จนถึงตอนนี้ การพูดคุยถึงเมตริกด้านความยุติธรรมของเรามีข้อสันนิษฐานว่าการฝึกอบรมของเรา และตัวอย่างการทดสอบมีข้อมูลประชากรที่ครอบคลุม กลุ่มย่อยที่ได้รับการประเมิน แต่มักจะไม่เป็นเช่นนั้น
สมมติว่าชุดข้อมูลการสมัครเข้าเรียนมีข้อมูลประชากรไม่ครบ แต่ระบบจะบันทึกการเป็นสมาชิกกลุ่มข้อมูลประชากรเพียงไม่กี่เปอร์เซ็นต์ กลุ่มตัวอย่าง เช่น นักเรียนที่เลือกระบุด้วยตนเองว่ากลุ่มใด เป็นของ ในกรณีนี้ มีการจำแนกกลุ่มผู้สมัครเป็น "ยอมรับแล้ว" และนักเรียนที่ถูกปฏิเสธแล้ว จะมีลักษณะดังนี้
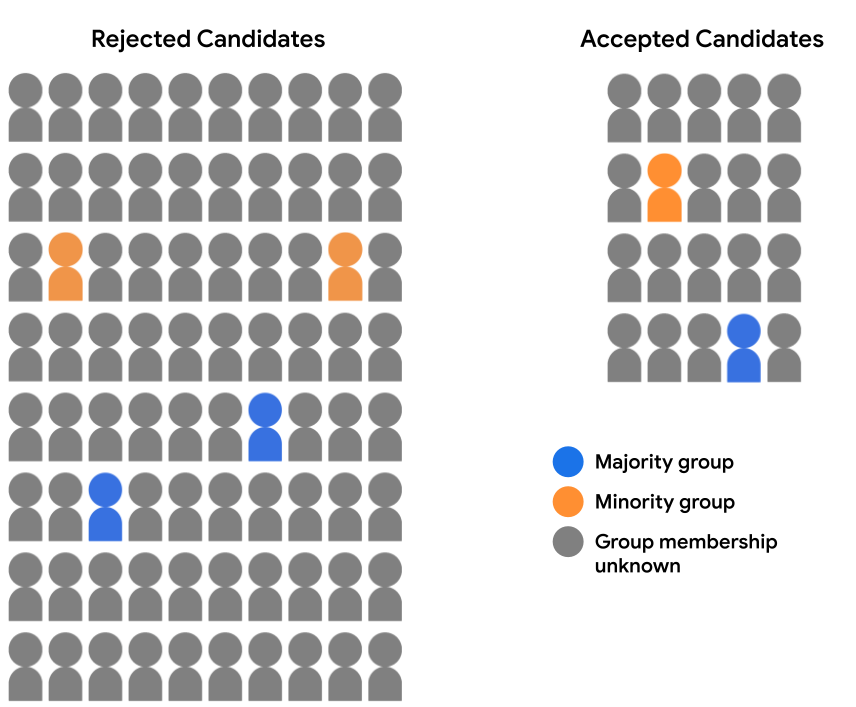
การประเมินการคาดคะเนโมเดลสำหรับข้อมูลประชากรเป็นไปไม่ได้ ความเท่าเทียมหรือความเท่าเทียมของโอกาส เนื่องจากเราไม่มีข้อมูลประชากร ตัวอย่างของเราถึง 94% อย่างไรก็ตาม สำหรับ 6% ของตัวอย่างที่มี คุณลักษณะข้อมูลประชากร เรายังคงสามารถเปรียบเทียบคู่ของการคาดการณ์ (ผู้สมัครเสียงข้างมากกับผู้สมัครที่เป็นรอง) และดูว่าพวกเขาเคยได้รับ ได้รับการปฏิบัติอย่างเท่าเทียมโดยโมเดล
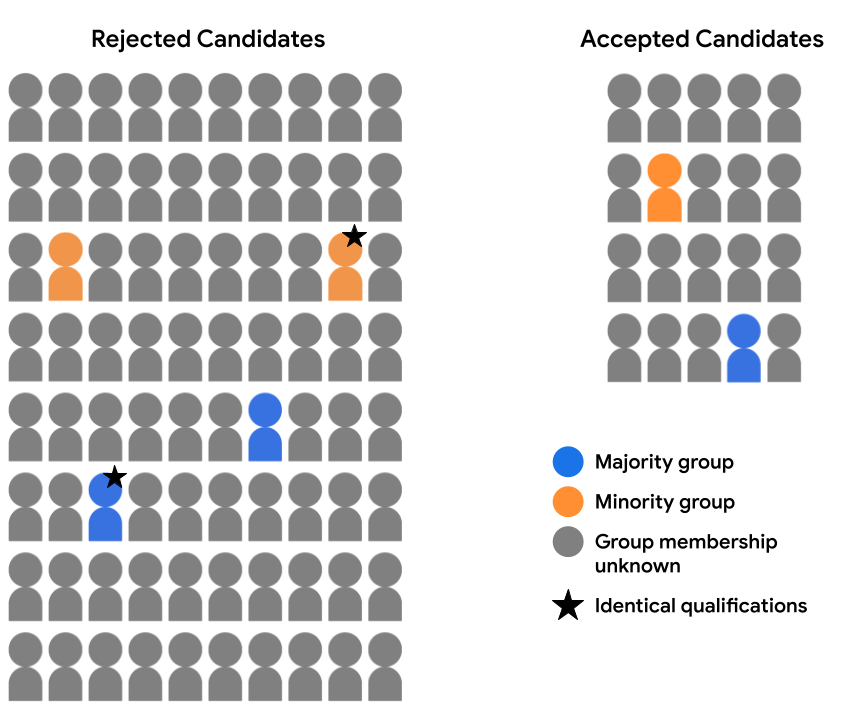
ตัวอย่างเช่น สมมติว่าเราได้ตรวจสอบข้อมูลสถานที่อย่างละเอียดแล้ว ว่างสำหรับผู้สมัคร 2 คน (1 คนในกลุ่มส่วนใหญ่และ 1 คนในกลุ่มรอง ซึ่งมีเครื่องหมายดาวในรูปภาพด้านล่าง) และได้ระบุว่า มีคุณสมบัติตรงตามเกณฑ์การรับเข้าศึกษาเหมือนกันทุกประการ หากโมเดลสร้าง การคาดคะเนเดียวกันสำหรับผู้สมัครทั้งสองนี้ (กล่าวคือ ปฏิเสธทั้ง 2 กรณี ผู้สมัครหรือยอมรับผู้สมัครทั้ง 2 ราย) ถือว่าเป็นไปตามข้อเท็จจริงที่ขัดแย้ง ความเป็นธรรมสำหรับตัวอย่างเหล่านี้ หลักความยุติธรรมในฝ่ายตรงข้ามได้ระบุเงื่อนไขว่า ตัวอย่างที่ที่เหมือนกันทุกประการ ยกเว้นแอตทริบิวต์ที่มีความละเอียดอ่อนที่ระบุ (ในที่นี้คือการเป็นสมาชิกกลุ่มข้อมูลประชากร) ควรให้ผลลัพธ์ในโมเดลเดียวกัน การคาดคะเน
ข้อดีและข้อเสีย
ดังที่กล่าวไว้ก่อนหน้านี้ ประโยชน์หลักของความเป็นธรรมที่ขัดแย้งกับข้อเท็จจริงคือ ของ Google สามารถใช้ประเมินการคาดการณ์ความเป็นธรรมในหลายกรณี เมตริกอื่นๆ เป็นไปไม่ได้ หากชุดข้อมูลไม่มีทั้งชุด ค่าฟีเจอร์สำหรับแอตทริบิวต์กลุ่มที่เกี่ยวข้องภายใต้การพิจารณาจะไม่ ประเมินความเป็นธรรมโดยใช้ความเท่าเทียมทางข้อมูลประชากรหรือความเท่าเทียมกันของ โอกาส แต่ถ้าแอตทริบิวต์กลุ่มเหล่านี้ใช้ได้กับกลุ่มย่อย ของตัวอย่าง และอาจสามารถระบุคู่ที่เทียบเคียงกันได้ เป็นตัวอย่างในกลุ่มต่างๆ ผู้ชำนาญการสามารถใช้ความเป็นธรรมที่ขัดแย้งกับข้อเท็จจริง เป็นเมตริกสำหรับตรวจสอบต้นแบบสำหรับอคติที่อาจเกิดขึ้นในการคาดการณ์
นอกจากนี้ เนื่องจากเมตริกต่างๆ เช่น ความเท่าเทียมกันของข้อมูลประชากรและความเท่าเทียมกันของ กลุ่มประเมินโอกาสโดยรวม โดยอาจปกปิดปัญหาเกี่ยวกับอคติที่ส่งผลต่อ โมเดลในระดับการคาดการณ์แต่ละรายการ ซึ่งจะแสดงได้โดย การประเมินโดยใช้ความเป็นธรรมที่ขัดแย้งกับข้อเท็จจริง ตัวอย่างเช่น สมมติว่าการสมัครของเรา แบบจำลองยอมรับผู้สมัครที่มีคุณสมบัติเหมาะสมจากกลุ่มส่วนใหญ่และชนกลุ่มน้อย ในสัดส่วนเท่ากัน แต่ผู้สมัครรับเลือกตั้งที่เป็นส่วนน้อยที่มีคุณสมบัติมากที่สุดคือ ต่างออกไป ในขณะที่ผู้สมัครเสียงข้างมากที่มีคุณสมบัติ ข้อมูลเข้าสู่ระบบได้รับการยอมรับแล้ว การวิเคราะห์ความยุติธรรมในการโต้แย้งช่วยระบุ ข้อมูลที่ไม่ตรงกันดังกล่าวเพื่อให้สามารถดำเนินการแก้ไขได้
ในอีกด้านหนึ่ง ข้อเสียหลักของความยุติธรรมที่ขัดแย้งกับข้อเท็จจริงคือ ให้ภาพรวมของอคติในการคาดการณ์โมเดล การระบุและ การแก้ไขความไม่เสมอภาคเล็กน้อยในตัวอย่างเป็นคู่อาจไม่เพียงพอ เพื่อแก้ไขปัญหาการให้น้ำหนักพิเศษอย่างเป็นระบบซึ่งส่งผลกระทบต่อตัวอย่างทั้งกลุ่มย่อย
ในกรณีที่เป็นไปได้ ผู้ปฏิบัติงานอาจพิจารณาทำทั้งข้อมูลรวม การวิเคราะห์ความเป็นธรรม (โดยใช้เมตริก เช่น ความเท่าเทียมทางข้อมูลประชากรหรือความเท่าเทียมของ ของ Google รวมถึงการวิเคราะห์ความยุติธรรมที่แยบยลซึ่งกันและกัน เพื่อให้เกิดการเข้าถึงในวงกว้างที่สุด ข้อมูลเชิงลึกเกี่ยวกับปัญหาอคติที่อาจเกิดขึ้นซึ่งจำเป็นต้องแก้ไข
แบบฝึกหัด: ตรวจสอบความเข้าใจ
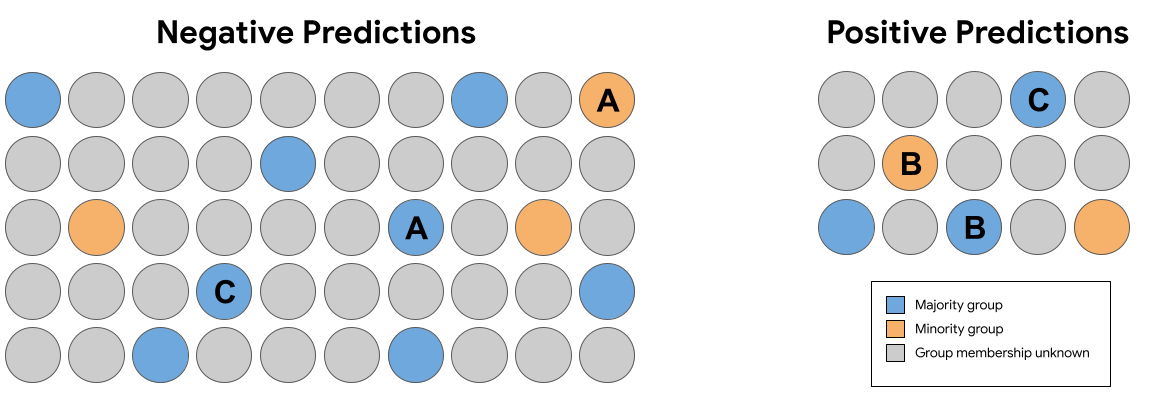
ในชุดการคาดการณ์ในรูปที่ 7 ด้านบน ซึ่งใน คู่ที่เหมือนกันต่อไปนี้ (ไม่รวมการเป็นสมาชิกกลุ่ม) ได้รับการคาดคะเนที่ละเมิดความยุติธรรมในสิ่งที่โต้แย้งกันหรือไม่
สรุป
ความเท่าเทียมกันของข้อมูลประชากร ความเท่าเทียมกันของโอกาส และความยุติธรรมในฝ่ายตรงข้าม ให้คำจำกัดความทางคณิตศาสตร์ที่แตกต่างกันสำหรับ ความเป็นธรรมสำหรับการคาดการณ์โมเดล ทั้งหมดนี้มีเพียง 3 อย่าง วิธีวัดความเป็นธรรม คำจำกัดความของความเป็นธรรมบางฉบับมีการร่วมกัน ใช้ร่วมกันไม่ได้ ซึ่งหมายความว่าเป็นไปไม่ได้ ที่เราจะตอบสนองความต้องการ จากการคาดการณ์ของโมเดล
แล้วคุณจะเลือกเกณฑ์ที่ว่า "เหมาะสม" เป็นเมตริกความเป็นธรรมสำหรับโมเดลของคุณไหม สิ่งที่คุณต้องทำ ควรพิจารณาถึงบริบทที่มีการใช้งานและเป้าหมายที่ครอบคลุมที่คุณต้องการ ที่ต้องการทำให้สำเร็จ ตัวอย่างเช่น คือเป้าหมายในการได้รับการนำเสนอที่เท่าเทียม (ในกรณีนี้ ความเท่าเทียมกันของข้อมูลประชากรอาจเป็นเมตริกที่เหมาะสมที่สุด) หรือ ได้รับโอกาสที่เท่าเทียมกัน (ในที่นี้ความเท่าเทียมของโอกาสอาจเป็นสิ่งที่ดีที่สุด )
ดูข้อมูลเพิ่มเติมเกี่ยวกับความเป็นธรรม ML และสำรวจปัญหาเหล่านี้อย่างละเอียดได้ที่ ความยุติธรรมและแมชชีนเลิร์นนิง: ข้อจำกัดและโอกาส โดย Solon Barocas, Moritz Hardt และ Arvind Narayanan