התאמה יתר היא יצירת מודל שמתאים (שנשמר בזיכרון) לקבוצת האימון בצורה כה קרובה, עד שהמודל לא מצליח לבצע חיזויים נכונים על נתונים חדשים. מודל עם התאמה מוגזמת דומה להמצאה שמניבה ביצועים טובים במעבדה אבל לא שווה כלום בעולם האמיתי.
באיור 11, נניח שכל צורה גיאומטרית מייצגת את המיקום של עץ ביער מרובע. המשבצות הכחולות מסמנות את המיקומים של עצים בריאים, והעיגולים הכתומים מסמנים את המיקומים של עצים חולים.

מציירים בדמיון צורות – קווים, עקומות, אובליים… כל מה שרוצים – כדי להפריד בין העצים הבריאים לעצים החולים. לאחר מכן מרחיבים את השורה הבאה כדי לבדוק אפשרות אחת להפרדה.
אפשר להרחיב את התמונה כדי לראות פתרון אפשרי אחד (איור 12).

הצורות המורכבות שמוצגות באיור 12 סווגו בהצלחה את כל העצים מלבד שניים. אם נתייחס לצורות כאל מודל, זהו מודל מצוין.
או שכן? מודל מעולה באמת מסווג בהצלחה דוגמאות חדשות. באיור 13 מוצג מה קורה כשאותו מודל מניב תחזיות לגבי דוגמאות חדשות מקבוצת הבדיקות:

לכן, המודל המורכב שמוצג באיור 12 עבד מצוין בקבוצת האימון, אבל די גרוע בקבוצת הבדיקה. זהו מקרה קלאסי של התאמה יתר של מודל לנתונים של קבוצת האימון.
התאמה, התאמה יתר (overfitting) והתאמה לא מספיקה (underfitting)
מודל צריך לספק תחזיות טובות לגבי נתונים חדשים. כלומר, המטרה היא ליצור מודל 'מתאים' לנתונים חדשים.
כפי שראיתם, מודל עם התאמה יתר מניב תחזיות מצוינות על קבוצת האימון, אבל תחזיות גרועות על נתונים חדשים. מודל לא מותאם לא מניב חיזויים טובים גם על נתוני האימון. אם מודל עם התאמה יתר הוא כמו מוצר שמניב ביצועים טובים במעבדה אבל ביצועים גרועים בעולם האמיתי, מודל עם התאמה לא מספיקה הוא כמו מוצר שלא מניב ביצועים טובים אפילו במעבדה.

הכללה היא ההפך מ-overfitting. כלומר, מודל שמתאים לנתונים כלליים מניב חיזויים טובים לגבי נתונים חדשים. המטרה היא ליצור מודל שאפשר להכליל אותו על נתונים חדשים.
זיהוי התאמת יתר (overfitting)
העקומות הבאות עוזרות לזהות התאמה יתר:
- עקומות אובדן
- עקומות הכללה
עקומת אובדן היא תרשימים של אובדן המודל מול מספר החזרות של האימון. תרשים שבו מוצגות שתי עקומות או יותר של אובדן נקרא עקומת הכללה. בתרשים ההכללה הבא מוצגים שני עקומי אובדן:
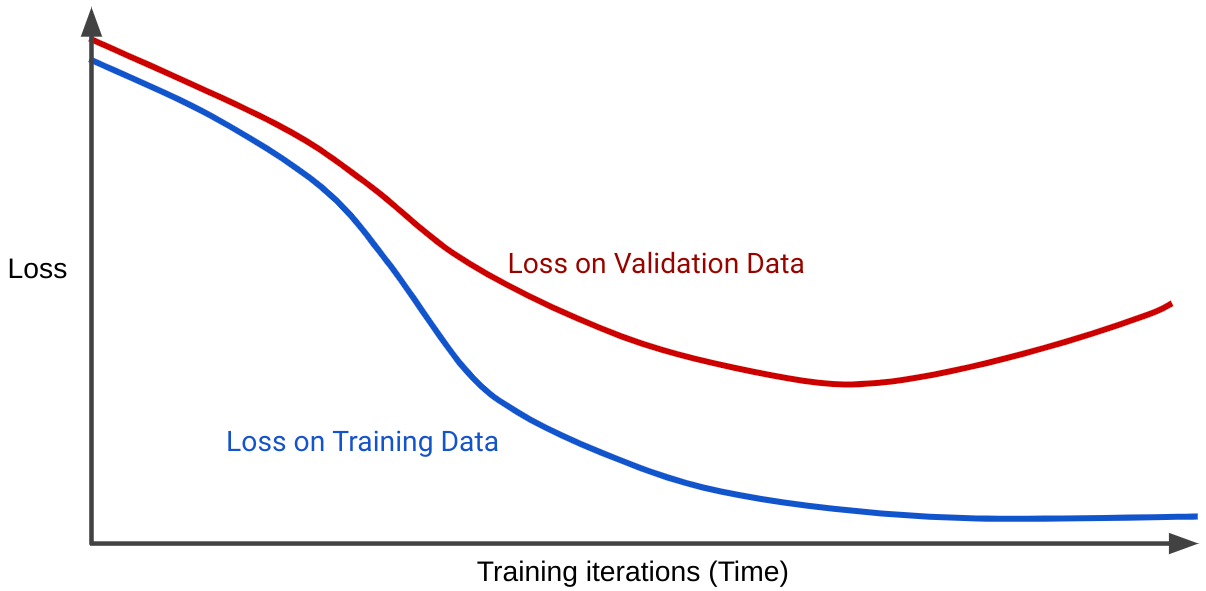
שימו לב ששתי עקומות ההפסד מתנהגות באופן דומה בהתחלה, ואז מתרחקות זו מזו. כלומר, אחרי מספר מסוים של חזרות, האובדן יורד או נשאר יציב (מתכנס) בקבוצת האימון, אבל עולה בקבוצת האימות. הנתונים האלה מצביעים על התאמה יתר.
לעומת זאת, עקומת הכללה של מודל עם התאמה טובה מציגה שתי עקומות אובדן עם צורות דומות.
מה גורם להתאמת יתר (overfitting)?
באופן כללי, התאמה יתר נובעת מאחת משתי הבעיות הבאות:
- קבוצת האימון לא מייצגת בצורה מספקת נתונים מהעולם האמיתי (או את קבוצת האימות או את קבוצת הבדיקה).
- המודל מורכב מדי.
תנאים ליצירת הכללות
מודל עובר אימון על קבוצת אימון, אבל המבחן האמיתי של ערכו הוא איך הוא מבצע חיזויים על דוגמאות חדשות, במיוחד על נתונים מהעולם האמיתי. במהלך פיתוח המודל, קבוצת הבדיקות משמשת כחלופה לנתונים מהעולם האמיתי. אימון מודל שמספק הכללות טובות מחייב את התנאים הבאים במערך הנתונים:
- הדוגמאות צריכות להיות עצמאיות ומופצות באופן זהה, כלומר הדוגמאות לא יכולות להשפיע אחת על השנייה.
- מערך הנתונים הוא סטטי, כלומר הוא לא משתנה באופן משמעותי לאורך זמן.
- למחיצות של מערך הנתונים יש אותה חלוקה. כלומר, הדוגמאות בקבוצת האימון דומות מבחינה סטטיסטית לדוגמאות בקבוצת האימות, בקבוצת הבדיקה ובנתונים מהעולם האמיתי.
אפשר לבדוק את התנאים הקודמים באמצעות התרגילים הבאים.
תרגילים: בדיקת ההבנה

תרגיל לאתגר
אתם יוצרים מודל לחיזוי התאריך האידיאלי שבו נוסעים יקנו כרטיס רכבת למסלול מסוים. לדוגמה, יכול להיות שהמודל יציע למשתמשים לקנות כרטיס ב-8 ביולי לרכבת שיוצאת ב-23 ביולי. חברת הרכבות מעדכנת את המחירים מדי שעה, על סמך מגוון גורמים, אבל בעיקר על סמך מספר המושבים הזמינים. כלומר:
- אם יש הרבה מושבים פנויים, בדרך כלל מחירי הכרטיסים נמוכים.
- אם יש מעט מאוד מושבים פנויים, מחירי הכרטיסים בדרך כלל גבוהים.
תשובה: המודל של העולם האמיתי מתקשה להתמודד עם לולאת משוב.
לדוגמה, נניח שהמודל ממליץ למשתמשים לקנות כרטיסים ב-8 ביולי. חלק מהנוסעים שמשתמשים בהמלצה של המודל קונים את הכרטיסים שלהם ב-8:30 בבוקר ב-8 ביולי. בשעה 9:00, חברת הרכבות מעלה את המחירים כי יש פחות מושבים זמינים. נוסעים שמשתמשים בהמלצה של המודל משלמים מחירים שונים. עד הערב, מחירי הכרטיסים עשויים להיות גבוהים בהרבה מאשר בבוקר.