Überanpassung bedeutet, ein Modell zu erstellen, das dem Trainings-Dataset so genau entspricht (abspeichert), dass es keine korrekten Vorhersagen für neue Daten treffen kann. Ein überangepasstes Modell ist vergleichbar mit einer Erfindung, die im Labor gut funktioniert, aber in der Praxis wertlos ist.
Stellen Sie sich in Abbildung 11 vor, dass jede geometrische Form die Position eines Baums in einem quadratischen Wald darstellt. Die blauen Rauten markieren die Standorte gesunder Bäume, während die orangefarbenen Kreise die Standorte kranker Bäume markieren.

Zeichnen Sie in Gedanken beliebige Formen – Linien, Kurven, Ovale usw. –, um die gesunden Bäume von den kranken zu unterscheiden. Maximieren Sie dann die nächste Zeile, um eine mögliche Trennung zu untersuchen.
Maximieren Sie die Ansicht, um eine mögliche Lösung zu sehen (Abbildung 12).

Mit den komplexen Formen in Abbildung 12 wurden alle Bäume bis auf zwei erfolgreich kategorisiert. Wenn wir die Formen als Modell betrachten, ist dies ein fantastisches Modell.
Oder vielleicht doch? Ein wirklich hervorragendes Modell kategorisiert neue Beispiele erfolgreich. Abbildung 13 zeigt, was passiert, wenn dasselbe Modell Vorhersagen für neue Beispiele aus dem Testsatz trifft:

Das komplexe Modell in Abbildung 12 hat also im Trainingssatz sehr gut abgeschnitten, aber im Testsatz ziemlich schlecht. Dies ist ein klassischer Fall von Überanpassung eines Modells an die Daten des Trainingssatzes.
Anpassung, Überanpassung und Unteranpassung
Ein Modell muss gute Vorhersagen für neue Daten treffen. Sie möchten also ein Modell erstellen, das zu neuen Daten passt.
Wie Sie gesehen haben, macht ein überangepasstes Modell hervorragende Vorhersagen für das Trainings-Dataset, aber schlechte Vorhersagen für neue Daten. Ein nicht hinreichend angepasstes Modell kann nicht einmal gute Vorhersagen für die Trainingsdaten treffen. Wenn ein überangepasstes Modell mit einem Produkt verglichen werden kann, das im Labor gut, aber in der Praxis schlecht abschneidet, dann ist ein nicht hinreichend angepasstes Modell mit einem Produkt vergleichbar, das nicht einmal im Labor gut abschneidet.

Generalisierung ist das Gegenteil von Überanpassung. Das heißt, ein Modell, das gut generalisiert, kann gute Vorhersagen für neue Daten treffen. Ihr Ziel besteht darin, ein Modell zu erstellen, das sich gut auf neue Daten übertragen lässt.
Überanpassung erkennen
Anhand der folgenden Kurven können Sie Überanpassung erkennen:
- Verlustkurven
- Generalisierungskurven
In einer Verlustkurve wird der Verlust eines Modells in Abhängigkeit von der Anzahl der Trainingsiterationen dargestellt. Ein Diagramm mit zwei oder mehr Verlustkurven wird als Generalisierungskurve bezeichnet. Die folgende Generalisierungskurve zeigt zwei Verlustkurven:
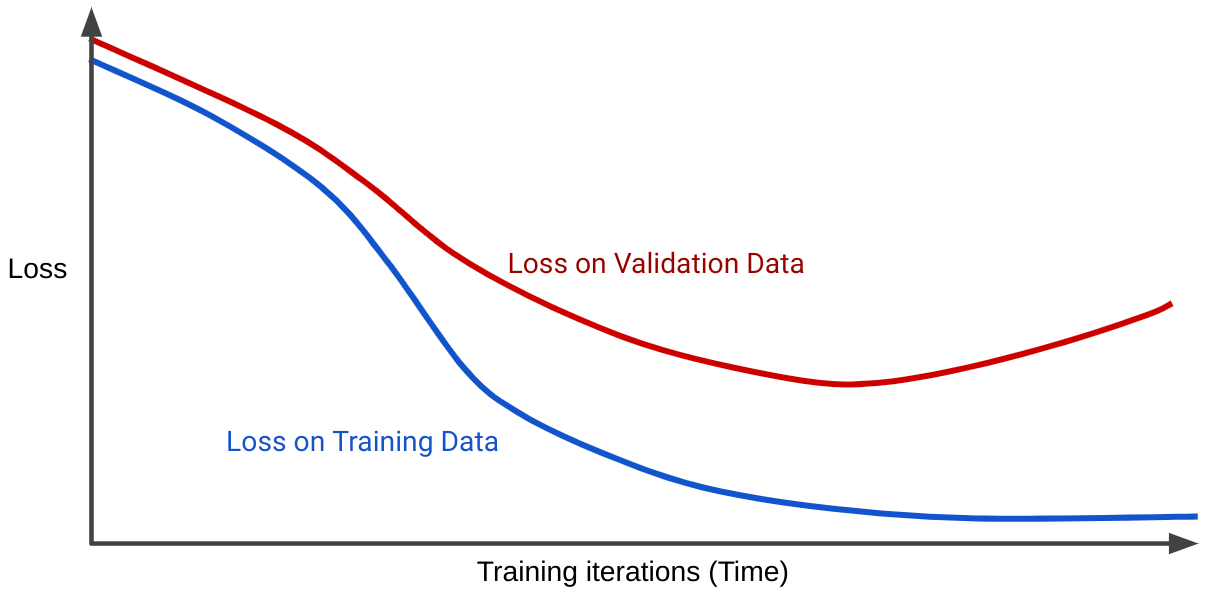
Beachten Sie, dass sich die beiden Verlustkurven anfangs ähnlich verhalten und dann auseinanderlaufen. Das heißt, nach einer bestimmten Anzahl von Iterationen sinkt der Verlust für den Trainingssatz oder bleibt konstant (konvergiert), während er für den Validierungssatz zunimmt. Dies deutet auf eine Überanpassung hin.
Im Gegensatz dazu zeigt eine Generalisierungskurve für ein gut passendes Modell zwei Verlustkurven mit ähnlicher Form.
Was führt zu einer Überanpassung?
Grob gesagt wird Überanpassung durch eines oder beide der folgenden Probleme verursacht:
- Das Trainings-, Validierungs- oder Test-Dataset repräsentiert keine realen Daten.
- Das Modell ist zu komplex.
Bedingungen für die Generalisierung
Ein Modell wird anhand eines Trainings-Datasets trainiert. Der wahre Test für den Wert eines Modells besteht jedoch darin, wie gut es Vorhersagen für neue Beispiele trifft, insbesondere für reale Daten. Bei der Entwicklung eines Modells dient Ihr Test-Dataset als Proxy für Realdaten. Für das Training eines Modells, das gut generalisiert, gelten die folgenden Dataset-Bedingungen:
- Die Beispiele müssen unabhängig und identisch verteilt sein. Das bedeutet, dass sich die Beispiele nicht gegenseitig beeinflussen dürfen.
- Der Datensatz ist stationär, d. h., er ändert sich im Laufe der Zeit nicht wesentlich.
- Die Dataset-Partitionen haben dieselbe Verteilung. Das heißt, die Beispiele im Trainingssatz sind statistisch ähnlich wie die Beispiele im Validierungssatz, Testsatz und in den Realdaten.
In den folgenden Übungen können Sie die oben genannten Bedingungen ausprobieren.
Übungen: Wissen testen

Übungsaufgabe
Sie erstellen ein Modell, das das ideale Datum für Fahrgäste vorhersagt, um ein Bahnticket für eine bestimmte Route zu kaufen. Das Modell könnte beispielsweise empfehlen, dass Nutzer ihr Ticket am 8. Juli für einen Zug kaufen, der am 23. Juli abfährt. Das Bahnunternehmen aktualisiert die Preise stündlich. Dabei werden verschiedene Faktoren berücksichtigt, vor allem aber die aktuelle Anzahl der verfügbaren Sitzplätze. Das bedeutet:
- Wenn viele Plätze verfügbar sind, sind die Ticketpreise in der Regel niedrig.
- Wenn nur sehr wenige Plätze verfügbar sind, sind die Ticketpreise in der Regel hoch.
Antwort:Das Modell der realen Welt hat Probleme mit einer Feedbackschleife.
Angenommen, das Modell empfiehlt Nutzern, am 8. Juli Tickets zu kaufen. Einige Fahrgäste, die die Empfehlung des Modells nutzen, kaufen ihre Fahrkarten am 8. Juli um 8:30 Uhr morgens. Um 9:00 Uhr erhöht das Bahnunternehmen die Preise, da jetzt weniger Sitzplätze verfügbar sind. Fahrer, die die Empfehlung des Modells verwendet haben, haben die Preise geändert. Am Abend sind die Ticketpreise möglicherweise viel höher als am Morgen.