對於模型預測的公平性,我們可用來評估模型預測的公平性。 比較多數族群和少數族群的入學率 如果兩者的入學率相同,則模型的預測結果會顯示 客層一致: 學生列入大學的可能性 客層群組。
假設招聘模型接受 團體和 4 位候選人。模型的決策 滿足客層一致性,因為多數和 少數候選人為 20%
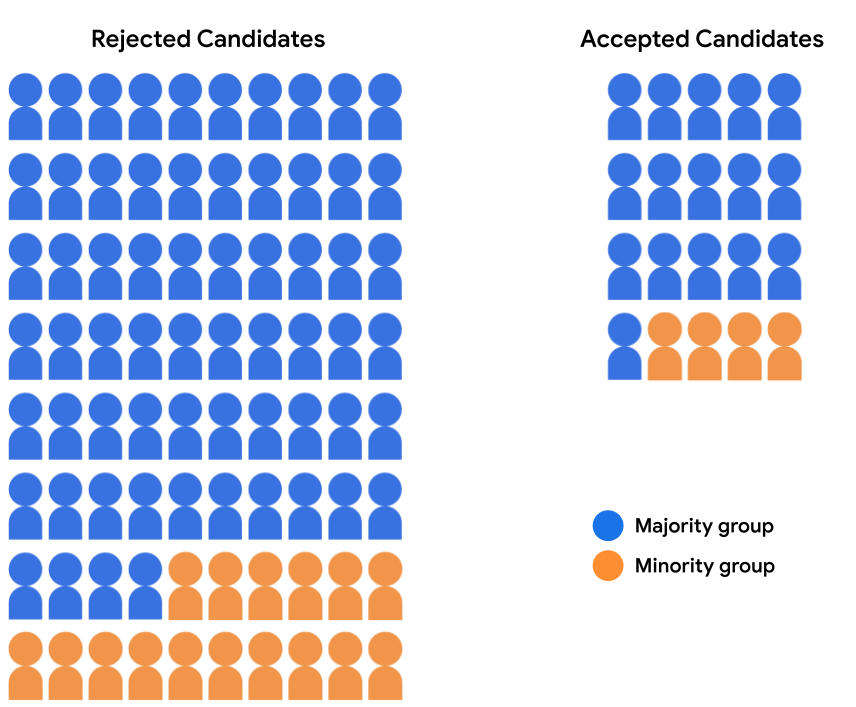
下表量化了支援遭拒和已接受的號碼 圖 2 中的候選文字。
| 多數群組 | 少數族群 | |
|---|---|---|
| 已接受 | 16 | 4 |
| 已遭拒 | 64 | 16 |
| 接受率 | 20% | 20% |
練習:檢查您的直覺
大學招生委員會目前考慮使用人口統計對等性 做為模型的公平性評估指標,需要你的指引 瞭解此方法的優缺點你可以認出一個 Pro,以及一種圖示,用來評估模型預測的表現 的同義詞?
繼續閱讀下一節:優點和 缺點:閱讀使用 客層一致性
優點和缺點
以客層平等來說,客層區隔的主要優點是 確保多數和少數族群在允許 與候選人人數相同比例的學生班。 也就是說,如果申請者是 80% 的多數候選者 和 20% 少數候選群體的候選對象,可藉由客層對等性保證, 入學者也會成為 80% 的多數學生,以及 20% 少數族群
然而,客層持平有顯著的缺點:沒有影響到 每個客層群組的預測分佈情形 ( 歸類為「合格」的學生或「不符資格」) 的情況 評估應如何分配 20 個許可版位
讓我們再看看上面的候選集區如何組成。 不過,我們這次我們不僅會按客層劃分候選人 也能衡量模型是否已將每位候選人評為「合格」或 「不合格」:

下表量化了支援遭拒和已接受的號碼 如圖 3 所示。
| 多數群組 | 少數族群 | |||
|---|---|---|---|---|
| 已接受 | 已拒絕 | 已接受 | 已拒絕 | |
| 符合資格 | 16 | 19 | 4 | 11 |
| 不符資格 | 0 | 45 | 0 | 5 |
接下來,我們來看看符合資格的學生在兩組學生的接受率:
雖然兩個群組的整體接受率都是 20%, 人口一致,合格多數學生的接受率為 46% 而合格少數學生的接受率則只有 27%。
在這些情況下,我們會先發布偏好的標籤 兩個客層 (例如「合格」的「合格」) 差異很大,客層差異可能會 並非評估公平性的最佳指標。未來 本節將探討替代公平性指標、機會品質 就必須考量這些差異