過度配適是指建立的模型過於貼近 (記住) 訓練集,以致模型無法針對新資料做出正確預測。過度配適的模型就像是實驗室中表現良好,但在現實世界中毫無價值的發明。
在圖 11 中,請想像每個幾何圖形都代表方形森林中的樹木位置。藍色菱形標示健康樹木的位置,而橘色圓圈則標示生病樹木的位置。

請在腦中畫出任何形狀,例如線條、曲線、橢圓形等,將健康的樹木與生病的樹木分開。接著,展開下一行,檢查一個可能的區隔。
展開可查看可能的解決方法 (圖 12)。

圖 12 中顯示的複雜形狀成功將所有樹木分類,除了兩棵樹。如果我們將形狀視為模型,那麼這就是很棒的模型。
還是說真正優異的模型可成功將新範例分類。圖 13 顯示當同一個模型針對測試集的新示例進行預測時,會發生什麼情況:

因此,圖 12 所示的複雜模型在訓練集上表現良好,但在測試集上表現不佳。這是模型過度擬合訓練集資料的經典案例。
配適、過度配適和配適不足
模型必須能針對新資料做出良好的預測。也就是說,您希望建立的模型能「適合」新資料。
如您所見,過度配適的模型可針對訓練集做出極佳的預測,但無法針對新資料做出良好的預測。欠配模型甚至無法針對訓練資料做出良好預測。如果過度配適的模型就像實驗室中表現良好,但在實際環境中成效不佳的產品,那麼欠缺配適的模型就像實驗室中表現不佳的產品。

泛化是過度擬合的相反概念。也就是說,準確度高的模型可針對新資料做出準確的預測。您的目標是建立可將新資料推廣的模型。
偵測過度配適
您可以透過下列曲線偵測過度擬合現象:
- 損失曲線
- 一般化曲線
損失曲線會根據訓練疊代次數繪製模型的損失。顯示兩個以上損失曲線的圖表稱為泛化曲線。下列概括曲線顯示兩個損失曲線:
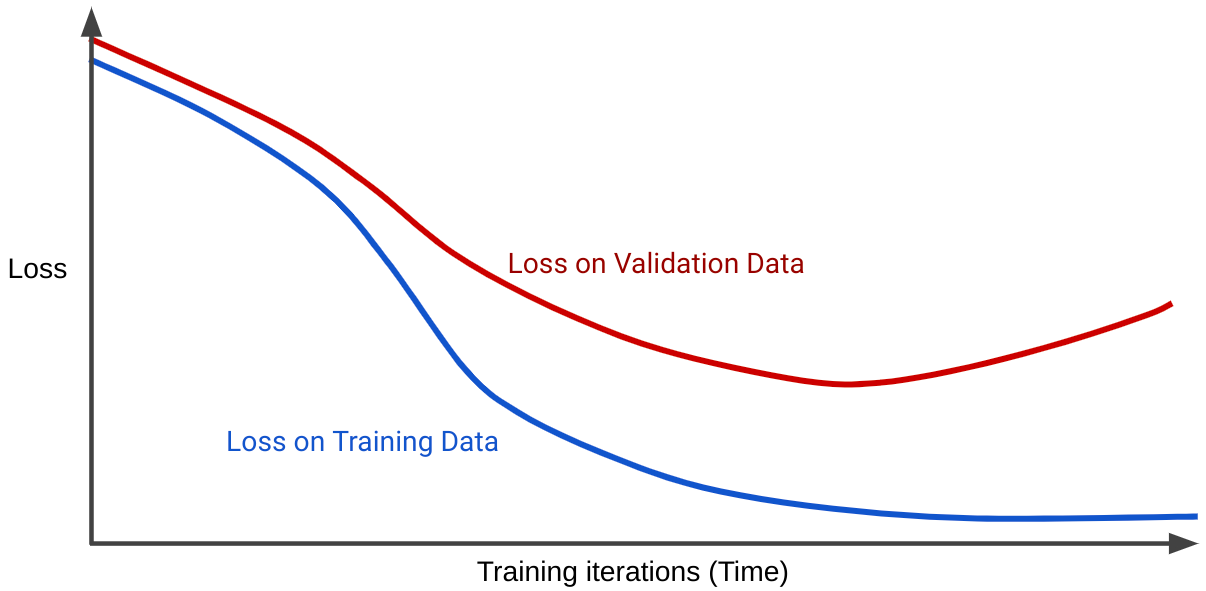
請注意,兩個損失曲線一開始的行為類似,之後就會分開。也就是說,在經過一定次疊代後,訓練集的損失會下降或保持穩定 (收斂),但驗證集的損失會增加。這表示模型過度配適。
相較之下,適當擬合模型的泛化曲線會顯示兩個形狀相似的損失曲線。
過度擬合的原因
一般來說,過度擬合是因為下列一或多個問題所致:
- 訓練集無法充分代表實際資料 (或驗證集或測試集)。
- 模型過於複雜。
一般化條件
模型會在訓練集上進行訓練,但要真正測試模型的價值,則必須觀察模型對新例子 (尤其是實際資料) 的預測能力。在開發模型時,測試集可做為實際資料的代理資料。訓練出可良好推論的模型,意味著資料集必須符合下列條件:
- 示例必須獨立且相同地分布,這句話的意思是說,示例不能相互影響。
- 資料集是靜止的,也就是說,資料集不會隨著時間而有大幅變化。
- 資料集分區的分布情形相同。也就是說,訓練集中的示例在統計上與驗證集、測試集和實際資料中的示例相似。
透過以下練習探索上述條件。
練習:測試您的理解程度

挑戰練習
您要建立的模型會預測乘客購買特定路線火車票的理想日期。舉例來說,模型可能會建議使用者在 7 月 8 日購買 7 月 23 日發車的火車票。火車公司會每小時更新價格,並根據各種因素 (主要為目前可用的座位數量) 進行更新。也就是:
- 如果座位數量充足,票價通常會較低。
- 如果座位數量不多,票價通常會很高。
答案:實際模型無法處理回饋迴路。
舉例來說,假設模型建議使用者在 7 月 8 日購買票券。部分乘客會在 7 月 8 日上午 8 點 30 分使用模型的建議功能購買車票。在 9:00,由於可預訂的座位數量減少,火車公司會調漲價格。使用模型建議的乘客會改變價格。到了晚上,票價可能會比早上高出許多。