경사하강법은 손실이 가장 낮은 모델을 생성하는 가중치와 편향을 반복적으로 찾는 수학적 기법입니다. 경사하강법은 사용자 정의 반복 횟수만큼 다음 프로세스를 반복하여 최적의 가중치와 편향을 찾습니다.
모델은 0에 가까운 무작위 가중치와 편향으로 학습을 시작한 후 다음 단계를 반복합니다.
현재 가중치와 편향으로 손실을 계산합니다.
손실을 줄이는 가중치와 편향을 이동할 방향을 결정합니다.
손실을 줄이는 방향으로 가중치와 편향 값을 약간 이동합니다.
1단계로 돌아가 모델이 손실을 더 이상 줄일 수 없을 때까지 이 과정을 반복합니다.
아래 다이어그램은 경사하강법이 손실이 가장 적은 모델을 생성하는 가중치와 편향을 찾기 위해 실행하는 반복 단계를 간략하게 보여줍니다.
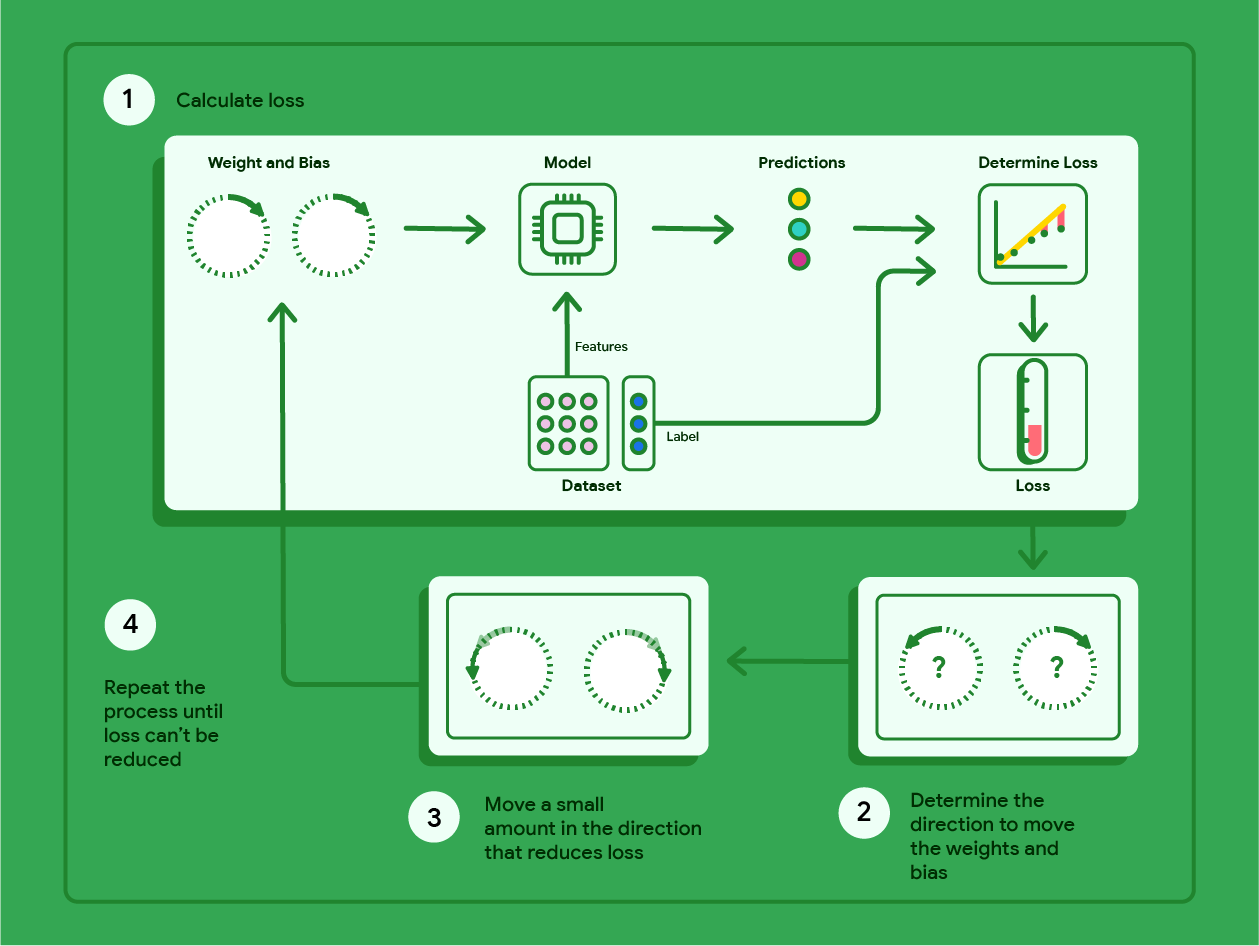
그림 11. 경사하강법은 손실이 가장 낮은 모델을 생성하는 가중치와 편향을 찾는 반복 프로세스입니다.
더하기 아이콘을 클릭하여 경사 하강법의 수학적 원리를 자세히 알아보세요.
구체적인 수준에서 자동차의 무게(파운드)와 연비 등급에 대한 예 7개가 포함된 작은 데이터 세트를 사용하여 경사하강법 단계를 살펴볼 수 있습니다.
| 파운드(1,000단위)(기능) | 갤런당 마일 (라벨) |
|---|---|
| 3.5 | 18 |
| 3.69 | 15 |
| 3.44 | 18 |
| 3.43 | 16 |
| 4.34 | 15 |
| 4.42 | 14 |
| 2.37 | 24 |
- 모델은 가중치와 편향을 0으로 설정하여 학습을 시작합니다.
- 현재 모델 매개변수로 MSE 손실을 계산합니다.
- 각 가중치와 편향에서 손실 함수의 접선의 기울기를 계산합니다.
- 음수 기울기 방향으로 조금 이동하여 다음 가중치와 편향을 얻습니다. 지금은 '소액'을 0.01로 임의로 정의합니다.
더하기 아이콘을 클릭하여 경사 계산에 대해 알아보세요.
가중치와 편향에 접하는 선의 기울기를 구하려면 가중치와 편향에 관해 손실 함수의 도함수를 구한 다음 방정식을 풉니다.
예측을 위한 방정식은 다음과 같이 작성됩니다.
$ f_{w,b}(x) = (w*x)+b $
실제 값은 $ y $로 작성됩니다.
다음 공식을 사용하여 MSE를 계산합니다.
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
여기서 $i$ 는 $i$ 번째 학습 예시를 나타내고 $M$ 은 예시 수를 나타냅니다.
가중에 대한 손실 함수의 도함수는 다음과 같이 작성됩니다.
$ \frac{\partial }{\partial w} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
다음과 같이 평가됩니다.
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2x_{(i)} $
먼저 각 예측 값에서 실제 값을 뺀 값을 합한 다음 특성 값의 두 배를 곱합니다. 그런 다음 합계를 예시 수로 나눕니다. 결과는 가중치 값에 접하는 선의 기울기입니다.
가중치와 편향이 0인 이 방정식을 풀면 선의 기울기는 -119.7이 됩니다.
편향 도함수
바이어스에 대한 손실 함수의 도함수는 다음과 같이 작성됩니다.
$ \frac{\partial }{\partial b} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
다음과 같이 평가됩니다.
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2 $
먼저 각 예측 값에서 실제 값을 뺀 값을 합한 다음 2를 곱합니다. 그런 다음 합계를 예시 수로 나눕니다. 결과는 편향 값에 접하는 선의 기울기입니다.
가중치와 편향이 0인 이 방정식을 풀면 선의 기울기는 -34.3이 됩니다.
새 가중치와 편향을 사용하여 손실을 계산하고 반복합니다. 이 프로세스를 6번 반복하면 다음 가중치, 편향, 손실이 나옵니다.
| 반복 | 무게 | 편향 | 손실 (MSE) |
|---|---|---|---|
| 1 | 0 | 0 | 303.71 |
| 2 | 1.20 | 0.34 | 170.84 |
| 3 | 2.05 | 0.59 | 103.17 |
| 4 | 2.66 | 0.78 | 68.70 |
| 5 | 3.09 | 0.91 | 51.13 |
| 6 | 3.40 | 1.01 | 42.17 |
업데이트된 가중치와 편향이 있을 때마다 손실이 낮아지는 것을 확인할 수 있습니다. 이 예에서는 6번의 반복 후에 중지했습니다. 실제로 모델은 수렴될 때까지 학습됩니다. 모델이 수렴되면 경사하강법이 손실을 거의 최소화하는 가중치와 편향을 찾았기 때문에 추가 반복을 해도 손실이 더 줄어들지 않습니다.
모델이 수렴 후에도 계속 학습하면 모델이 최저값 주변의 매개변수를 계속 업데이트하므로 손실이 약간씩 변동하기 시작합니다. 이로 인해 모델이 실제로 수렴되었는지 확인하기 어려울 수 있습니다. 모델이 수렴되었는지 확인하려면 손실이 안정화될 때까지 학습을 계속해야 합니다.
모델 수렴 및 손실 곡선
모델을 학습할 때 손실 곡선을 살펴보고 모델이 수렴했는지 확인하는 경우가 많습니다. 손실 곡선은 모델이 학습됨에 따라 손실이 어떻게 변하는지 보여줍니다. 일반적인 손실 곡선은 다음과 같습니다. 손실은 y축에 있고 반복은 x축에 있습니다.
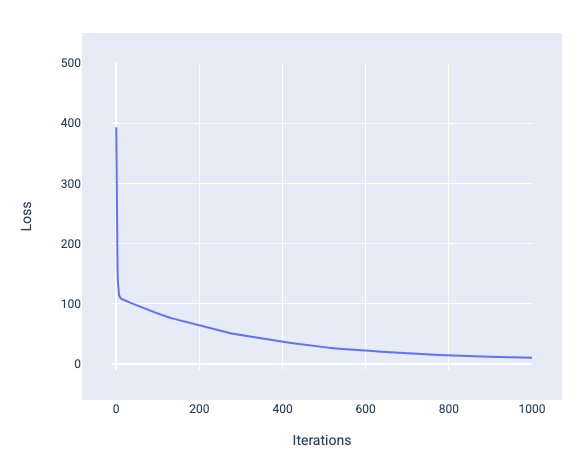
그림 12. 모델이 1,000번째 반복 표시 근처로 수렴하는 것을 보여주는 손실 곡선
처음 몇 번의 반복 동안 손실이 크게 감소한 후 1,000번째 반복 지점 근처에서 평탄해지기 전에 점차 감소하는 것을 확인할 수 있습니다. 1,000번의 반복 후에는 모델이 수렴되었다고 확신할 수 있습니다.
다음 그림에서는 학습 과정의 세 지점(시작, 중간, 끝)에서 모델을 그립니다. 학습 과정에서 스냅샷의 모델 상태를 시각화하면 가중치와 편향 업데이트, 손실 감소, 모델 수렴 간의 연결이 강화됩니다.
그림에서는 특정 반복에서 파생된 가중치와 편향을 사용하여 모델을 나타냅니다. 데이터 포인트와 모델 스냅샷이 있는 그래프에서 모델에서 데이터 포인트까지의 파란색 손실 선은 손실량을 보여줍니다. 선이 길수록 손실이 많습니다.
다음 그림에서 두 번째 반복이 지나면 손실이 많아 모델이 예측을 잘하지 못함을 알 수 있습니다.
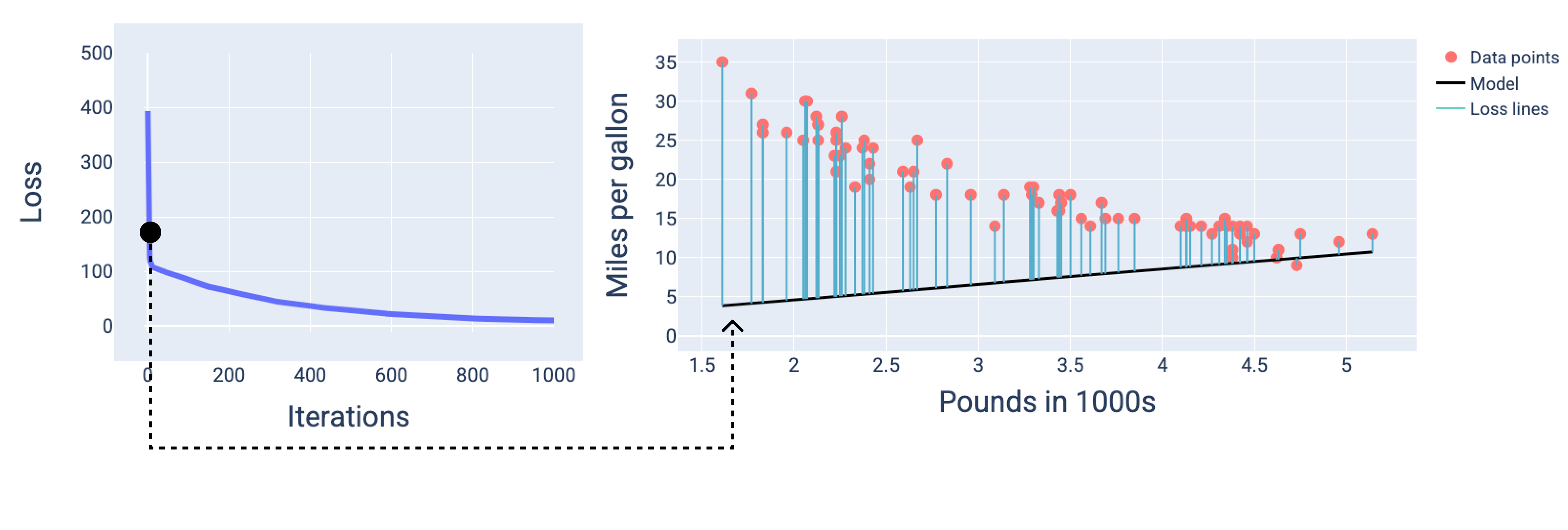
그림 13. 학습 프로세스 시작 시의 손실 곡선과 모델 스냅샷
400번째 반복쯤 되면 경사 하강법이 더 나은 모델을 생성하는 가중치와 편향을 찾은 것을 확인할 수 있습니다.
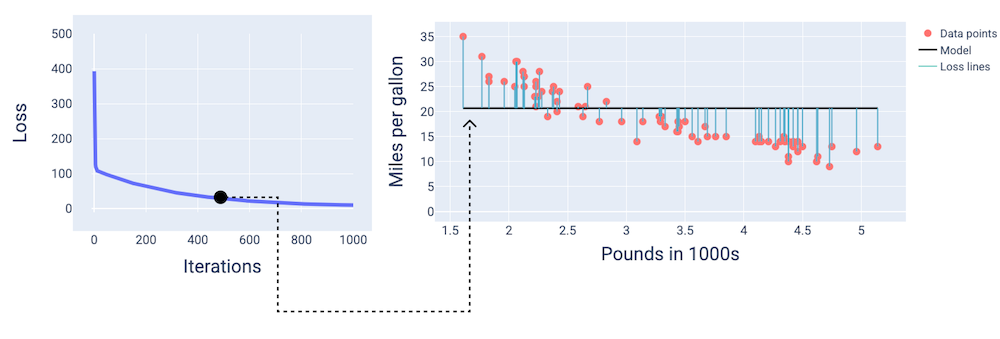
그림 14. 학습 중간 지점의 손실 곡선과 모델 스냅샷
1,000번째 반복 정도에서 모델이 수렴되어 손실이 가장 낮은 모델이 생성된 것을 확인할 수 있습니다.

그림 15. 학습 프로세스 종료 시점의 손실 곡선과 모델 스냅샷
연습: 학습 내용 점검하기
수렴 및 볼록 함수
선형 모델의 손실 함수는 항상 볼록 곡면을 생성합니다. 이 속성으로 인해 선형 회귀 모델이 수렴되면 모델이 손실을 가장 낮게 만드는 가중치와 편향을 찾은 것으로 간주됩니다.
특성이 하나인 모델의 손실 표면을 그래프로 나타내면 볼록한 모양을 확인할 수 있습니다. 다음은 가상의 갤런당 마일 데이터세트의 손실 표면입니다. 가중치는 x축에, 편향은 y축에, 손실은 z축에 있습니다.
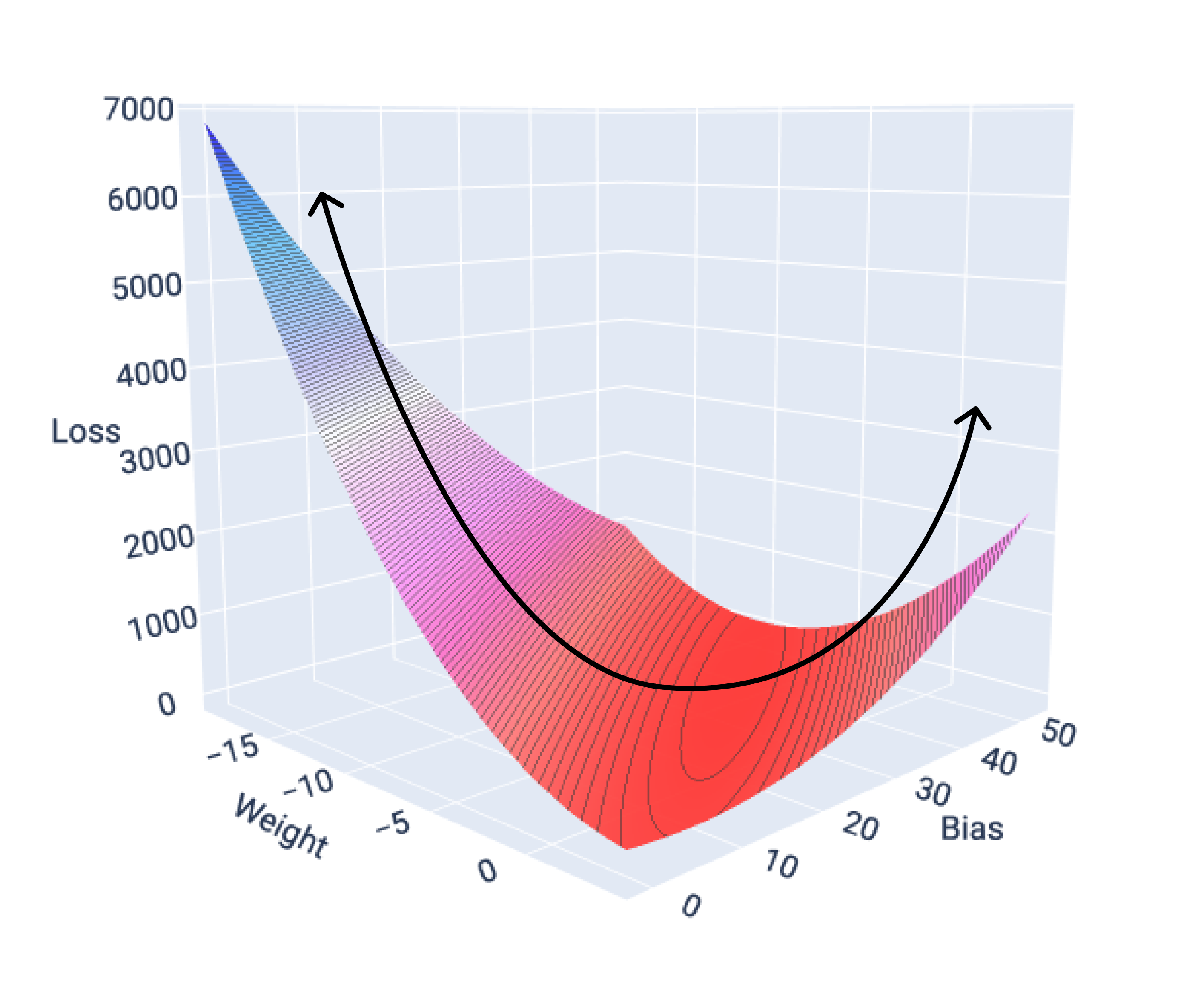
그림 16. 볼록한 모양을 보여주는 손실 곡면
이 예에서 가중치 -5.44와 편향 35.94는 5.54에서 가장 낮은 손실을 생성합니다.
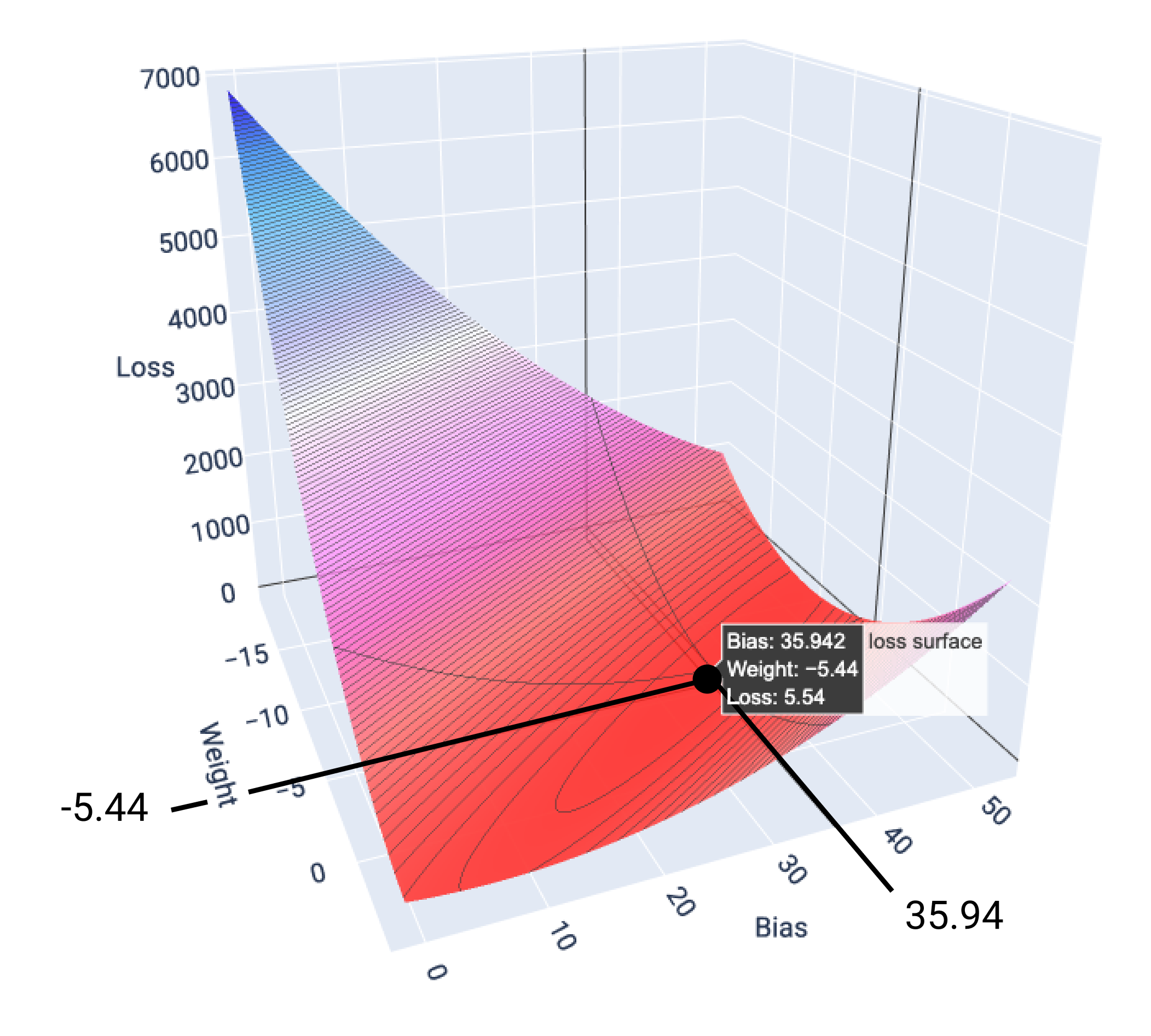
그림 17. 손실이 가장 낮은 가중치 및 편향 값을 보여주는 손실 곡면
선형 모델은 최소 손실이 발견되면 수렴됩니다. 따라서 추가 반복은 경사 하강법이 가중치와 편향 값을 최소값 주변에서 아주 작은 양만큼 이동하도록 할 뿐입니다. 경사 하강법 중에 가중치와 편향점을 그래프로 표시하면 점이 언덕 아래로 굴러가는 공처럼 보이며, 더 이상 아래쪽 경사가 없는 지점에서 멈춥니다.

그림 18. 그래프의 최저점에서 중지되는 경사 하강법 포인트를 보여주는 손실 그래프
검은색 손실 포인트가 손실 곡선의 정확한 모양을 만듭니다. 손실 곡면의 최저점에 도달할 때까지 점진적으로 아래로 기울어지기 전에 급격히 감소합니다.
모델이 각 가중치와 편향의 정확한 최솟값을 찾는 경우는 거의 없으며, 대신 최솟값에 매우 가까운 값을 찾습니다. 가중치와 편향의 최솟값은 손실이 0이 아니라 해당 매개변수의 가장 낮은 손실을 생성하는 값에 해당한다는 점도 유의해야 합니다.
손실이 가장 낮은 가중치와 편향 값(이 경우 가중치 -5.44, 편향 35.94)을 사용하여 모델을 그래프로 표시하여 데이터에 얼마나 잘 맞는지 확인할 수 있습니다.
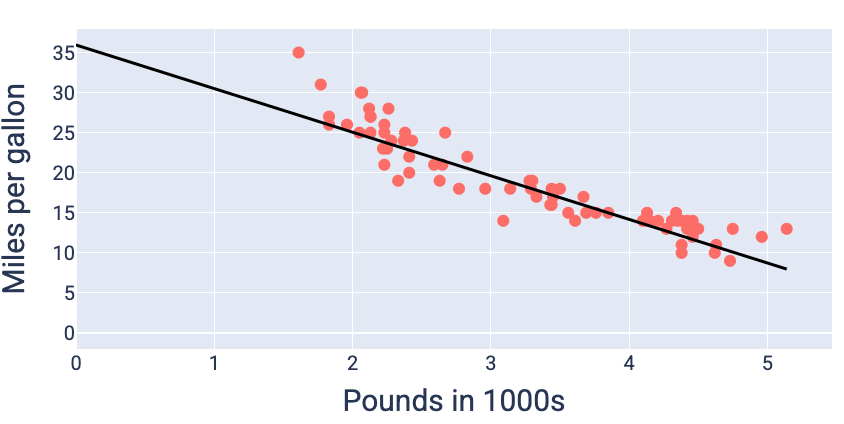
그림 19. 손실이 가장 적은 가중치와 편향 값을 사용하여 그래프로 표시된 모델
다른 가중치와 편향 값으로는 손실이 더 적은 모델을 생성할 수 없으므로 이 데이터 세트에는 이 모델이 가장 적합합니다.