Wskaźniki obliczone na podstawie całego testu lub walidacji podczas oceny modelu nie zawsze dają dokładny obraz tego, jak obiektywny jest model. Ogólna wydajność modelu w większości przykładów może być maskowana jako niska wydajności na mniejszościach, co może prowadzić do stronniczości. i generowanie prognoz modelu. Na podstawie zbiorczych danych o skuteczności, takich jak precision, recall, a dokładność nie musi i ujawnić te problemy.
Możemy ponownie przyjrzeć się naszemu modelowi przyjmowania zgłoszeń i poznać kilka nowych technik. jak oceniać swoje prognozy pod kątem tendencyjności, mając na uwadze obiektywność.
Załóżmy, że model klasyfikacji rekrutacji wybiera 20 uczniów, którzy będą przyjmować z puli 100 kandydatów, którzy należą do dwóch grup demograficznych: grupę przeważającą (niebieską, 80 uczniów) i grupę mniejszościową. (pomarańczowy, 20 uczniów).
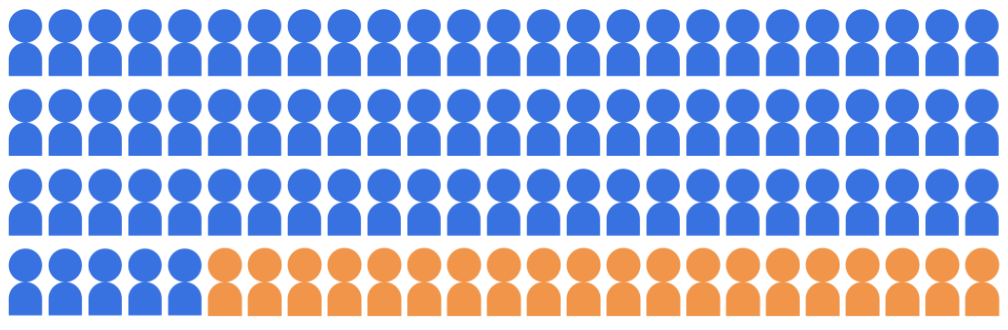
Model musi akceptować kwalifikujących się uczniów w sposób uczciwy dla kandydatów z obu grup demograficznych.
Jak należy oceniać prognozy modelu pod kątem obiektywności? Dostępne są różne typy treści. można wziąć pod uwagę różne wskaźniki, z których każdy stanowi inne definicję „uczciwości”. W kolejnych sekcjach przyjrzymy się trzem takich jak parytet demograficzny, równość szans i kontrfaktycznej obiektywności.