Перенавчання означає створення моделі, яка відповідає навчальному набору даних (запам’ятовує його) настільки точно, що не може робити правильні прогнози на основі нових даних. Перенавчена модель подібна до винаходу, який добре працює в лабораторії, але нічого не вартий у реальному світі.
Розгляньте рисунок 11. Уявіть, що кожна геометрична фігура представляє місцеположення дерева в лісі квадратної форми. Сині ромби позначають місцеположення здорових дерев, а помаранчеві кружечки – хворих.

Подумки намалюйте лінії, криві, овали або інші форми, щоб відокремити здорові дерева від хворих. Потім розгорніть рядок нижче, щоб побачити один із можливих варіантів розділення.
Розгорніть, щоб побачити одне з можливих рішень (рисунок 12).

Завдяки складним формам, показаним на рисунку 12, удалось успішно класифікувати всі дерева, крім двох. Якщо уявити, що форми – це модель, то вона просто чудова.
Чи дійсно це так? Справді чудова модель успішно класифікує нові приклади. На рисунку 13 показано, що відбувається, коли та сама модель робить прогнози на основі нових прикладів із тестового набору.

Отже, складна модель із рисунка 12 показала хороші результати на навчальному наборі даних, але досить погані – на тестовому. Це класичний випадок перенавчання моделі на навчальному наборі даних.
Оптимальне навчання, перенавчання й недонавчання
Модель повинна робити якісні прогнози на основі нових даних. Тобто слід прагнути створити модель, яка "оптимально навчається" саме на них.
Як ви побачили, перенавчена модель робить чудові прогнози на основі навчального набору даних, але погані, коли обробляє нові. Недонавчена модель не робить хороших прогнозів, навіть коли використовуються навчальні дані. Якщо перенавчена модель схожа на продукт, який добре працює в лабораторії, але погано – у реальному світі, то недонавчена схожа на продукт, що не дає гарні результати навіть у лабораторії.

Узагальнення є протилежністю перенавчання. Тобто модель, яка добре узагальнює, робить гарні прогнози на основі нових даних. Ваша мета – створити модель, яка добре узагальнює нові дані.
Виявлення перенавчання
Виявити перенавчання допомагають такі криві:
- криві втрат;
- криві узагальнення.
Крива втрат відображає втрати моделі відносно кількості ітерацій навчання. Графік, який показує дві або більше кривих втрат, називається кривою узагальнення. На такому графіку нижче зображено дві криві втрат.
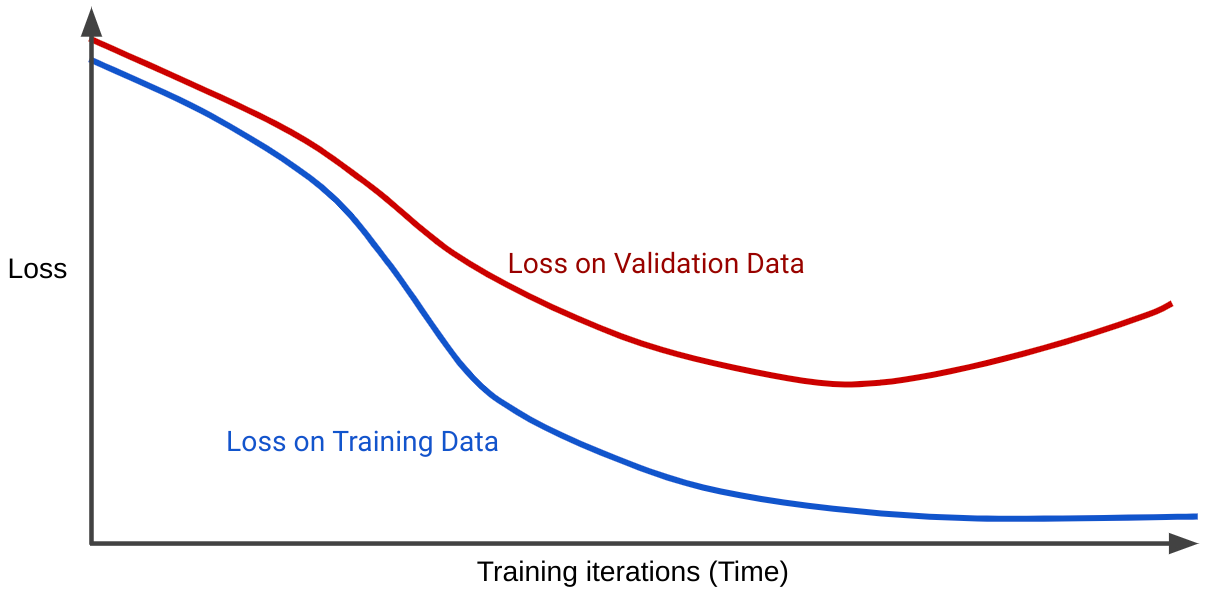
Зверніть увагу на те, що дві криві втрат спочатку поводяться однаково, а потім розходяться. Тобто після певної кількості ітерацій втрати зменшуються або залишаються стабільними (збігаються) для навчального набору, але збільшуються для набору даних для перевірки. Це говорить про перенавчання.
Крива узагальнення моделі з оптимальним навчанням – це дві криві втрат, які мають подібні форми.
Причини перенавчання
Загалом перенавчання спричиняє одна або обидві з проблем, наведених нижче.
- Набір даних для навчання (або перевірки чи тестування) неналежно відображає реальні дані.
- Модель надто складна.
Передумови узагальнення
Модель тренується на навчальному наборі даних, але її якість залежить від того, як добре вона робить прогнози для нових прикладів, зокрема реальних даних. Під час розробки моделі набір даних для тестування виконує роль проксі (замінника) реальних даних. Щоб навчити модель, яка добре узагальнює, набір даних має відповідати вимогам, описаним нижче.
- Приклади мають розподілятися незалежно й однаково, тобто не впливати один на одного.
- Набір даних має бути стаціонарним, тобто не змінюватися суттєво із часом.
- У розділах набору даних має бути однаковий розподіл, тобто приклади з навчального набору мають бути статистично подібні до тих, що містяться в наборі для перевірки, тестування й у реальних даних.
Щоб краще розібратися у вимогах, описаних вище, виконайте вправи.
Вправи. Перевірте свої знання

Складна вправа
Ви створюєте модель, яка прогнозує для пасажирів ідеальну дату покупки квитка на конкретний поїзд. Наприклад, квиток на поїзд, який відправляється 23 липня, модель може рекомендувати користувачам купувати 8 липня. Залізнична компанія оновлює ціни щогодини на основі низки факторів, але переважно на поточній кількості доступних місць. Тобто:
- якщо доступно багато місць, ціни на квитки зазвичай низькі;
- якщо доступних місць дуже мало, ціни на квитки зазвичай високі.
Відповідь. Модель, що працює на реальних даних, зіткнулася з проблемою циклу зі зворотним зв’язком.
Припустімо, що модель рекомендує користувачам купувати квитки 8 липня. Деякі пасажири, що скористалися рекомендацією моделі, купили квитки о 8:30 ранку 8 липня. О 9:00 залізнична компанія підвищила ціни, оскільки залишилося менше доступних місць. Дії пасажирів, які скористалися рекомендацією моделі, призвели до зміни цін. До вечора ціни на квитки можуть стати значно вищими, ніж були вранці.