Переобучение означает создание модели, которая настолько точно соответствует ( запоминает ) обучающую выборку , что модель не может делать правильные прогнозы на новых данных. Модель переобучения аналогична изобретению, которое хорошо работает в лаборатории, но бесполезно в реальном мире.
Представьте, что на рисунке 11 каждая геометрическая фигура представляет положение дерева в квадратном лесу. Синими ромбами отмечены места расположения здоровых деревьев, а оранжевыми кружками — места больных деревьев.

Мысленно рисуйте любые фигуры — линии, кривые, овалы… что угодно — чтобы отделить здоровые деревья от больных. Затем разверните следующую строку, чтобы изучить одно возможное разделение.
Разверните, чтобы увидеть одно из возможных решений (рис. 12).

Сложные формы, показанные на рисунке 12, успешно классифицировали все деревья, кроме двух. Если мы думаем о формах как о модели, то это фантастическая модель.
Или это так? Действительно превосходная модель успешно классифицирует новые примеры. На рисунке 13 показано, что происходит, когда та же модель делает прогнозы на новых примерах из тестового набора:

Итак, сложная модель, показанная на рис. 12, отлично справилась с обучающей выборкой, но довольно плохо с тестовой. Это классический случай подгонки модели под данные обучающего набора.
Подгонка, переоснащение и недостаточная подгонка
Модель должна делать хорошие прогнозы на основе новых данных. То есть вы стремитесь создать модель, которая «соответствует» новым данным.
Как вы видели, модель переобучения дает отличные прогнозы для обучающего набора, но плохие прогнозы для новых данных. Модель недостаточного соответствия даже не дает хороших прогнозов по обучающим данным. Если модель переобучения подобна продукту, который хорошо работает в лаборатории, но плохо работает в реальном мире, то модель недостаточного соответствия подобна продукту, который не очень хорошо себя зарекомендовал даже в лаборатории.

Обобщение противоположно переоснащению. То есть модель, которая хорошо обобщает, делает хорошие прогнозы на основе новых данных. Ваша цель — создать модель, которая хорошо обобщает новые данные.
Обнаружение переобучения
Следующие кривые помогут вам обнаружить переобучение:
- кривые потерь
- кривые обобщения
Кривая потерь отображает потери модели в зависимости от количества обучающих итераций. График, на котором показаны две или более кривые потерь, называется кривой обобщения . Следующая кривая обобщения показывает две кривые потерь:
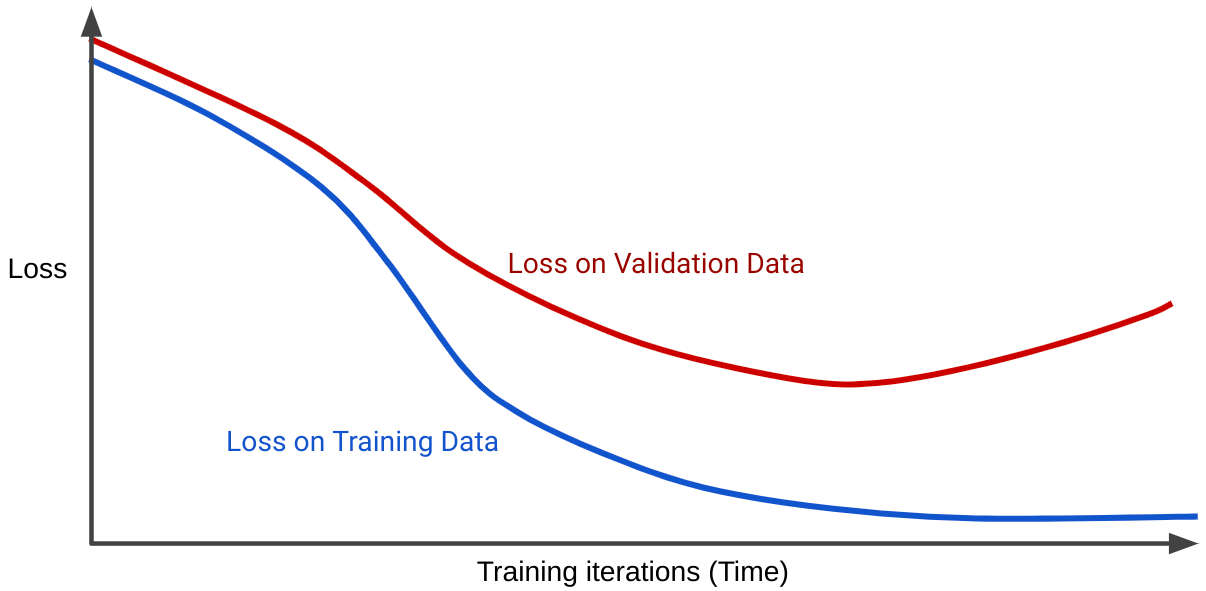
Обратите внимание, что две кривые потерь сначала ведут себя одинаково, а затем расходятся. То есть после определенного количества итераций потери уменьшаются или остаются постоянными (сходятся) для обучающего набора, но увеличиваются для проверочного набора. Это говорит о переоснащении.
Напротив, кривая обобщения для хорошо подобранной модели показывает две кривые потерь, имеющие схожую форму.
Что вызывает переобучение?
В широком смысле переоснащение вызвано одной или обеими из следующих проблем:
- Обучающий набор неадекватно представляет реальные данные (или набор проверки, или набор тестов).
- Модель слишком сложна.
Условия обобщения
Модель обучается на обучающем наборе, но настоящая проверка ценности модели заключается в том, насколько хорошо она делает прогнозы на новых примерах, особенно на реальных данных. При разработке модели ваш тестовый набор служит прокси для реальных данных. Обучение модели, которая хорошо обобщает, подразумевает следующие условия набора данных:
- Примеры должны быть независимо и одинаково распределены . Это причудливый способ сказать, что ваши примеры не могут влиять друг на друга.
- Набор данных является стационарным , то есть набор данных существенно не меняется с течением времени.
- Разделы набора данных имеют одинаковое распределение. То есть примеры в обучающем наборе статистически аналогичны примерам в проверочном наборе, тестовом наборе и реальным данным.
Изучите предыдущие состояния с помощью следующих упражнений.
Упражнения: проверьте свое понимание

Упражнение-вызов
Вы создаете модель, которая предсказывает идеальную дату для пассажиров, чтобы купить билет на поезд по определенному маршруту. Например, модель может рекомендовать пользователям купить билет 8 июля на поезд, который отправляется 23 июля. Железнодорожная компания обновляет цены ежечасно, основываясь на различных факторах, но в основном на текущем количестве доступных мест. То есть:
- Если мест много, цены на билеты обычно низкие.
- Если мест очень мало, цены на билеты обычно высокие.
Ответ: Реальная модель мира страдает от петли обратной связи .
Например, предположим, что модель рекомендует пользователям покупать билеты 8 июля. Некоторые пассажиры, воспользовавшиеся рекомендацией модели, покупают билеты в 8:30 утра 8 июля. В 9:00 железнодорожная компания повышает цены, поскольку мест становится меньше. теперь доступен. Гонщики, воспользовавшиеся рекомендациями модели, изменили цены. К вечеру цены на билеты могут оказаться намного выше, чем утром.