Overfitting berarti membuat model yang cocok (mengingat) set pelatihan sehingga sangat cocok sehingga model gagal membuat prediksi yang benar pada data baru. Model yang mengalami overfitting analog dengan penemuan yang berperforma baik di lab, tetapi tidak berguna di dunia nyata.
Pada Gambar 11, bayangkan bahwa setiap bentuk geometris mewakili posisi pohon di hutan persegi. Berlian biru menandai lokasi pohon yang sehat, sedangkan lingkaran oranye menandai lokasi pohon yang sakit.

Gambar bentuk apa pun secara mental—garis, kurva, oval...apa pun—untuk memisahkan pohon yang sehat dari pohon yang sakit. Kemudian, luaskan baris berikutnya untuk memeriksa satu kemungkinan pemisahan.
Luaskan untuk melihat salah satu kemungkinan solusinya (Gambar 12).

Bentuk kompleks yang ditampilkan pada Gambar 12 berhasil mengategorikan semua kecuali dua pohon. Jika kita menganggap bentuk sebagai model, maka ini adalah model yang fantastis.
Tapi, apa benar begitu? Model yang benar-benar sangat baik berhasil mengategorikan contoh baru. Gambar 13 menunjukkan yang terjadi saat model yang sama membuat prediksi pada contoh baru dari set pengujian:

Jadi, model kompleks yang ditampilkan dalam Gambar 12 berhasil dengan baik pada set pelatihan, tetapi cukup buruk pada set pengujian. Ini adalah kasus klasik dari model yang overfitting ke data set pelatihan.
Fitting, overfitting, dan underfitting
Model harus membuat prediksi yang baik pada data baru. Artinya, Anda ingin membuat model yang "cocok" dengan data baru.
Seperti yang telah Anda lihat, model overfit membuat prediksi yang sangat baik pada set pelatihan, tetapi prediksi yang buruk pada data baru. Model underfit bahkan tidak membuat prediksi yang baik pada data pelatihan. Jika model overfit seperti produk yang berperforma baik di lab, tetapi buruk di dunia nyata, maka model underfit seperti produk yang bahkan tidak berperforma baik di lab.

Generalisasi adalah kebalikan dari overfitting. Artinya, model yang digeneralisasi dengan baik akan membuat prediksi yang baik pada data baru. Tujuan Anda adalah membuat model yang menggeneralisasi data baru dengan baik.
Mendeteksi overfitting
Kurva berikut membantu Anda mendeteksi overfitting:
- kurva penyimpangan
- kurva generalisasi
Kurva kerugian memetakan kerugian model terhadap jumlah iterasi pelatihan. Grafik yang menunjukkan dua kurva penyimpangan atau lebih disebut kurva generalisasi. Kurva generalisasi berikut menunjukkan dua kurva kerugian:
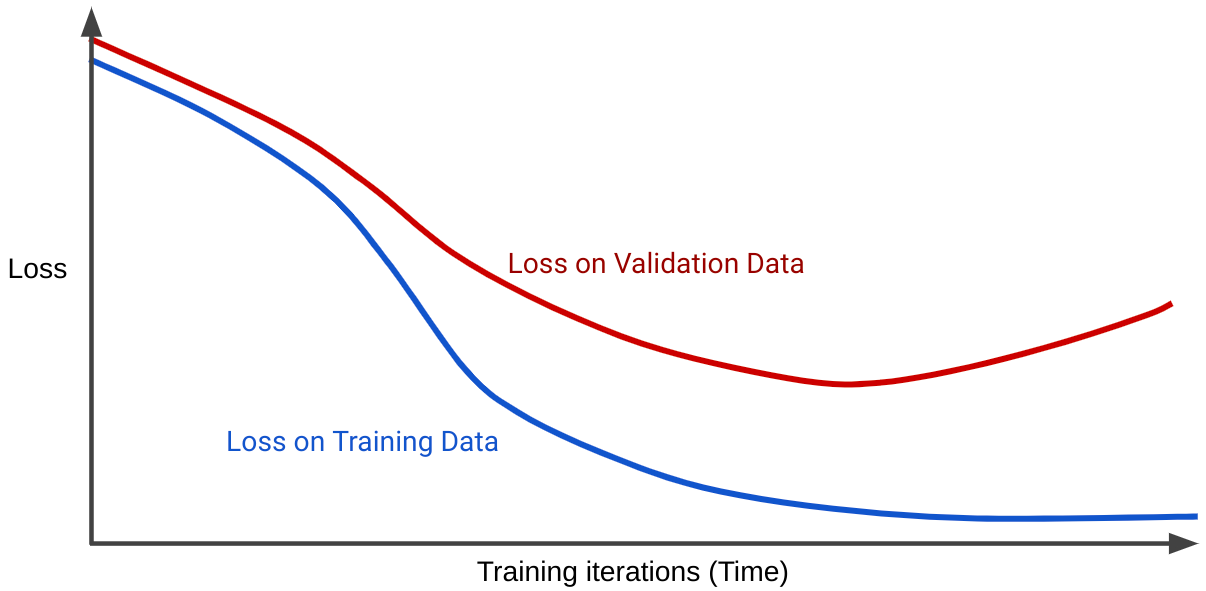
Perhatikan bahwa kedua kurva kerugian berperilaku serupa pada awalnya, lalu menyimpang. Artinya, setelah sejumlah iterasi tertentu, kerugian menurun atau tetap stabil (konvergen) untuk set pelatihan, tetapi meningkat untuk set validasi. Hal ini menunjukkan overfitting.
Sebaliknya, kurva generalisasi untuk model yang cocok menunjukkan dua kurva kerugian yang memiliki bentuk serupa.
Apa yang menyebabkan overfitting?
Secara umum, overfitting disebabkan oleh salah satu atau kedua masalah berikut:
- Set pelatihan tidak merepresentasikan data dunia nyata secara memadai (atau set validasi atau set pengujian).
- Model terlalu kompleks.
Kondisi generalisasi
Model dilatih pada set pelatihan, tetapi pengujian sebenarnya dari nilai model adalah seberapa baik model membuat prediksi pada contoh baru, terutama pada data dunia nyata. Saat mengembangkan model, set pengujian Anda berfungsi sebagai proxy untuk data dunia nyata. Melatih model yang dapat digeneralisasi dengan baik menyiratkan kondisi set data berikut:
- Contoh harus didistribusikan secara independen dan identik, yang merupakan cara keren untuk mengatakan bahwa contoh Anda tidak dapat saling memengaruhi.
- Set data bersifat stasioner, yang berarti set data tidak berubah secara signifikan dari waktu ke waktu.
- Partisi set data memiliki distribusi yang sama. Artinya, contoh dalam set pelatihan secara statistik mirip dengan contoh dalam set validasi, set pengujian, dan data dunia nyata.
Pelajari kondisi sebelumnya melalui latihan berikut.
Latihan: Periksa pemahaman Anda

Latihan tantangan
Anda membuat model yang memprediksi tanggal ideal bagi penumpang untuk membeli tiket kereta untuk rute tertentu. Misalnya, model mungkin merekomendasikan pengguna untuk membeli tiket pada 8 Juli untuk kereta yang berangkat 23 Juli. Perusahaan kereta memperbarui harga setiap jam, dengan mendasarkan pembaruan pada berbagai faktor, tetapi terutama pada jumlah kursi yang tersedia saat ini. Definisinya yaitu:
- Jika banyak kursi yang tersedia, harga tiket biasanya rendah.
- Jika hanya sedikit kursi yang tersedia, harga tiket biasanya tinggi.
Jawaban: Model dunia nyata mengalami masalah dengan loop masukan.
Misalnya, model merekomendasikan pengguna untuk membeli tiket pada 8 Juli. Beberapa penumpang yang menggunakan rekomendasi model membeli tiket mereka pada pukul 08.30 pagi pada 8 Juli. Pada pukul 09.00, perusahaan kereta menaikkan harga karena jumlah kursi yang tersedia kini lebih sedikit. Penumpang yang menggunakan rekomendasi model akan melihat perubahan harga. Pada malam hari, harga tiket mungkin jauh lebih tinggi daripada pagi hari.