모델을 평가할 때 전체 테스트 또는 검증을 기준으로 계산된 측정항목 모델이 얼마나 공정한지에 대한 정확한 그림을 제공하지는 않습니다. 대다수의 예시에서 전반적으로 우수한 모델 성능은 나쁨을 드러낼 수 있습니다. 성능을 평가하여 편향된 결과를 야기할 수 있습니다. 모델 예측에 사용됩니다. 다음과 같은 집계 실적 측정항목을 사용할 경우 정확도, 재현율 정확성이 반드시 좋은 것은 아닙니다 사용하여 이러한 문제를 노출할 수 있습니다
입학 모델을 다시 살펴보고 몇 가지 새로운 기법을 살펴볼 수 있습니다. 에서 공정성을 염두에 두고 예측 편향을 평가하는 방법을 알아보세요.
입학 분류 모델이 대학에 입학할 학생 20명을 선택한다고 가정해 보겠습니다. 두 인구통계 그룹에 속하는 100명의 지원자 풀에서 대학을 만들었습니다. 다수 집단 (파란색, 학생 80명)과 소수 집단 (주황색, 학생 20명)
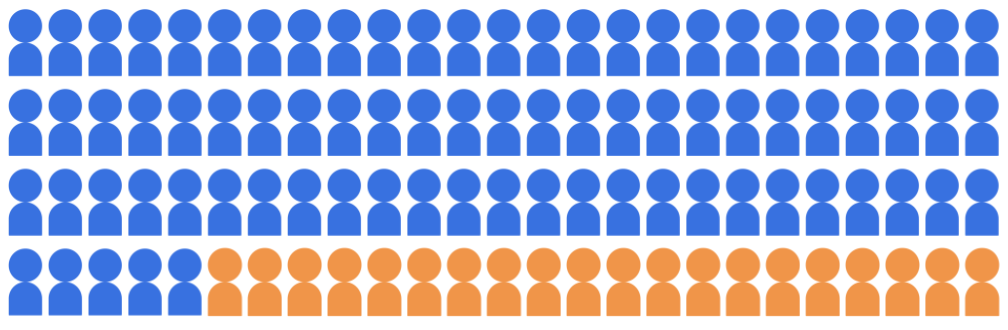
모델은 적격한 학생에 대해 공정한 방식으로 두 인구통계 그룹 모두의 후보자를 예측했습니다.
모델의 예측 공정성을 어떻게 평가해야 할까요? Vertex AI Feature Store에는 측정항목마다 다른 수학적 측정항목을 제공하여 '공정성'의 정의입니다. 다음 섹션에서는 인구통계 동등성, 기회의 균등, 반사실적 공정성입니다.