ओवरफ़िटिंग का मतलब है, ऐसा मॉडल बनाना जो ट्रेनिंग सेट से इतना ज़्यादा मैच (याद रखता है) करता है कि वह नए डेटा के लिए सही अनुमान नहीं लगा पाता. ओवरफ़िट मॉडल, किसी ऐसे आविष्कार की तरह है जो लैब में अच्छा परफ़ॉर्म करता है, लेकिन असल दुनिया में काम का नहीं होता.
कल्पना करें कि इमेज 11 में, हर ज्यामितीय आकार किसी स्क्वेयर फ़ॉरेस्ट में पेड़ की पोज़िशन दिखाता है. नीले रंग के डायमंड से, स्वस्थ पेड़ों की जगहों को मार्क किया जाता है, जबकि नारंगी रंग के सर्कल से, बीमार पेड़ों की जगहों को मार्क किया जाता है.

स्वस्थ पेड़ों को बीमार पेड़ों से अलग करने के लिए, मन में कोई भी आकार बनाएं—रेखाएं, कर्व, ओवल...कुछ भी. इसके बाद, अगली लाइन को बड़ा करके, अलग होने की संभावित वजह की जांच करें.
समस्या को हल करने का एक तरीका देखने के लिए, इमेज को बड़ा करें (इमेज 12).

इमेज 12 में दिखाए गए जटिल आकार, पेड़ों के दो आकारों को छोड़कर, बाकी सभी आकारों को सही कैटगरी में डाल पाए. अगर हम आकारों को मॉडल के तौर पर देखते हैं, तो यह एक बेहतरीन मॉडल है.
या फिर ऐसा होना चाहिए? बेहतरीन मॉडल, नए उदाहरणों को सही कैटगरी में बांटता है. 13वें चित्र में दिखाया गया है कि जब वही मॉडल, टेस्ट सेट के नए उदाहरणों के आधार पर अनुमान लगाता है, तो क्या होता है:

इसलिए, 12वें चित्र में दिखाया गया कॉम्प्लेक्स मॉडल, ट्रेनिंग सेट पर बेहतरीन परफ़ॉर्म करता है, लेकिन टेस्ट सेट पर बहुत खराब परफ़ॉर्म करता है. यह ट्रेनिंग सेट के डेटा के लिए, मॉडल के ओवरफ़िट होने का एक क्लासिक उदाहरण है.
फ़िटिंग, ओवरफ़िटिंग, और अंडरफ़िटिंग
मॉडल को नए डेटा के आधार पर अच्छे अनुमान लगाने चाहिए. इसका मतलब है कि आपको ऐसा मॉडल बनाना है जो नए डेटा के हिसाब से "काम" करे.
जैसा कि आपने देखा है, ओवरफ़िट मॉडल, ट्रेनिंग डेटा के लिए बेहतर अनुमान लगाता है, लेकिन नए डेटा के लिए खराब अनुमान लगाता है. अंडरफ़िट मॉडल, ट्रेनिंग डेटा के आधार पर भी अच्छे अनुमान नहीं लगाता. अगर ओवरफ़िट मॉडल, ऐसे प्रॉडक्ट की तरह है जो लैब में अच्छा परफ़ॉर्म करता है, लेकिन असल दुनिया में खराब परफ़ॉर्म करता है, तो अंडरफ़िट मॉडल, ऐसे प्रॉडक्ट की तरह है जो लैब में भी अच्छा परफ़ॉर्म नहीं करता.

जनरलाइज़ेशन, ओवरफ़िटिंग के उलट होता है. इसका मतलब है कि बेहतर तरीके से सामान्य बनाने वाला मॉडल, नए डेटा के लिए अच्छे अनुमान लगाता है. आपका लक्ष्य ऐसा मॉडल बनाना है जो नए डेटा के लिए भी काम करता हो.
ओवरफ़िटिंग का पता लगाना
इन कर्व की मदद से, ओवरफ़िटिंग का पता लगाया जा सकता है:
- लॉस कर्व
- सामान्यीकरण कर्व
लॉस कर्व, ट्रेनिंग के दोहराव की संख्या के हिसाब से मॉडल के लॉस को प्लॉट करता है. दो या उससे ज़्यादा लॉस कर्व दिखाने वाले ग्राफ़ को जनरलाइज़ेशन कर्व कहा जाता है. नीचे दिया गया जनरलाइज़ेशन कर्व, दो लॉस कर्व दिखाता है:
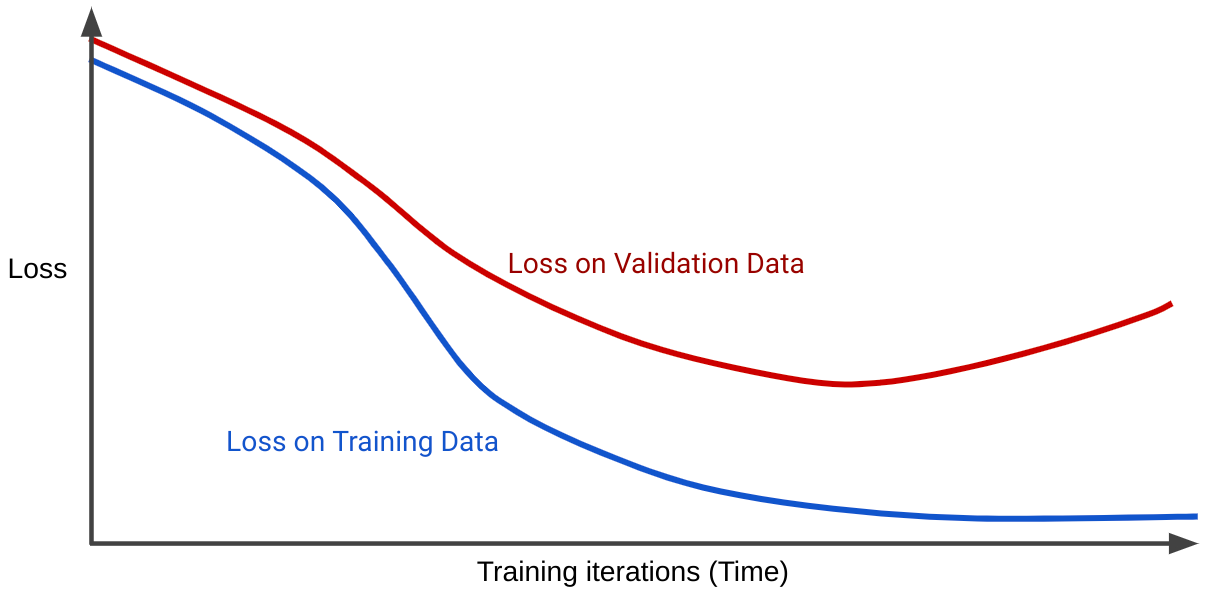
ध्यान दें कि दोनों लॉस कर्व पहले एक जैसे दिखते हैं और फिर अलग-अलग हो जाते हैं. इसका मतलब है कि कुछ बार दोहराए जाने के बाद, ट्रेनिंग सेट के लिए लॉस कम हो जाता है या एक जैसा रहता है (कंसीव हो जाता है), लेकिन पुष्टि करने वाले सेट के लिए बढ़ जाता है. इससे ओवरफ़िट होने का पता चलता है.
इसके उलट, अच्छी तरह से फ़िट किए गए मॉडल के लिए जनरलाइज़ेशन कर्व, दो लॉस कर्व दिखाता है, जिनका आकार एक जैसा होता है.
ओवरफ़िटिंग की वजह क्या है?
आम तौर पर, ओवरफ़िट होने की समस्या इनमें से किसी एक या दोनों वजहों से होती है:
- ट्रेनिंग सेट, असल ज़िंदगी के डेटा (या पुष्टि करने वाले सेट या टेस्ट सेट) को सही तरीके से नहीं दिखाता.
- मॉडल बहुत जटिल है.
सामान्य बनाने की शर्तें
मॉडल, ट्रेनिंग सेट पर ट्रेनिंग करता है. हालांकि, मॉडल की परफ़ॉर्मेंस का असली टेस्ट यह है कि वह नए उदाहरणों, खास तौर पर असल दुनिया के डेटा के आधार पर कितना अच्छा अनुमान लगाता है. मॉडल बनाते समय, आपका टेस्ट सेट असल डेटा के लिए प्रॉक्सी के तौर पर काम करता है. किसी मॉडल को अच्छी तरह से जनरलाइज़ करने के लिए, डेटासेट की ये शर्तें पूरी होनी चाहिए:
- उदाहरणों को अलग-अलग और एक जैसा डिस्ट्रिब्यूट किया जाना चाहिए. इसका मतलब है कि आपके उदाहरणों का एक-दूसरे पर असर नहीं पड़ सकता.
- डेटासेट स्टेशनरी है. इसका मतलब है कि डेटासेट में समय के साथ काफ़ी बदलाव नहीं होता.
- डेटासेट के अलग-अलग हिस्सों में डेटा का बंटवारा एक जैसा होता है. इसका मतलब है कि ट्रेनिंग सेट के उदाहरण, आंकड़ों के हिसाब से पुष्टि करने वाले सेट, टेस्ट सेट, और असल दुनिया के डेटा के उदाहरणों से मिलते-जुलते हैं.
नीचे दिए गए एक्सरसाइज़ की मदद से, ऊपर बताई गई शर्तों के बारे में जानें.
एक्सरसाइज़: देखें कि आपको क्या समझ आया

चैलेंज वाली कसरत
आपने एक ऐसा मॉडल बनाया है जो किसी खास रूट के लिए, ट्रेन का टिकट खरीदने के लिए, लोगों के हिसाब से सबसे सही तारीख का अनुमान लगाता है. उदाहरण के लिए, मॉडल यह सुझाव दे सकता है कि उपयोगकर्ता 23 जुलाई को चलने वाली ट्रेन के लिए, 8 जुलाई को अपना टिकट खरीदें. ट्रेन कंपनी हर घंटे किराये अपडेट करती है. ये अपडेट कई बातों पर आधारित होते हैं, लेकिन मुख्य रूप से उपलब्ध सीटों की संख्या पर. यानी:
- अगर ज़्यादा सीटें उपलब्ध हैं, तो आम तौर पर टिकट की कीमतें कम होती हैं.
- अगर बहुत कम सीटें उपलब्ध हैं, तो आम तौर पर टिकट की कीमतें ज़्यादा होती हैं.
जवाब: असल दुनिया का मॉडल, फ़ीडबैक लूप से जूझ रहा है.
उदाहरण के लिए, मान लें कि मॉडल यह सुझाव देता है कि उपयोगकर्ता 8 जुलाई को टिकट खरीदें. मॉडल के सुझाव का इस्तेमाल करने वाले कुछ यात्री, 8 जुलाई को सुबह 8:30 बजे टिकट खरीदते हैं. ट्रेन कंपनी, 9:00 बजे किराया बढ़ा देती है, क्योंकि अब कम सीटें उपलब्ध हैं. मॉडल के सुझाव का इस्तेमाल करने वाले लोगों ने, किराये में बदलाव किया है. शाम तक, टिकट की कीमत सुबह की तुलना में काफ़ी ज़्यादा हो सकती है.