評估模型時,系統會依據整個測試或驗證計算指標 因此無法準確說明模型合理性 在大多數範例,整體模型效能都表現可能不佳 對少數樣本的執行成效,可能會導致偏誤 模型預測結果你可以使用匯總成效指標,例如 精確度、 喚回度、 且準確率也未必會降低 來暴露這些問題
我們可以回顧門票模式,並探索一些新技巧 。
假設入學分類模型選出 20 位學生參加 來自 100 位候選人的大學,且屬於以下兩個客層: 多數團體 (藍色,80 名學生) 和少數族群 (橘色,20 名學生)。
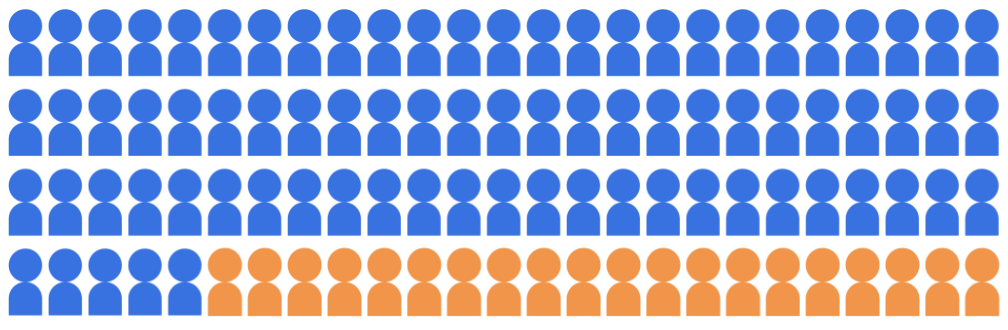
模型必須承認符合資格的學生 兩個客層內的候選人。
如何評估模型預測的公平性?有許多 各指標都提供不同的數學運算 「公平性」的定義後續各節將探討三種 包括客層公平性、商機平等 以及反事實的公平性