Per overfitting si intende la creazione di un modello che corrisponde (memorizza) al set di addestramento con una tale precisione da non riuscire a fare previsioni corrette sui nuovi dati. Un modello overfit è analogo a un'invenzione che funziona bene in laboratorio, ma è inutile nel mondo reale.
Nella Figura 11, immagina che ogni forma geometrica rappresenti la posizione di un albero in una foresta quadrata. I rombi blu indicano la posizione degli alberi sani, mentre i cerchi arancioni indicano la posizione degli alberi malati.

Disegna mentalmente qualsiasi forma: linee, curve, ovali e così via per separare gli alberi sani da quelli malati. Poi, espandi la riga successiva per esaminare una possibile separazione.
Espandi per visualizzare una possibile soluzione (Figura 12).

Le forme complesse mostrate nella Figura 12 hanno classificato correttamente tutti gli alberi tranne due. Se consideriamo le forme come un modello, questo è un modello fantastico.
O no? Un modello davvero eccellente classifica correttamente gli esempi nuovi. La Figura 13 mostra cosa succede quando lo stesso modello fa previsioni su nuovi esempi del set di test:

Pertanto, il modello complesso mostrato nella Figura 12 ha ottenuto ottimi risultati sul set di addestramento, ma risultati piuttosto scadenti sul set di test. Questo è un caso classico di overfitting del modello ai dati del set di addestramento.
Adattamento, overfitting e underfitting
Un modello deve fare buone previsioni su dati nuovi. In altre parole, vuoi creare un modello che "si adatti" ai nuovi dati.
Come hai visto, un modello overfit fa previsioni eccellenti sul set di addestramento, ma previsioni scarse sui nuovi dati. Un modello sottoadattato non fa nemmeno buone previsioni sui dati di addestramento. Se un modello overfit è come un prodotto che funziona bene in laboratorio, ma male nel mondo reale, un modello underfit è come un prodotto che non funziona bene nemmeno in laboratorio.

La generalizzazione è l'opposto dell'overfitting. In altre parole, un modello che generalizza bene fa buone previsioni su nuovi dati. Il tuo obiettivo è creare un modello che si generalizzi bene ai nuovi dati.
Rilevamento dell'overfitting
Le seguenti curve ti aiutano a rilevare il sovraadattamento:
- curve di perdita
- curve di generalizzazione
Una curva di perdita traccia la perdita di un modello rispetto al numero di iterazioni di addestramento. Un grafico che mostra due o più curve di perdita è chiamato curva di generalizzazione. La seguente curva di generalizzazione mostra due curve di perdita:
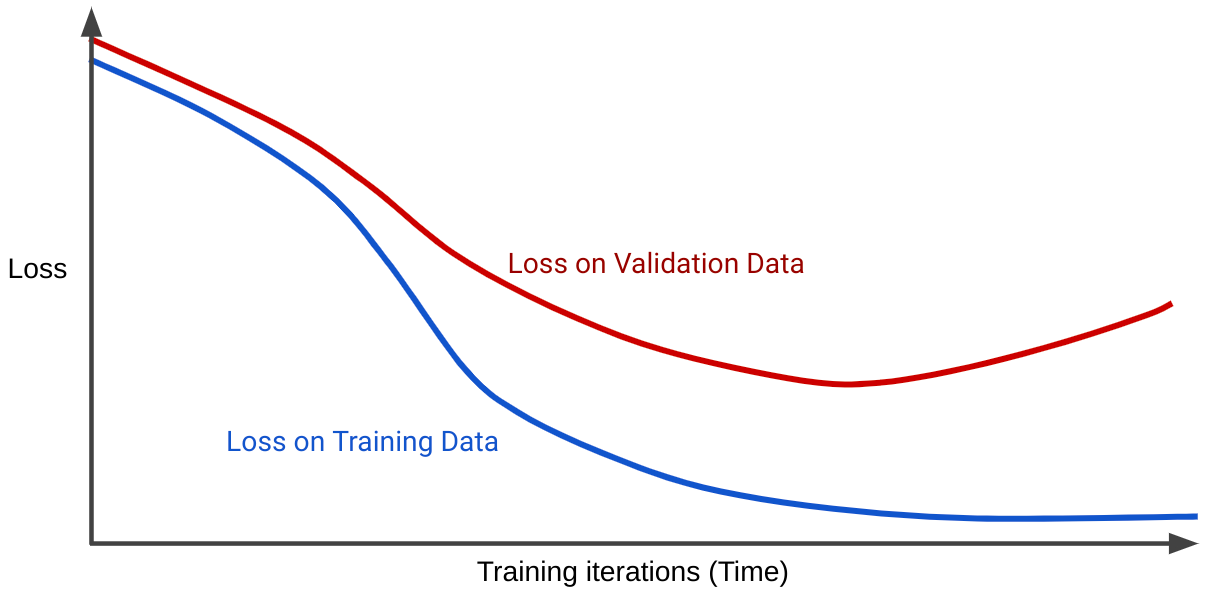
Nota che le due curve di perdita si comportano in modo simile all'inizio e poi divergono. In altre parole, dopo un certo numero di iterazioni, la perdita diminuisce o rimane invariata (converge) per il set di addestramento, ma aumenta per il set di convalida. Ciò suggerisce un overfitting.
Al contrario, una curva di generalizzazione per un modello ben adattato mostra due curve di perdita con forme simili.
Quali sono le cause dell'overfitting?
In termini molto generali, l'overfitting è causato da uno o entrambi i seguenti problemi:
- Il set di addestramento non rappresenta adeguatamente i dati reali (o il set di convalida o il set di test).
- Il modello è troppo complesso.
Condizioni di generalizzazione
Un modello viene addestrato su un set di addestramento, ma il vero test del suo valore è la sua capacità di fare previsioni su nuovi esempi, in particolare su dati reali. Durante lo sviluppo di un modello, il set di test funge da sostituto dei dati reali. L'addestramento di un modello che generalizza bene implica le seguenti condizioni del set di dati:
- Gli esempi devono essere distribuiti in modo indipendente e identico, che è un modo elegante per dire che i tuoi esempi non possono influenzarsi a vicenda.
- Il set di dati è stazionario, il che significa che non cambia in modo significativo nel tempo.
- Le partizioni del set di dati hanno la stessa distribuzione. In altre parole, gli esempi nel set di addestramento sono statisticamente simili agli esempi nel set di convalida, nel set di test e nei dati reali.
Esplora le condizioni precedenti con i seguenti esercizi.
Esercizi: verifica la comprensione

Esercizio della sfida
Stai creando un modello che preveda la data ideale per l'acquisto di un biglietto ferroviario per un determinato percorso. Ad esempio, il modello potrebbe consigliare agli utenti di acquistare il biglietto l'8 luglio per un treno che parte il 23 luglio. La compagnia ferroviaria aggiorna i prezzi ogni ora, in base a una serie di fattori, ma principalmente al numero corrente di posti disponibili. Ossia:
- Se sono disponibili molti posti, i prezzi dei biglietti sono in genere bassi.
- Se sono disponibili pochissimi posti, i prezzi dei biglietti sono in genere elevati.
Risposta: il modello del mondo reale ha difficoltà con un ciclo di feedback.
Ad esempio, supponiamo che il modello consigli agli utenti di acquistare i biglietti l'8 luglio. Alcuni passeggeri che utilizzano il consiglio del modello acquistano i biglietti alle 8:30 del mattino dell'8 luglio. Alle 9:00, la compagnia ferroviaria aumenta i prezzi perché sono disponibili meno posti. I passeggeri che utilizzano il consiglio del modello hanno modificato i prezzi. Entro la sera, i prezzi dei biglietti potrebbero essere molto più alti rispetto al mattino.