Do tej pory w dyskusjach na temat wskaźników obiektywności zakładaliśmy, że nasze szkolenia a przykłady testowe zawierają kompleksowe dane demograficzne w podgrupach. Często jednak nie.
Załóżmy, że nasz zbiór danych dotyczących rekrutacji nie zawiera pełnych danych demograficznych. Zamiast tego członkostwo w grupach demograficznych jest rejestrowane tylko dla niewielkiego odsetka użytkowników. takich jak uczniowie, którzy zdecydowali się sami określić, do której grupy należą do której należy. W tym przypadku podział puli kandydatów na zaakceptowane i odrzuceni uczniowie wyglądają teraz tak:
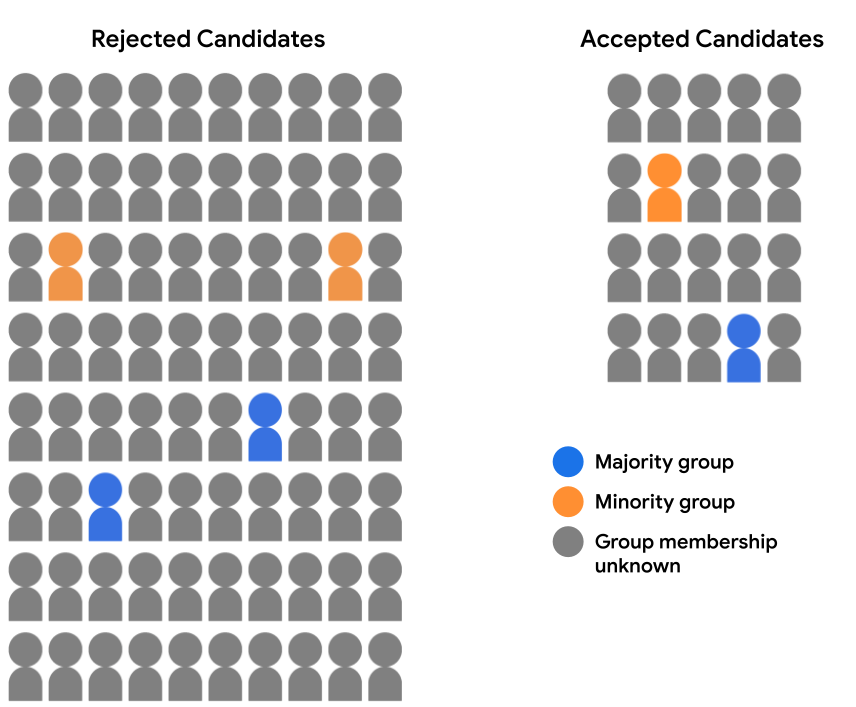
Nie można tutaj ocenić prognoz modelu dla żadnej z grup demograficznych równość szans, bo nie mamy danych demograficznych, dla 94% przykładów. 6% przykładów, które zawierają demografii, nadal możemy porównywać pary poszczególnych prognoz (kandydat partii większościowej lub mniejszościowej) i sprawdzić, czy został traktowane równomiernie przez model.
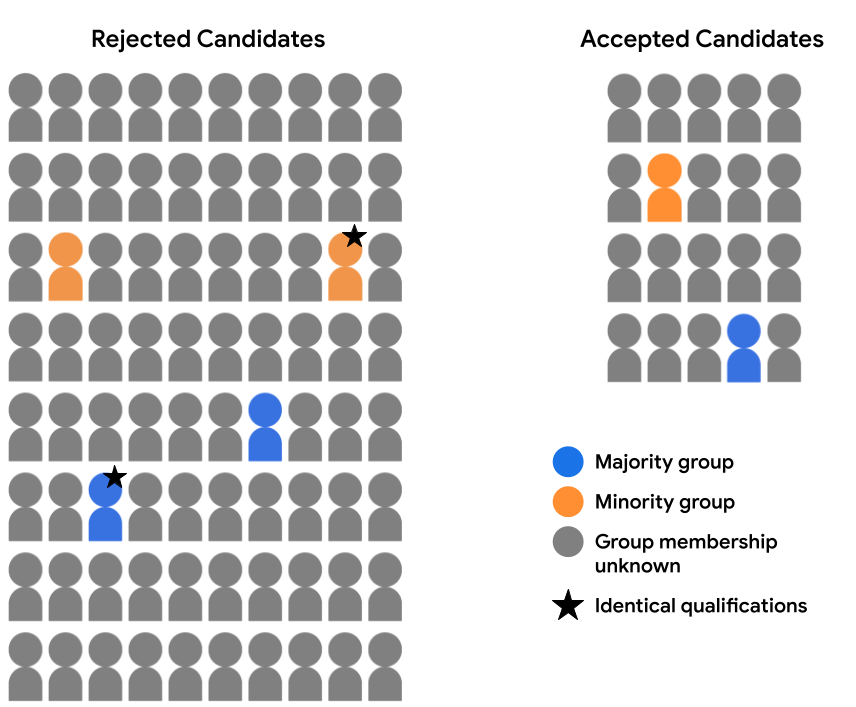
Załóżmy na przykład, że dokładnie sprawdziliśmy dane funkcji dostępne dla 2 kandydatów (1 w grupie większości, a drugiego w mniejszości grupie oznaczonych gwiazdką na poniższym obrazku) i stwierdzili, że są identyczne pod każdym względem. Jeśli model ta sama prognoza dla obu tych kandydatów (tj. obie odrzucają lub obieca kandydatów) spełnia to warunki kontrfaktyczne obiektywności w tych przykładach. Obiektywność kontrfaktyczna zakłada, że przykłady, które są identyczne pod każdym względem z wyjątkiem danego atrybutu poufnego (w tym przypadku przynależność do grupy demograficznej) powinna dawać taki sam model. z prognozą.
Zalety i wady
Jak już wspomnieliśmy, jedną z najważniejszych zalet kontrfaktycznej obiektywności jest to, że można wykorzystać do oceny obiektywności prognoz w wielu przypadkach, gdy inne dane byłyby niewykonalne. Jeśli zbiór danych nie zawiera pełnego zbioru wartości cech dla odpowiednich atrybutów grupy, nie zostanie można ocenić sprawiedliwość przy użyciu parytetu demograficznego lub równości możliwość. Jeśli jednak atrybuty grupy są dostępne dla podzbioru pozwala znaleźć porównywalne pary równoważnych w różnych grupach, przedstawiciele mogą stosować jako wskaźnika do sondowania modelu pod kątem potencjalnych uprzedzeń w prognozach.
Poza tym takie dane jak parytet demograficzny i równość demograficzna mogą zbiorczo oceniać grupy, mogą maskować problemy uprzedzenia, które wpływają model na poziomie poszczególnych prognoz, które mogą się wyświetlać do oceny z użyciem kontrfaktycznej obiektywności. Na przykład załóżmy, że kryteria przyjmowania model akceptuje zakwalifikowanych kandydatów z grupy większościowej i mniejszości ale najodpowiedniejszy kandydat do mniejszości to odrzucono, natomiast najbardziej kwalifikowany kandydat, który ma takie samo dane logowania są akceptowane. Analiza obiektywności kontrfaktycznej może pomóc określić, tego rodzaju rozbieżności, aby można je było wyeliminować.
Z drugiej strony główną wadą kontrfaktycznej obiektywności jest to, że zapewniają całościowy obraz uprzedzeń w prognozach modelu. Identyfikacja wyrównanie kilku nierówności parami przykładów może nie wystarczyć w celu rozwiązywania systemowych problemów związanych z uprzedzeniami, które wpływają na całe podgrupy przykładów.
W sytuacjach, gdy jest to możliwe, pracownicy mogą zastanowić się nad analiza obiektywności (za pomocą takich danych jak parytet demograficzny lub równość możliwości), jak również kontrfaktycznej analizy obiektywności w celu uzyskania jak najszerszego zakres statystyk dotyczących potencjalnych problemów związanych z uprzedzeniami, które wymagają działań naprawczych.
Ćwiczenie: sprawdź swoją wiedzę
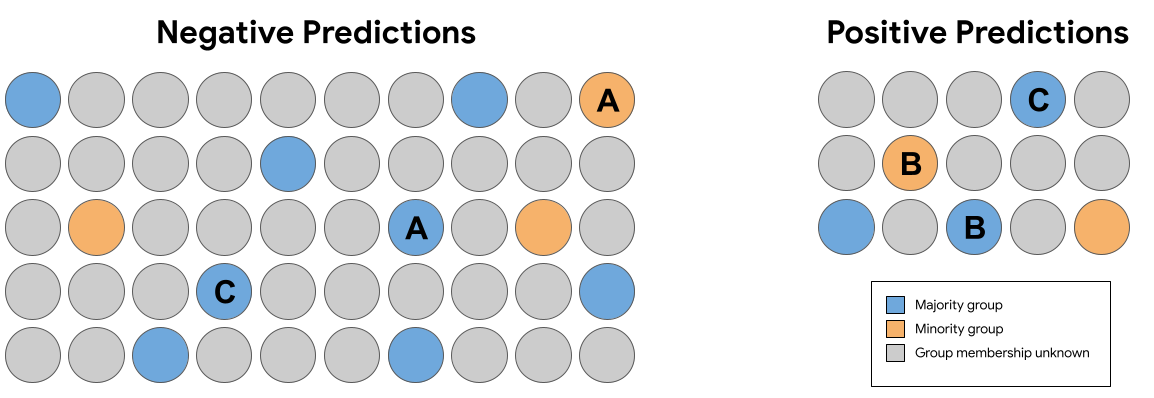
W zestawie prognoz na rys. 7 powyżej, który z poniższych następujące pary identyczne (bez członkostwa w grupie) przykłady otrzymane podpowiedzi, które naruszają kontrfaktyczną uczciwość?
Podsumowanie
Spójność demograficzna, równość szans, i kontrfaktycznej obiektywności zapewniają różne definicje matematyczne obiektywności prognoz modeli. To tylko trzy z nich, aby zmierzyć obiektywność. Niektóre definicje obiektywności są nawet wszędzie niezgodne, co oznacza, że spełnienie ich jednocześnie może być niemożliwe dla prognoz danego modelu.
Jak więc wybrać „odpowiednie” wskaźnik obiektywności Twojego modelu? Czynności, które musisz wykonać weź pod uwagę kontekst, w którym jest używana, i nadrzędne cele. do osiągnięcia. Czy na przykład czy celem jest uzyskanie równości reprezentacji (w tym przypadku optymalnym rozwiązaniem może być parytet demograficzny). osiągnąć równe szanse (w tym przypadku równość szans może być najlepszą wskaźnik)?
Aby dowiedzieć się więcej o obiektywności ML i dokładniej je przeanalizować, zobacz Fairness and Machine Learning: Limitations and Opportunity – Solon Barocas, Moritz Hardt i Arvind Narayanan.