Aşırı uyum, eğitim veri kümesiyle o kadar yakından eşleşen (ezberleyen) bir model oluşturmak anlamına gelir ki model yeni verilerle ilgili doğru tahminler yapamaz. Aşırı uyumlu bir model, laboratuvarda iyi performans gösteren ancak gerçek dünyada değersiz olan bir buluşa benzer.
Şekil 11'de her geometrik şeklin, kare şeklindeki bir ormandaki bir ağacın konumunu temsil ettiğini varsayalım. Mavi elmaslar sağlıklı ağaçların, turuncu daireler ise hasta ağaçların konumlarını gösterir.

Sağlıklı ağaçları hasta ağaçlardan ayırmak için zihinsel olarak çizgi, eğri, oval gibi şekiller çizin. Ardından, olası bir ayırmayı incelemek için bir sonraki satırı genişletin.
Olası bir çözümü görmek için alanı genişletin (Şekil 12).

Şekil 12'de gösterilen karmaşık şekiller, ağaçların ikisi dışında hepsini başarıyla sınıflandırdı. Şekilleri bir model olarak düşünürsek bu harika bir modeldir.
Yoksa mümkün mü dersiniz? Gerçekten mükemmel bir model, yeni örnekleri başarıyla kategorize eder. Şekil 13, aynı model test veri kümesindeki yeni örneklerle ilgili tahminde bulunduğunda ne olacağını gösterir:

Bu nedenle, Şekil 12'de gösterilen karmaşık model, eğitim veri kümesinde mükemmel bir performans gösterdi ancak test veri kümesinde oldukça kötü bir performans gösterdi. Bu, bir modelin eğitim veri kümesine aşırı uyum sağladığı klasik bir durumdur.
Uyumlu hale getirme, fazla uyumlu hale getirme ve yetersiz uyumlu hale getirme
Model, yeni verilerle ilgili iyi tahminler yapmalıdır. Yani yeni verilere "uyan" bir model oluşturmayı hedefliyorsunuz.
Gördüğünüz gibi, aşırı uyumlu bir model eğitim veri kümesinde mükemmel tahminler yaparken yeni verilerde kötü tahminler yapar. Yetersiz uyumlu bir model, eğitim verileri hakkında bile iyi tahminler yapamaz. Aşırı uyumlu bir model, laboratuvarda iyi ancak gerçek dünyada kötü performans gösteren bir ürün gibidir. Yetersiz uyumlu bir model ise laboratuvarda bile iyi performans göstermeyen bir ürün gibidir.

Genelleştirme, fazla uyumun tam tersidir. Yani iyi genelleme yapan bir model, yeni verilerle ilgili iyi tahminler yapar. Hedefiniz, yeni verilere iyi genelleme yapan bir model oluşturmaktır.
Fazla uyumu tespit etme
Aşağıdaki eğriler, aşırı uyumu tespit etmenize yardımcı olur:
- kayıp eğrileri
- genelleştirme eğrileri
Kayıp eğrisi, bir modelin kaybını eğitim iterasyonlarının sayısına göre gösterir. İki veya daha fazla kayıp eğrisini gösteren bir grafiğe genelleştirme eğrisi denir. Aşağıdaki genelleme eğrisinde iki kayıp eğrisi gösterilmektedir:
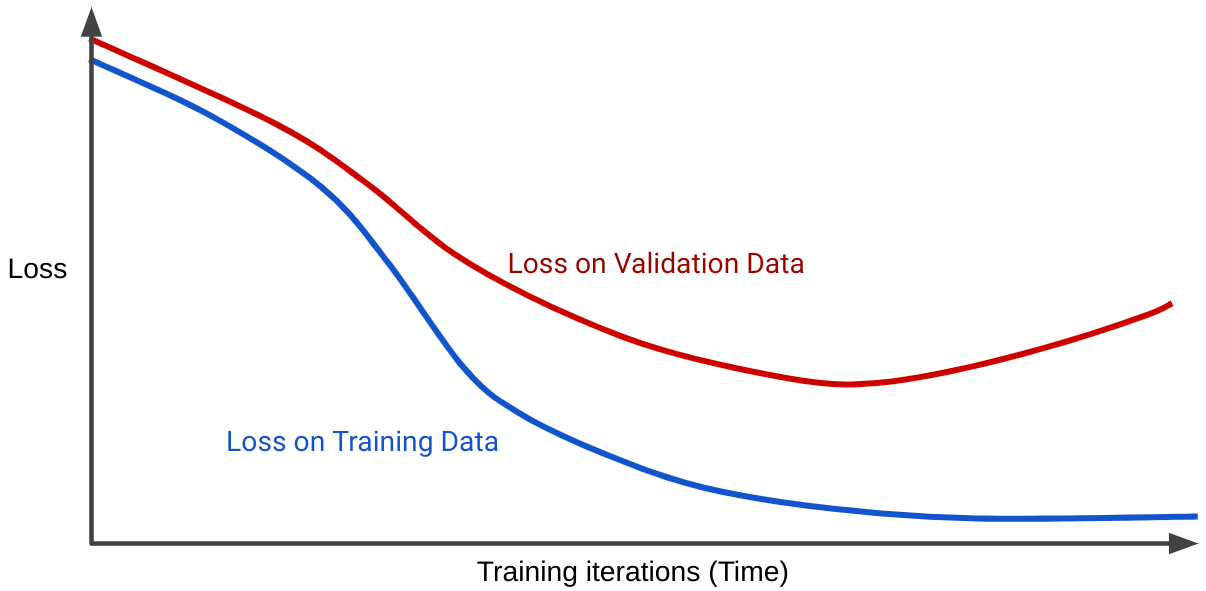
İki kayıp eğrisinin başlangıçta benzer şekilde davranıp daha sonra farklılaştığına dikkat edin. Yani belirli sayıda iterasyondan sonra kayıp, eğitim kümesi için azalır veya sabit kalır (yakınlaşır) ancak doğrulama kümesi için artar. Bu, fazla uyum olduğunu gösterir.
Buna karşılık, iyi uyumlu bir model için genelleme eğrisi, benzer şekillere sahip iki kayıp eğrisi gösterir.
Aşırı uyum sağlamaya ne neden olur?
Aşırı uyum, genel olarak aşağıdaki sorunlardan biri veya ikisinden kaynaklanır:
- Eğitim kümesi, gerçek hayat verilerini (veya doğrulama kümesini ya da test kümesini) yeterince temsil etmiyor.
- Model çok karmaşık.
Genelleştirme koşulları
Bir model, eğitim veri kümesinde eğitilir ancak modelin değerini belirleyen gerçek test, yeni örneklerde (özellikle gerçek dünyadaki verilerde) ne kadar iyi tahminde bulunduğudur. Test kümeniz, model geliştirirken gerçek dünya verileri için proxy görevi görür. İyi genelleme yapan bir model eğitmek için aşağıdaki veri kümesi koşullarını karşılamanız gerekir:
- Örnekler bağımsız ve aynı şekilde dağıtılmış olmalıdır. Bu, örneklerinizin birbirini etkileyemeyeceğinin süslü bir ifadesidir.
- Veri kümesi sabit olduğundan zaman içinde önemli ölçüde değişmez.
- Veri kümesi bölümleri aynı dağılıma sahiptir. Yani eğitim kümesindeki örnekler, doğrulama kümesindeki, test kümesindeki ve gerçek verilerdeki örneklere istatistiksel olarak benzerdir.
Aşağıdaki alıştırmalar aracılığıyla önceki koşulları keşfedin.
Alıştırmalar: Öğrendiklerinizi test edin

Zorluk alıştırması
Kullanıcıların belirli bir rota için tren bileti satın almaları için ideal tarihi tahmin eden bir model oluşturuyorsunuz. Örneğin, model kullanıcıların 23 Temmuz'da hareket edecek bir tren için biletlerini 8 Temmuz'da satın almalarını önerebilir. Tren şirketi, fiyatları çeşitli faktörlere (özellikle de mevcut koltuk sayısına) göre saatlik olarak günceller. Yani:
- Çok sayıda koltuk varsa bilet fiyatları genellikle düşüktür.
- Çok az koltuk varsa bilet fiyatları genellikle yüksektir.
Yanıt: Gerçek dünya modeli bir geri bildirim döngüsü ile mücadele ediyor.
Örneğin, modelin kullanıcılara 8 Temmuz'da bilet satın almalarını önerdiğini varsayalım. Modelin önerisini kullanan bazı yolcular, biletlerini 8 Temmuz sabahı 8:30'da satın alır. 9:00'da tren şirketi, daha az koltuk kalması nedeniyle fiyatları yükseltir. Modelin önerisini kullanan sürücüler, fiyatları değiştirdi. Akşam saatlerine doğru bilet fiyatları sabaha kıyasla çok daha yüksek olabilir.