到目前为止,我们对公平性指标的讨论假设我们的训练 和测试示例包含有关相应受众特征的全面受众特征数据 所评估的子群组。但通常并非如此。
假设我们的招生数据集不包含完整的受众特征数据。 而是仅记录一小部分受众 样本,例如选择自行标识自己属于哪个群体的学生 所属的项目。在本例中,我们将候选人群细分为已接受的候选人 和被拒绝的学生现在如下所示:
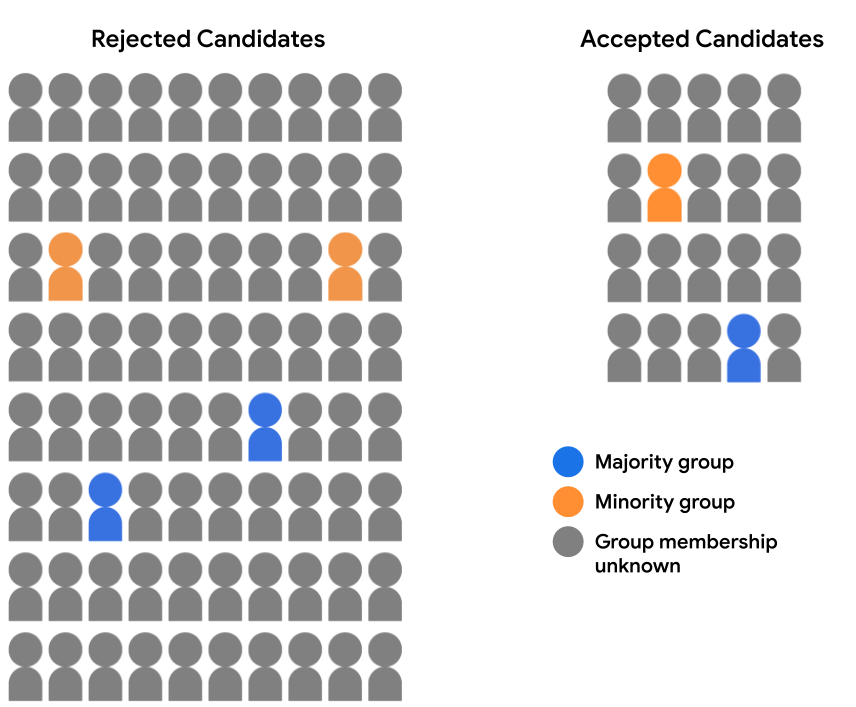
在这里评估任一受众特征的模型预测都是不可行的 因为我们没有受众特征数据, 94% 的样本。然而,对于包含 6% 的 我们仍然可以比较各个预测项的成对, (多数候选人还是少数群体候选人),看看他们是否 公平对待。
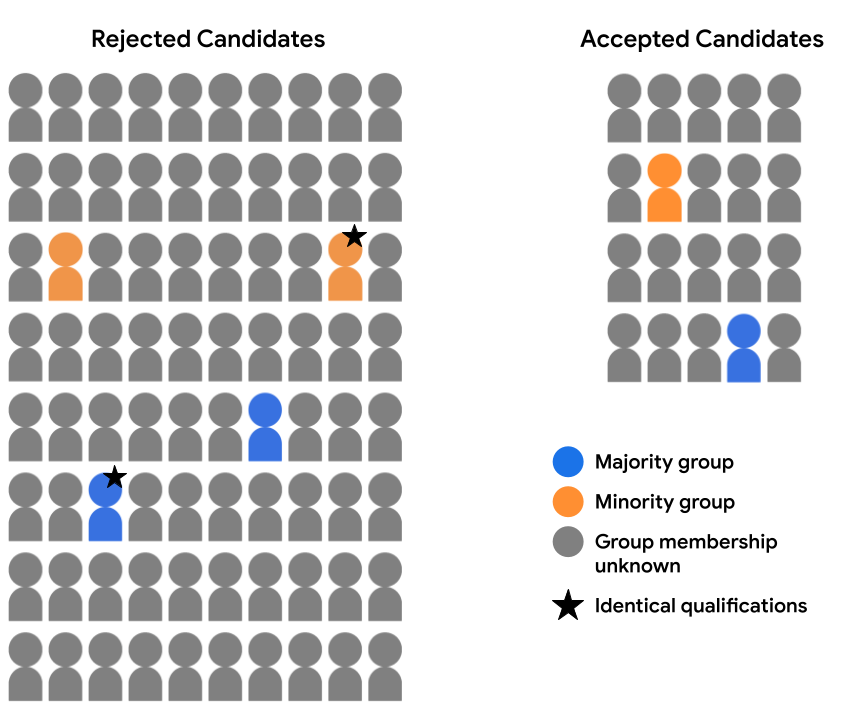
例如,假设我们已全面审核了特征数据, 有两个候选人(一个在多数党候选人中,一个在少数党候选人) 已在下图中标注了星标),并且已经确定, 完全有资格入围。如果模型 针对这两个候选字词的相同预测(即 或同时接受两个候选人),即被认为符合反事实 公平性。反事实公平性规定 除了指定的敏感属性以外,在各方面都相同 (此处为受众特征群体成员资格),应得到相同的模型 预测。
优点和缺点
如前所述,反事实性公平性的一个主要好处是, 在许多情况下,该模型可用于评估预测的公平性, 那么其他指标就不可行了。如果数据集不包含完整的 相关组属性的特征值,则不能 可以使用人口统计学平等性或 优化建议。但是,如果这些组属性适用于 并可以找出对等的等效项对, 样本,从业者可以使用反事实公平性 作为一项指标来探测模型是否存在预测中可能存在的偏差。
此外,由于受众特征对等和 对各个群体进行业务机会评估时,他们可能会掩盖影响 单个预测的级别, 使用反事实公平性进行评估。例如,假设我们的 模型接受来自多数群体和少数群体的合格候选人 但最合格的少数民族候选人才是 而最合格的多数候选人具有与 凭据。反事实公平性分析可以帮助你 以便消除这些差异
另一方面,反事实性公平的关键缺点是它 以便从整体上了解模型预测中的偏差。识别和 修正一些成对的不等式可能不够 来解决影响整个样本子群组的系统性偏见问题。
如果可以的话,从业者可以考虑同时进行汇总 公平性分析(使用人口统计学平等性或 以及反事实公平性分析,以获得最广泛的 从而了解需要补救的潜在偏见问题。
练习:检查您的理解情况
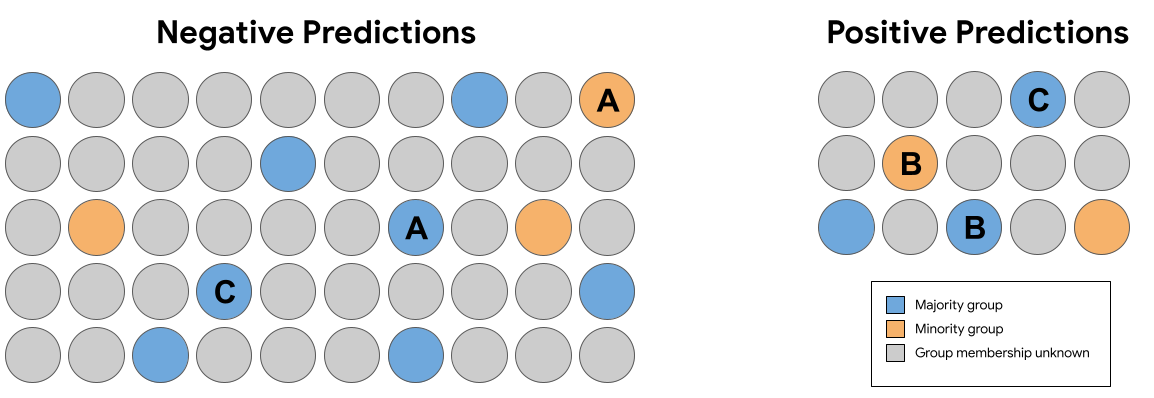 <ph type="x-smartling-placeholder">
<ph type="x-smartling-placeholder">在上面图 7 中的一组预测中, 以下几对完全相同的内容(不包括组成员) 样本收到的预测违反了反事实公平性?
摘要
受众特征对等 机会平等 和反事实公平性都提供了不同的数学定义 模型预测的公平性。以上就是 量化公平的方法某些公平的定义 不兼容, 这意味着系统可能无法同时满足 预测。
那么,如何选择“合适的”公平性指标?您需要 您需要考虑使用该工具的背景以及您设定的首要目标, 希望达成的目标例如,我们的目标是实现公平的代表性 (在此例中,受众特征对等可能是最佳指标)还是 机会平等(在这里,机会平等可能是 指标)?
如需详细了解机器学习公平性并深入探索这些问题,请参阅 Fairness and Machine Learning: Limitations and Opportunity(《公平性与机器学习:限制与机会》),作者:Solon Barocas、Moriz Hardt 和 Arvind Narayanan。