Overfitting หมายถึงการสร้างโมเดลที่ตรงกับ (จดจํา) ชุดข้อมูลการฝึกอย่างใกล้ชิดมากจนโมเดลไม่สามารถคาดการณ์ข้อมูลใหม่ได้อย่างถูกต้อง โมเดลที่ Overfit นั้นคล้ายกับสิ่งประดิษฐ์ที่ทํางานได้ดีในห้องทดลอง แต่ไร้ประโยชน์ในโลกแห่งความเป็นจริง
ในรูปที่ 11 ให้จินตนาการว่ารูปทรงเรขาคณิตแต่ละรูปแสดงตําแหน่งต้นไม้ในป่าสี่เหลี่ยมจัตุรัส เพชรสีน้ำเงินแสดงตำแหน่งของต้นไม้ที่แข็งแรง ส่วนวงกลมสีส้มแสดงตำแหน่งของต้นไม้ที่ป่วย

วาดรูปทรงต่างๆ ในใจ ไม่ว่าจะเป็นเส้น โค้ง รูปไข่ หรืออะไรก็ได้ เพื่อแยกต้นไม้ที่แข็งแรงออกจากต้นไม้ที่ป่วย จากนั้นขยายบรรทัดถัดไปเพื่อตรวจสอบการแยกที่เป็นไปได้รายการหนึ่ง
ขยายเพื่อดูวิธีแก้ปัญหาที่เป็นไปได้วิธีหนึ่ง (รูปที่ 12)

รูปร่างที่ซับซ้อนที่แสดงในรูปที่ 12 จัดหมวดหมู่ต้นไม้ได้ทั้งหมดยกเว้น 2 ต้น หากเราคิดว่ารูปร่างเป็นโมเดล นี่เป็นโมเดลที่ยอดเยี่ยม
หรืออาจจะยังมีหวังอยู่กันแน่นะ โมเดลที่ยอดเยี่ยมอย่างแท้จริงจะจัดหมวดหมู่ตัวอย่างใหม่ได้สําเร็จ รูปที่ 13 แสดงสิ่งที่เกิดขึ้นเมื่อโมเดลเดียวกันทำการคาดการณ์ตัวอย่างใหม่จากชุดทดสอบ

ดังนั้น โมเดลที่ซับซ้อนซึ่งแสดงในรูปที่ 12 จึงทำงานได้ดีในชุดข้อมูลการฝึก แต่ทำงานได้ไม่ดีนักในชุดทดสอบ นี่เป็นกรณีคลาสสิกของโมเดลที่ปรับให้พอดีมากเกินไปกับข้อมูลชุดการฝึก
การพอดี การพอดีมากเกินไป และการพอดีไม่เพียงพอ
โมเดลต้องทําการคาดการณ์ที่ดีกับข้อมูลใหม่ กล่าวคือ คุณกําลังพยายามสร้างโมเดลที่ "พอดี" กับข้อมูลใหม่
ดังที่คุณเห็น โมเดลที่ Overfit จะคาดการณ์ชุดข้อมูลการฝึกได้ดีมาก แต่คาดการณ์ข้อมูลใหม่ได้ไม่ดี โมเดลที่ไม่พอดีจะทำการคาดการณ์ข้อมูลการฝึกได้ไม่ดี หากโมเดลที่ Overfit เปรียบเสมือนผลิตภัณฑ์ที่ทํางานได้ดีในห้องทดลองแต่ทํางานได้ไม่ดีในชีวิตจริง โมเดลที่ Underfit ก็เปรียบเสมือนผลิตภัณฑ์ที่ทํางานได้ไม่ดีแม้แต่ในห้องทดลอง

การทั่วไปตรงข้ามกับการประมาณที่มากเกินไป กล่าวคือ โมเดลที่ทํานายได้ดีจะคาดการณ์ข้อมูลใหม่ได้ดี เป้าหมายของคุณคือสร้างโมเดลที่ทํานายข้อมูลใหม่ได้ดี
การตรวจหา Overfitting
เส้นโค้งต่อไปนี้จะช่วยคุณตรวจหาการประมาณที่มากเกินไป
- เส้นโค้งการสูญเสีย
- เส้นโค้งทั่วไป
เส้นโค้งความสูญเสียจะแสดงการสูญเสียของโมเดลเทียบกับจํานวนรอบการฝึก กราฟที่แสดงเส้นโค้งการสูญเสียตั้งแต่ 2 เส้นขึ้นไปเรียกว่าเส้นโค้งการทั่วไป เส้นโค้งทั่วไปต่อไปนี้แสดงเส้นโค้งการสูญเสีย 2 เส้น
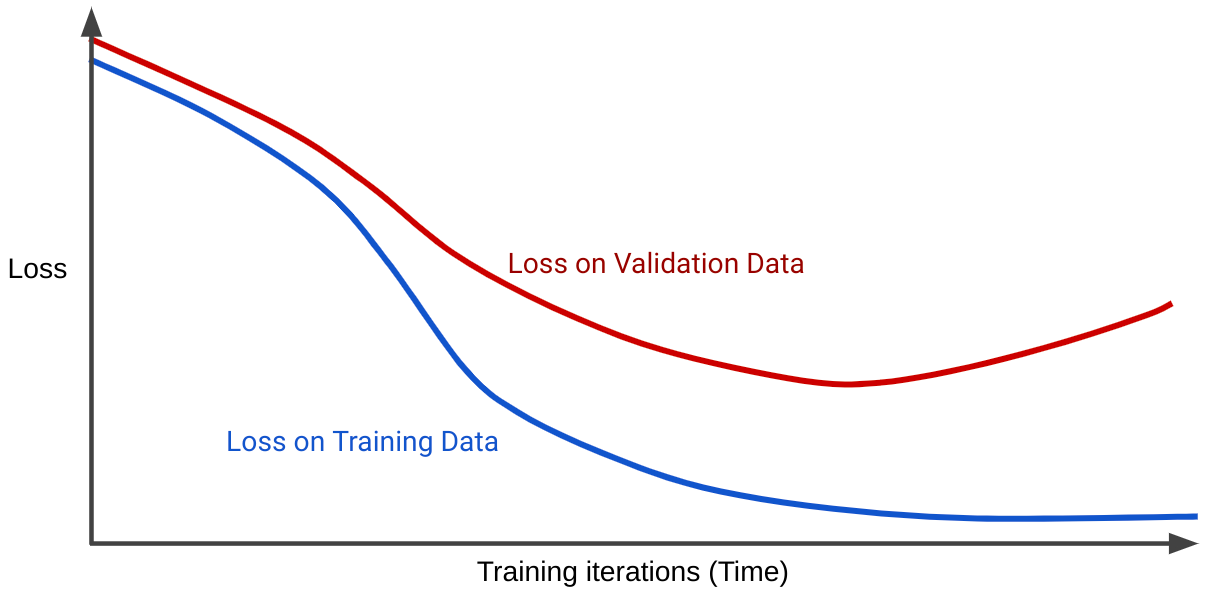
โปรดสังเกตว่าเส้นโค้งการสูญเสีย 2 เส้นมีลักษณะการทำงานคล้ายกันในช่วงแรก จากนั้นจึงแยกออกจากกัน กล่าวคือ หลังจากการวนซ้ำจำนวนหนึ่ง ความสูญเสียจะลดลงหรือคงที่ (เข้าใกล้) สำหรับชุดการฝึก แต่เพิ่มขึ้นสำหรับชุดที่ใช้ตรวจสอบ ซึ่งบ่งบอกถึงการพอดีเกิน
ในทางตรงกันข้าม เส้นโค้งทั่วไปของโมเดลที่พอดีจะแสดงเส้นโค้ง Loss 2 เส้นที่มีรูปร่างคล้ายกัน
อะไรเป็นสาเหตุของ Overfitting
พูดอย่างกว้างๆ ก็คือ การที่โมเดลเรียนรู้มากเกินไปอาจเกิดจากปัญหาอย่างใดอย่างหนึ่งหรือทั้ง 2 อย่างต่อไปนี้
- ชุดการฝึกไม่ได้แสดงถึงข้อมูลในชีวิตจริงอย่างเพียงพอ (หรือชุดตรวจสอบหรือชุดทดสอบ)
- โมเดลซับซ้อนเกินไป
เงื่อนไขทั่วไป
โมเดลจะฝึกจากชุดข้อมูลการฝึก แต่การทดสอบคุณค่าของโมเดลที่แท้จริงคือความสามารถในการคาดการณ์ตัวอย่างใหม่ โดยเฉพาะข้อมูลในชีวิตจริง ในระหว่างการพัฒนาโมเดล ชุดทดสอบจะทำหน้าที่เป็นพร็อกซีสําหรับข้อมูลในชีวิตจริง การฝึกโมเดลที่ทํานายได้ดีนั้นบ่งบอกถึงเงื่อนไขชุดข้อมูลต่อไปนี้
- ตัวอย่างต้องแจกแจงอิสระและเหมือนกัน ซึ่งเป็นวิธีพูดเก๋ๆ ว่าตัวอย่างของคุณไม่สามารถมีอิทธิพลต่อกันและกัน
- ชุดข้อมูลคงที่ ซึ่งหมายความว่าชุดข้อมูลไม่มีการเปลี่ยนแปลงมากนักเมื่อเวลาผ่านไป
- พาร์ติชันชุดข้อมูลมีการแจกแจงเดียวกัน กล่าวคือ ตัวอย่างในชุดการฝึกมีความคล้ายคลึงกับตัวอย่างในชุดการตรวจสอบ ชุดทดสอบ และข้อมูลจริงทางสถิติ
สำรวจเงื่อนไขก่อนหน้านี้ผ่านแบบฝึกหัดต่อไปนี้
แบบฝึกหัด: ทดสอบความเข้าใจ

การฝึกแบบชาเลนจ์
คุณกําลังสร้างโมเดลที่คาดการณ์วันที่เหมาะสําหรับผู้เดินทางที่จะซื้อตั๋วรถไฟสําหรับเส้นทางหนึ่งๆ เช่น โมเดลอาจแนะนําให้ผู้ใช้ซื้อตั๋วในวันที่ 8 กรกฎาคมสําหรับรถไฟที่ออกเดินทางในวันที่ 23 กรกฎาคม บริษัทรถไฟจะอัปเดตราคาเป็นรายชั่วโมง โดยอิงตามปัจจัยหลายอย่าง แต่ที่สำคัญที่สุดคือจำนวนที่นั่งว่างในปัจจุบัน โดยการ
- หากมีที่นั่งว่างจำนวนมาก ราคาตั๋วมักจะต่ำ
- หากมีที่นั่งว่างน้อยมาก ราคาตั๋วมักจะสูง
คําตอบ: โมเดลในชีวิตจริงกําลังประสบปัญหาลูปการตอบกลับ
ตัวอย่างเช่น สมมติว่าโมเดลแนะนําให้ผู้ใช้ซื้อตั๋วในวันที่ 8 กรกฎาคม ผู้เดินทางบางรายที่ใช้คําแนะนําของโมเดลซื้อตั๋วตอน 8:30 น. ของวันที่ 8 กรกฎาคม เวลา 09:00 น. บริษัทรถไฟขึ้นราคาเนื่องจากมีที่นั่งเหลือน้อยลง ผู้ขับขี่ที่ใช้คําแนะนําของโมเดลจะมีราคาที่เปลี่ยนแปลง ราคาตั๋วอาจสูงกว่าตอนเช้ามากเมื่อถึงช่วงเย็น