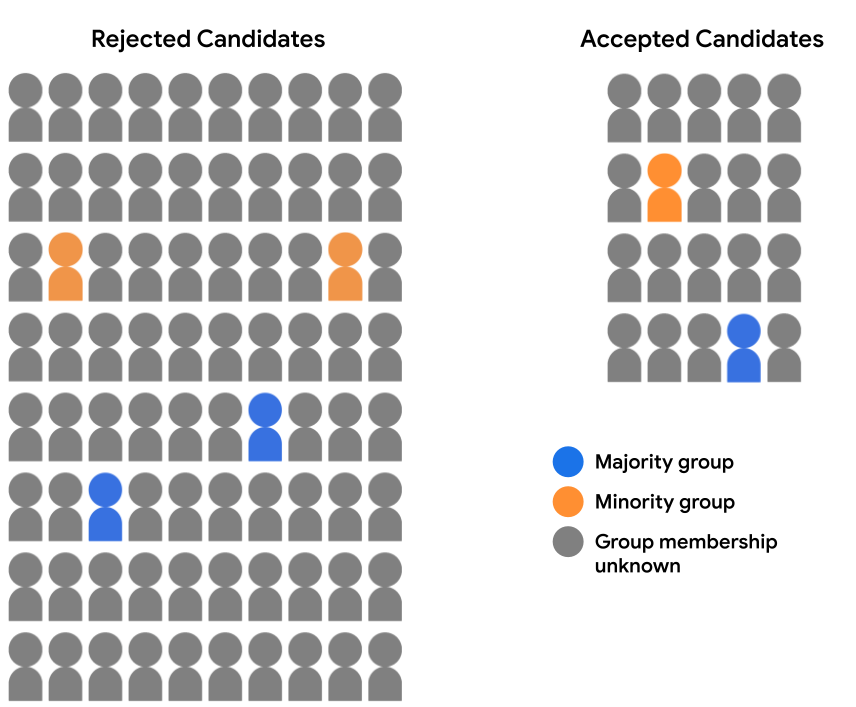
Di sini, kita tidak dapat mengevaluasi prediksi model untuk paritas atau kesetaraan peluang, karena kita tidak memiliki data demografis untuk 94% contoh. Namun, untuk 6% contoh yang berisi fitur demografis, kita masih dapat membandingkan pasangan prediksi (kandidat mayoritas vs. kandidat minoritas) dan lihat apakah mereka telah diperlakukan secara setara oleh model.
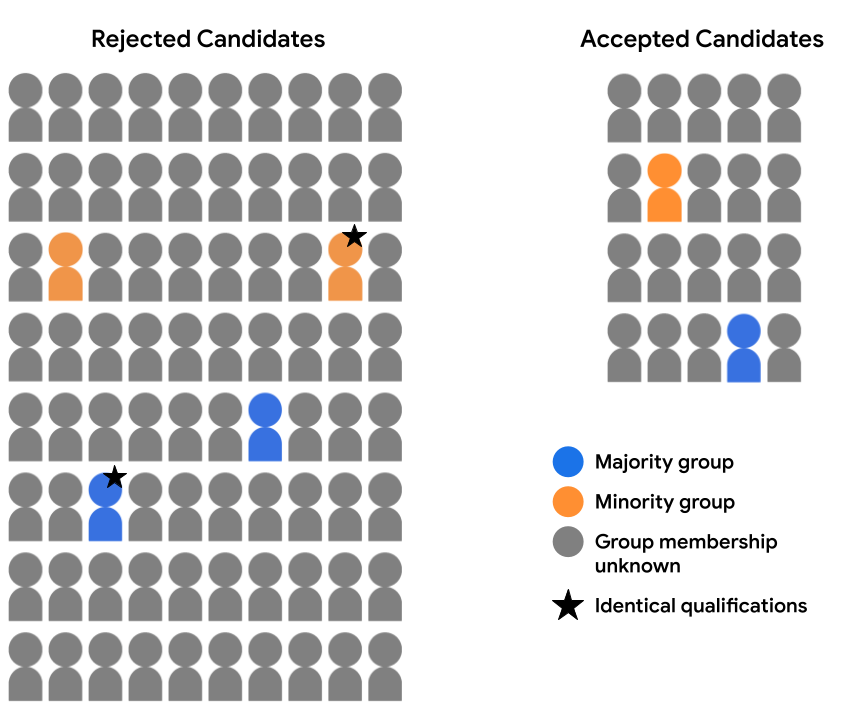
Misalnya, kita telah meninjau data fitur secara menyeluruh tersedia untuk dua kandidat (satu dalam kelompok mayoritas dan satu di kelompok minoritas kelompok, dengan keterangan bintang pada gambar di bawah), dan telah menetapkan bahwa mereka sama kualifikasinya untuk diterima dalam segala hal. Jika model membuat prediksi yang sama untuk kedua kandidat ini (yaitu, keduanya menolak kandidat atau menerima kedua kandidat), hal ini dikatakan memenuhi kontrafaktual perlakuan yang adil untuk contoh-contoh ini. Keadilan kontrafaktual menyatakan bahwa dua contoh yang identik dalam segala hal, kecuali atribut sensitif tertentu (di sini, keanggotaan grup demografis), seharusnya menghasilkan model yang sama prediksi.
Manfaat dan kekurangan
Seperti yang disebutkan sebelumnya, salah satu manfaat utama dari keadilan kontrafaktual adalah dapat digunakan untuk mengevaluasi prediksi keadilan dalam banyak kasus di mana metrik lain tidak memungkinkan. Jika {i>dataset<i} tidak berisi kumpulan informasi yang lengkap nilai fitur untuk atribut grup relevan yang dipertimbangkan, fitur ini tidak dapat mengevaluasi perlakuan yang adil menggunakan paritas demografis atau kesetaraan peluang. Namun, jika atribut grup ini tersedia untuk subkumpulan contoh, dan mengidentifikasi pasangan ekuivalen yang sebanding dalam berbagai kelompok, praktisi dapat menggunakan keadilan kontrafaktual sebagai metrik untuk memeriksa model potensi bias dalam prediksi.
Selain itu, karena metrik seperti paritas demografis dan kesetaraan menilai peluang secara agregat, mereka dapat menyamarkan masalah bias yang model pada level prediksi individu, yang dapat ditampilkan dengan evaluasi menggunakan keadilan kontrafaktual. Misalnya, anggaplah penerimaan kami menerima kandidat yang memenuhi syarat dari kelompok mayoritas dan minoritas kelompok dengan proporsi yang sama, tetapi kandidat minoritas yang paling memenuhi syarat adalah ditolak sedangkan kandidat mayoritas paling memenuhi syarat yang memiliki kesamaan kredensial diterima. Analisis keadilan kontrafaktual dapat membantu mengidentifikasi perbedaan semacam ini sehingga dapat ditangani.
Di sisi lain, kelemahan utama dari keadilan kontrafaktual adalah bahwa ia tidak memberikan pandangan bias secara holistik dalam prediksi model. Mengidentifikasi dan memperbaiki sejumlah ketidaksetaraan dalam beberapa contoh mungkin tidak cukup untuk mengatasi masalah bias sistemik yang mempengaruhi seluruh subkelompok contoh.
Jika memungkinkan, praktisi dapat mempertimbangkan untuk melakukan analisis keadilan (menggunakan metrik seperti paritas demografis atau kesetaraan serta analisis keadilan kontrafaktual untuk mendapatkan berbagai wawasan tentang potensi masalah bias yang perlu diperbaiki.
Latihan: Memeriksa pemahaman Anda
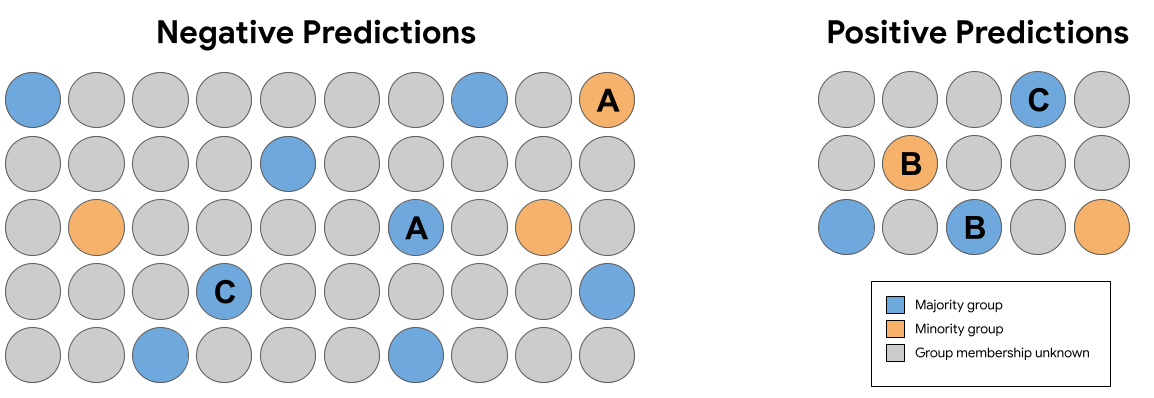
Dalam set prediksi pada Gambar 7 di atas, yang mana pasangan identik berikut (tidak termasuk keanggotaan grup) menerima prediksi yang melanggar keadilan kontrafaktual?
Ringkasan
Keseimbangan demografi, kesetaraan peluang, dan kontrafaktual, masing-masing memberikan definisi matematis yang berbeda keadilan untuk prediksi model. Dan itulah tiga kemungkinan cara mengukur keadilan. Beberapa definisi tentang keadilan bahkan saling mendukung tidak kompatibel, artinya tidak mungkin untuk memuaskan mereka secara bersamaan terhadap prediksi model yang diberikan.
Jadi, bagaimana cara memilih informasi yang "tepat" metrik keadilan untuk model Anda? Anda harus mempertimbangkan konteks penggunaan data tersebut dan tujuan menyeluruh yang Anda ingin mereka capai. Misalnya, tujuan untuk mencapai representasi yang setara (dalam hal ini, paritas demografis mungkin merupakan metrik yang optimal) atau apakah mencapai kesempatan yang sama (di sini, kesetaraan kesempatan mungkin yang terbaik metrik)?
Untuk mempelajari Keadilan ML lebih lanjut dan mempelajari masalah ini secara lebih mendalam, lihat Fairness and Machine Learning: Restriction and Opportunities oleh Solon Barocas, Moritz Hardt, dan Arvind Narayanan.