Le surapprentissage consiste à créer un modèle qui correspond (mémorise) si étroitement à l'ensemble d'entraînement qu'il ne parvient pas à effectuer des prédictions correctes avec de nouvelles données. Un modèle suradapté est semblable à une invention qui fonctionne bien en laboratoire, mais qui est sans valeur dans le monde réel.
Dans la figure 11, imaginez que chaque forme géométrique représente la position d'un arbre dans une forêt carrée. Les losanges bleus indiquent l'emplacement des arbres sains, tandis que les cercles orange indiquent l'emplacement des arbres malades.

Dessinez mentalement des formes (lignes, courbes, ovales, etc.) pour séparer les arbres sains des arbres malades. Développez ensuite la ligne suivante pour examiner une séparation possible.
Développez la section pour voir une solution possible (figure 12).

Les formes complexes illustrées à la figure 12 ont réussi à classer tous les arbres, à l'exception de deux. Si nous considérons les formes comme un modèle, il s'agit d'un modèle fantastique.
ou presque… Un modèle vraiment excellent parvient à classer les nouveaux exemples. La figure 13 montre ce qui se passe lorsque ce même modèle effectue des prédictions sur de nouveaux exemples de l'ensemble de test:

Ainsi, le modèle complexe illustré à la figure 12 a très bien fait avec l'ensemble d'entraînement, mais très mal avec l'ensemble de test. Il s'agit d'un cas classique de surapprentissage d'un modèle par rapport aux données de l'ensemble d'entraînement.
Ajustement, surapprentissage et sous-apprentissage
Un modèle doit fournir de bonnes prédictions sur de nouvelles données. Autrement dit, vous souhaitez créer un modèle qui "s'adapte" aux nouvelles données.
Comme vous l'avez vu, un modèle suradapté effectue d'excellentes prédictions sur l'ensemble d'entraînement, mais de mauvaises prédictions sur les nouvelles données. Un modèle sous-adapté ne fournit même pas de bonnes prédictions sur les données d'entraînement. Si un modèle suradapté est comme un produit qui fonctionne bien en laboratoire, mais mal dans le monde réel, un modèle sous-adapté est comme un produit qui ne fonctionne même pas bien en laboratoire.

La généralisation est l'opposé du surapprentissage. Autrement dit, un modèle qui se prête bien à la généralisation effectue de bonnes prédictions sur les nouvelles données. Votre objectif est de créer un modèle correctement généralisable par rapport aux nouvelles données.
Détecter le surapprentissage
Les courbes suivantes vous aident à détecter un surapprentissage:
- courbes de fonction de perte
- courbes de généralisation
Une courbe de perte représente la perte d'un modèle en fonction du nombre d'itérations d'entraînement. Un graphique qui montre deux ou plusieurs courbes de perte est appelé courbe de généralisation. La courbe de généralisation suivante présente deux courbes de perte:
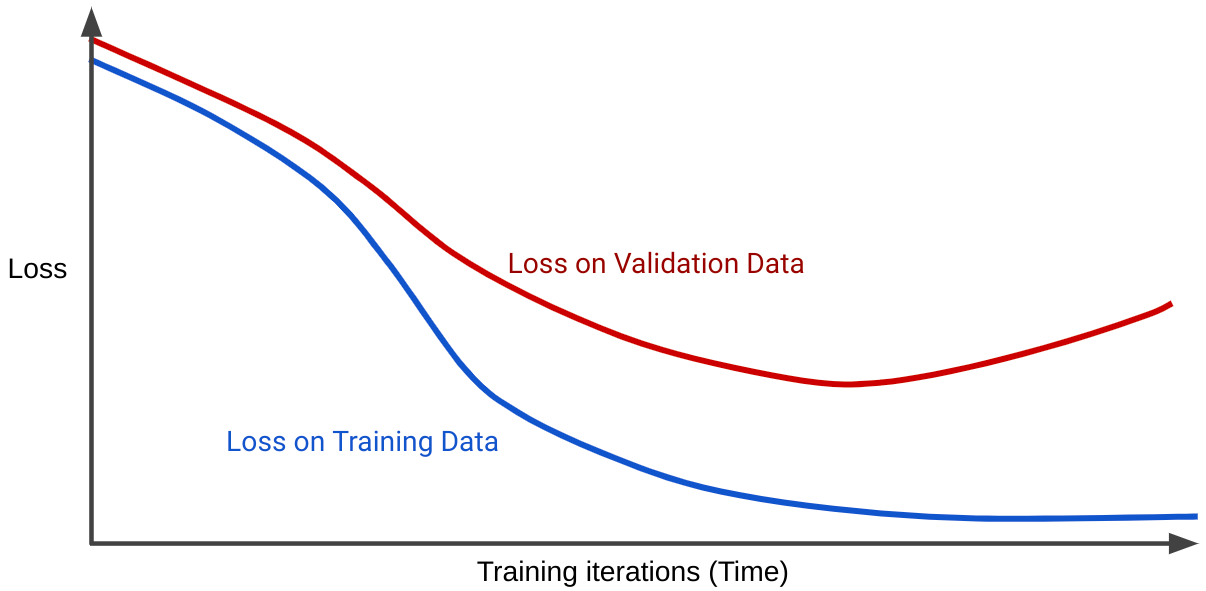
Notez que les deux courbes de perte se comportent de manière similaire au début, puis divergent. Autrement dit, après un certain nombre d'itérations, la perte diminue ou reste stable (converge) pour l'ensemble d'entraînement, mais augmente pour l'ensemble de validation. Cela suggère un surapprentissage.
En revanche, une courbe de généralisation pour un modèle bien ajusté affiche deux courbes de perte de forme similaire.
Quelles sont les causes du surapprentissage ?
De manière très générale, le surajustement est dû à l'un ou aux deux problèmes suivants:
- L'ensemble d'entraînement ne représente pas de manière adéquate les données réelles (ni l'ensemble de validation ni l'ensemble de test).
- Le modèle est trop complexe.
Conditions de généralisation
Un modèle est entraîné sur un ensemble d'entraînement, mais le véritable test de la valeur d'un modèle est la qualité de ses prédictions sur de nouveaux exemples, en particulier sur des données réelles. Lors du développement d'un modèle, votre ensemble de test sert de proxy pour les données réelles. Pour entraîner un modèle qui se généralise bien, vous devez respecter les conditions suivantes pour l'ensemble de données:
- Les exemples doivent être distribués indépendamment et de manière identique, ce qui revient à dire que vos exemples ne peuvent pas s'influencer les uns les autres.
- L'ensemble de données est stationnaire, ce qui signifie qu'il ne change pas de manière significative au fil du temps.
- Les partitions de l'ensemble de données ont la même distribution. Autrement dit, les exemples de l'ensemble d'entraînement sont statistiquement similaires aux exemples de l'ensemble de validation, de l'ensemble de test et des données réelles.
Découvrez les conditions précédentes à l'aide des exercices suivants.
Exercices: Testez vos connaissances

Exercice de défi
Vous créez un modèle qui prédit la date idéale pour que les passagers achètent un billet de train pour un trajet donné. Par exemple, le modèle peut recommander aux utilisateurs d'acheter leur billet le 8 juillet pour un train qui part le 23 juillet. La compagnie ferroviaire met à jour les prix toutes les heures, en fonction de divers facteurs, mais principalement du nombre de sièges disponibles. Par exemple :
- Si de nombreuses places sont disponibles, les prix des billets sont généralement bas.
- Si très peu de places sont disponibles, les prix des billets sont généralement élevés.
Réponse:Le modèle du monde réel rencontre des difficultés avec une boucle de rétroaction.
Par exemple, supposons que le modèle recommande aux utilisateurs d'acheter des billets le 8 juillet. Certains utilisateurs qui suivent la recommandation du modèle achètent leurs billets le 8 juillet à 8h30. À 9h, la compagnie ferroviaire augmente les prix, car moins de sièges sont désormais disponibles. Les utilisateurs qui suivent les recommandations du modèle ont modifié les prix. Le soir, les prix des billets peuvent être beaucoup plus élevés que le matin.