При оценке модели метрики, рассчитанные по всему набору тестов или проверок, не всегда дают точное представление о том, насколько справедлива модель. Хорошая производительность модели в целом для большинства примеров может маскировать плохую производительность в меньшинстве примеров, что может привести к предвзятым прогнозам модели. Использование совокупных показателей производительности, таких как точность , полнота и достоверность , не обязательно приведет к выявлению этих проблем.
Мы можем вернуться к нашей модели приема и изучить некоторые новые методы оценки ее прогнозов на предмет предвзятости с учетом справедливости.
Предположим, что модель классификации поступления выбирает 20 студентов для поступления в университет из пула из 100 кандидатов, принадлежащих к двум демографическим группам: группе большинства (синяя, 80 студентов) и группе меньшинства (оранжевая, 20 студентов).
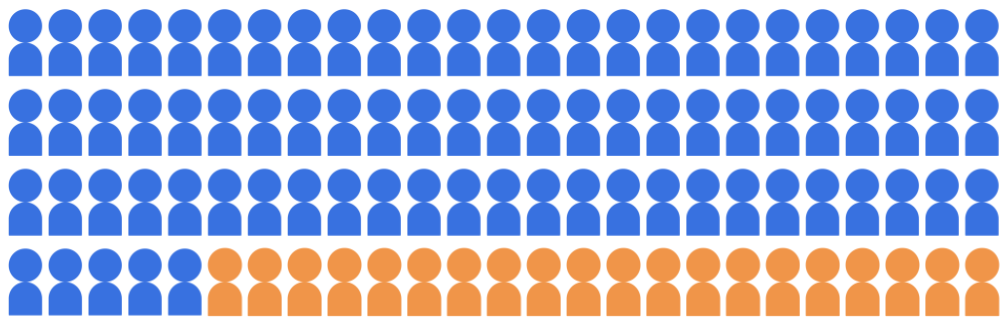
Модель должна принимать квалифицированных студентов на справедливой основе по отношению к кандидатам обеих демографических групп.
Как нам следует оценить справедливость прогнозов модели? Мы можем рассмотреть множество показателей, каждый из которых дает различное математическое определение «справедливости». В следующих разделах мы подробно рассмотрим три из этих показателей справедливости: демографический паритет, равенство возможностей и контрфактическую справедливость.