निष्पक्षता के लिए हमारे मॉडल के अनुमान का आकलन करने का एक तरीका है बहुसंख्यक समूह और अल्पसंख्यक समूह के लिए प्रवेश दर की तुलना करें. अगर एडमिशन के लिए दोनों रेट बराबर हैं, तो मॉडल के अनुमान की जानकारी डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) समानता: a छात्र-छात्राओं के यूनिवर्सिटी में दाखिल होने की संभावना अलग-अलग होती है डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) ग्रुप.
मान लीजिए कि एडमिशन मॉडल बहुमत से 16 उम्मीदवारों को स्वीकार करता है और अल्पसंख्यक समूह के चार उम्मीदवार शामिल हैं. मॉडल के फ़ैसले साथ ही, सभी लोगों के लिए अल्पसंख्यक उम्मीदवारों की हिस्सेदारी 20% है.
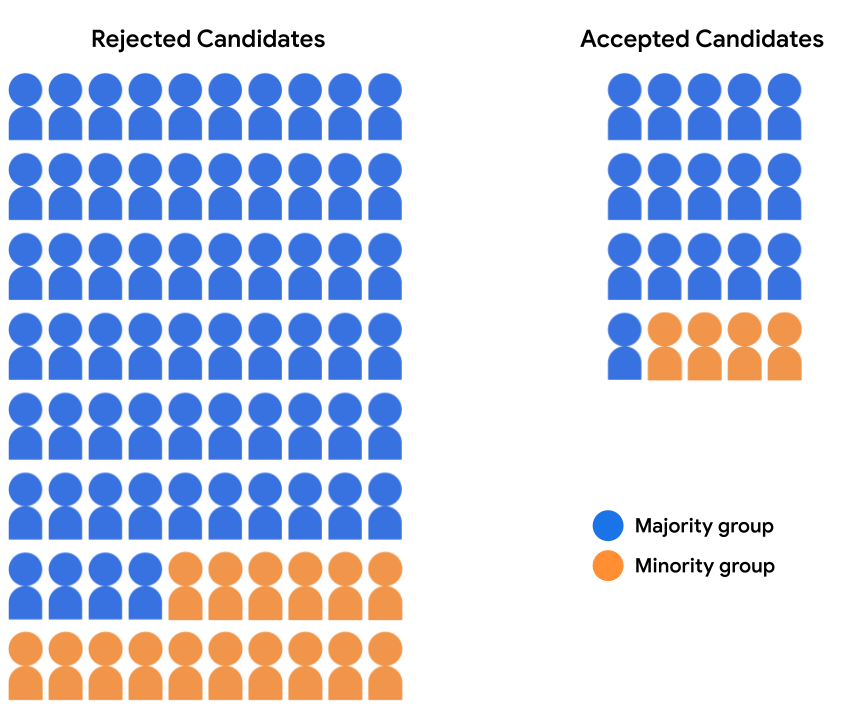
नीचे दी गई टेबल में, अस्वीकार किए गए और स्वीकार किए गए ग्राहकों की संख्या दिखाई गई है इमेज 2 में दिए गए उम्मीदवार.
| ज़्यादातर लोगों का ग्रुप | अल्पसंख्यक समूह | |
|---|---|---|
| स्वीकार किया गया | 16 | 4 |
| अस्वीकार किया गया | 64 | 16 |
| स्वीकार करने की दर | 20% | 20% |
कसरत: अपने दिल की सुनें
यूनिवर्सिटी की एडमिशन कमिटी, डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) के डेटा को एक जैसी रखने पर विचार कर रही है का आकलन कर सकता है और उन्हें आपके मार्गदर्शन की ज़रूरत है. इस तरीके के फ़ायदों और कमियों के बारे में बात करते हैं. क्या तुम इसकी पहचान कर सकती हो डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) का इस्तेमाल करके मॉडल के अनुमान का आकलन करने के लिए, pro और एक con समानता?
अगला सेक्शन, फ़ायदे और कमियां. यहां आपको इनके इस्तेमाल के मुख्य फ़ायदे और नुकसान के बारे में खास जानकारी मिलेगी डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) के बीच समानता.
फ़ायदे और कमियां
एडमिशन के लिए दिए गए हमारे उदाहरण की डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) एक जैसी होने का सबसे बड़ा फ़ायदा यह है कि यह पक्का करता है कि स्वीकार की गई उसी अनुपात में छात्र-छात्राओं की क्लास जिसमें वे कैंडिडेट पूल में हैं. इसका मतलब है कि अगर आवेदकों के पूल में बहुमत वाले ग्रुप के 80% लोग शामिल हैं और 20% अल्पसंख्यक समूह के उम्मीदवार हैं, तो डेमोग्राफ़िक समानता इस बात की गारंटी देती है कि और 20% अल्पसंख्यक समूह के छात्र-छात्राएं और 80% वयस्क समूह के छात्र-छात्राएं शामिल किए जाएंगे छात्र-छात्राएं.
हालांकि, डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) समानता की एक अहम कमी है: यह हर डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) ग्रुप के लिए अनुमानों का डिस्ट्रिब्यूशन (संख्या में) "क्वालिफ़ाइड" की कैटगरी में रखे गए छात्र-छात्राएं बनाम "अयोग्यता") को ध्यान में रखते हुए यह मूल्यांकन किया जा सकता है कि 20 एडमिशन स्लॉट कैसे तय किए जाने चाहिए.
आइए, ऊपर दिए गए हमारे ग्रुप के सदस्यों की संख्या पर दोबारा नज़र डालते हैं. हालांकि, इस बार हम उम्मीदवारों को सिर्फ़ डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) ग्रुप, यह भी देखना होगा कि मॉडल ने हर उम्मीदवार को "क्वालिफ़ाइड" के तौर पर मार्क किया है या नहीं या "अमान्य":

नीचे दी गई टेबल में, अस्वीकार किए गए और स्वीकार किए गए ग्राहकों की संख्या दिखाई गई है इमेज 3 में दिए गए उम्मीदवार.
| ज़्यादातर लोगों का ग्रुप | अल्पसंख्यक समूह | |||
|---|---|---|---|---|
| स्वीकृत | अस्वीकार किया गया | स्वीकृत | अस्वीकार किया गया | |
| क्वालिफ़ाइड | 16 | 19 | 4 | 11 |
| अमान्य | 0 | 45 | 0 | 5 |
चलिए, दोनों ग्रुप के योग्य छात्र-छात्राओं के लिए, मंज़ूरी मिलने की दरों का टेबल बनाएं:
भले ही, दोनों ग्रुप में शामिल होने की मंज़ूरी मिलने की दर 20% है, लेकिन यह अच्छा है डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) के बराबर या मुख्य तौर पर मार्क किए जाने वाले छात्र-छात्राओं की मंज़ूरी दर 46% है. वहीं, अल्पसंख्यक छात्र-छात्राओं के लिए, आवेदन स्वीकार करने की दर सिर्फ़ 27% है.
ऐसे मामलों में, जहां किसी पसंदीदा लेबल का डिस्ट्रिब्यूशन (जैसे कि "क्वालिफ़ाइड") में दोनों समूहों के लिए काफ़ी अंतर होता है. इसलिए, एक जैसी उम्र, लिंग, आय, शिक्षा वगैरह के बीच निष्पक्षता का आकलन करने के लिए, सबसे बेहतर मेट्रिक नहीं हो सकती. अगले सेशन में सेक्शन में, हम निष्पक्षता की वैकल्पिक मेट्रिक, समान अवसर, और जो इन अंतरों को ध्यान में रखती हैं.