Lineare Regression: Gradientenabstieg
Mit Sammlungen den Überblick behalten
Sie können Inhalte basierend auf Ihren Einstellungen speichern und kategorisieren.
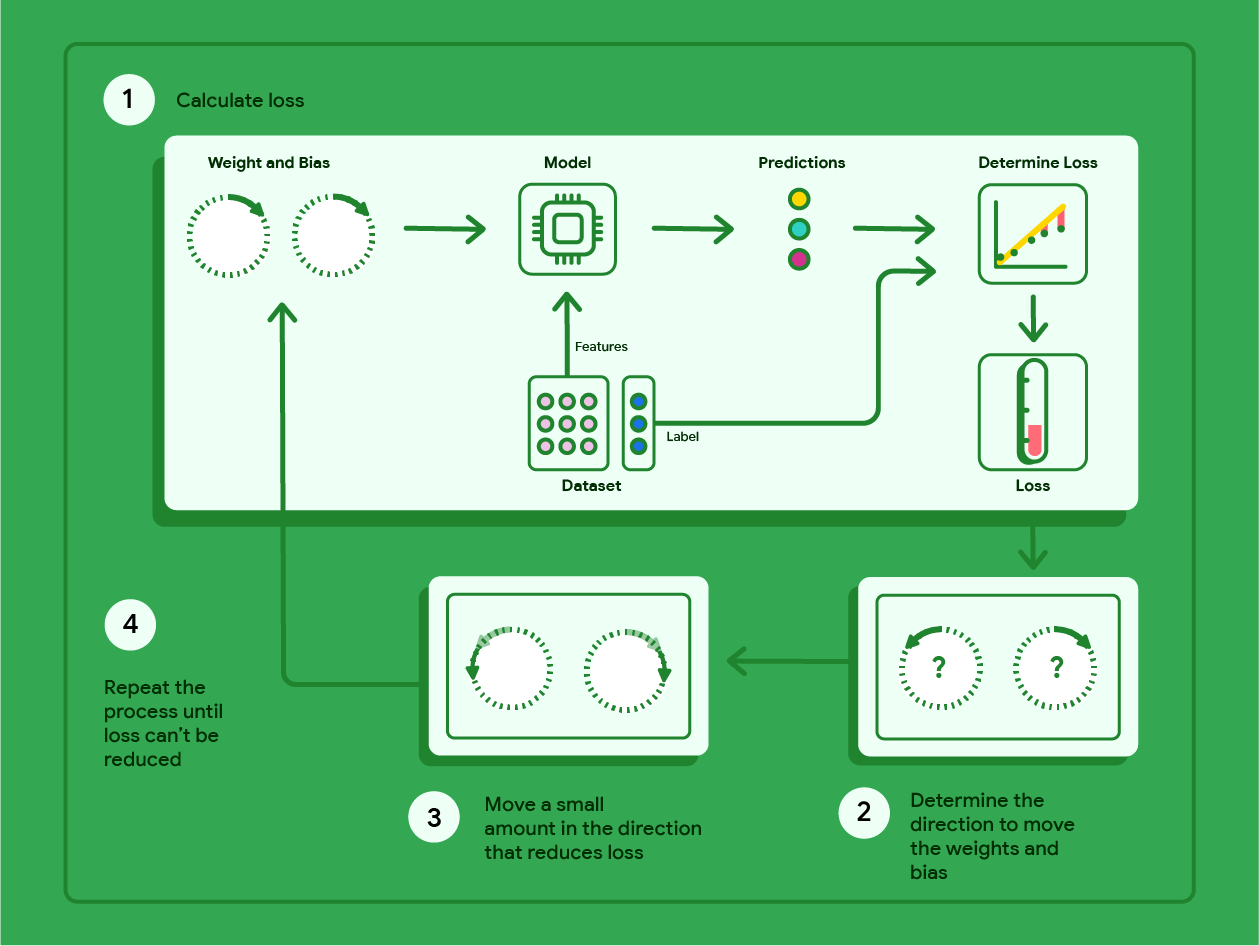
Gradient Descent ist eine mathematische Methode, mit der iterativ die Gewichte und der Bias ermittelt werden, die das Modell mit dem geringsten Verlust erzeugen. Beim Gradientenabstieg werden das optimale Gewicht und der optimale Bias ermittelt, indem der folgende Prozess für eine benutzerdefinierte Anzahl von Iterationen wiederholt wird.
Das Modell wird mit zufälligen Gewichten und Bias-Werten nahe null trainiert und wiederholt dann die folgenden Schritte:
Berechnen Sie den Verlust mit dem aktuellen Gewicht und Bias.
Richtung ermitteln, in die Gewichte und Bias verschoben werden müssen, um den Verlust zu verringern.
Verschieben Sie die Gewichts- und Bias-Werte ein wenig in die Richtung, in der der Verlust geringer wird.
Kehren Sie zu Schritt 1 zurück und wiederholen Sie den Vorgang, bis das Modell den Verlust nicht weiter reduzieren kann.
Das folgende Diagramm zeigt die iterativen Schritte, die beim Gradientenabstieg ausgeführt werden, um die Gewichte und den Bias zu finden, die das Modell mit dem geringsten Verlust erzeugen.
Abbildung 11. Der Gradientenabstieg ist ein iterativer Prozess, bei dem die Gewichte und der Bias ermittelt werden, die das Modell mit dem geringsten Verlust erzeugen.
Klicken Sie auf das Pluszeichen, um mehr über die Mathematik hinter dem Gradientenabstieg zu erfahren.
Konkret können wir die Schritte des Gradientenabstiegs anhand des folgenden kleinen Datasets zur Kraftstoffeffizienz mit sieben Beispielen und mittlerem quadratischen Fehler (MSE) als Verlustmesswert durchgehen:
Pfund in Tausend (Funktion)
Meilen pro Gallone (Label)
3,5
18
3,69
15
3.44
18
3.43
16
4.34
15
4,42
14
2,37
24
Das Modell wird trainiert, indem Gewicht und Bias auf null gesetzt werden:
Klicken Sie auf das Pluszeichen, um mehr über die Berechnung der Steigung zu erfahren.
Um die Steigung der Tangenten an Gewicht und Bias zu ermitteln, leiten wir die Verlustfunktion nach Gewicht und Bias ab und lösen dann die Gleichungen.
Die Gleichung für eine Vorhersage lautet:
$ f_{w,b}(x) = (w*x)+b $.
Wir schreiben den tatsächlichen Wert als „$y$“.
Wir berechnen den mittleren quadratischen Fehler (MSE) mit folgender Formel:
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
Dabei steht $i$ für das $i$-te Trainingsbeispiel und $M$ für die Anzahl der Beispiele.
Gewichtsableitung
Die Ableitung der Verlustfunktion in Bezug auf das Gewicht wird so geschrieben:
$ \frac{\partial }{\partial w} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
und wird so ausgewertet:
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2x_{(i)} $
Zuerst summieren wir jeden vorhergesagten Wert minus den tatsächlichen Wert und multiplizieren das Ergebnis dann mit dem doppelten Feature-Wert.
Anschließend teilen wir die Summe durch die Anzahl der Beispiele.
Das Ergebnis ist die Steigung der Tangente an den Wert des Gewichts.
Wenn wir diese Gleichung mit einem Gewicht und einem Bias von null lösen, erhalten wir -119,7 für die Steigung der Linie.
Bias-Ableitung
Die Ableitung der Verlustfunktion in Bezug auf den Bias wird so geschrieben:
$ \frac{\partial }{\partial b} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
und wird so ausgewertet:
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2 $
Zuerst wird jeder vorhergesagte Wert minus dem tatsächlichen Wert summiert und dann mit 2 multipliziert. Anschließend teilen wir die Summe durch die Anzahl der Beispiele. Das Ergebnis ist die Steigung der Linie, die tangential zum Wert des Bias verläuft.
Wenn wir diese Gleichung mit einem Gewicht und einem Bias von null lösen, erhalten wir -34,3 für die Steigung der Linie.
Bewegen Sie sich ein kleines Stück in Richtung der negativen Steigung, um das nächste Gewicht und den nächsten Bias zu erhalten. Für den Moment definieren wir den „kleinen Betrag“ willkürlich als 0, 01:
Verwenden Sie das neue Gewicht und den neuen Bias, um den Verlust und die Wiederholung zu berechnen. Nach sechs Iterationen erhalten wir die folgenden Gewichte, Bias und Verluste:
Iteration
Gewicht
Bias
Verlust (MSE)
1
0
0
303,71
2
1.20
0,34
170,84
3
2,05
0.59
103.17
4
2,66
0.78
68,70
5
3.09
0,91
51.13
6
3,40
1,01
42.17
Sie sehen, dass der Verlust mit jedem aktualisierten Gewicht und Bias geringer wird.
In diesem Beispiel haben wir nach sechs Iterationen aufgehört. In der Praxis wird ein Modell so lange trainiert, bis es konvergiert.
Wenn ein Modell konvergiert, wird der Verlust durch zusätzliche Iterationen nicht weiter reduziert, da durch den Gradientenabstieg die Gewichte und der Bias gefunden wurden, die den Verlust nahezu minimieren.
Wenn das Modell nach der Konvergenz weiter trainiert wird, beginnt der Verlust, in geringem Maße zu schwanken, da das Modell die Parameter kontinuierlich um ihre niedrigsten Werte herum aktualisiert. Das kann es erschweren, zu überprüfen, ob das Modell tatsächlich konvergiert ist. Um zu bestätigen, dass das Modell konvergiert ist, sollten Sie das Training fortsetzen, bis sich der Verlust stabilisiert hat.
Modellkonvergenz und Verlustkurven
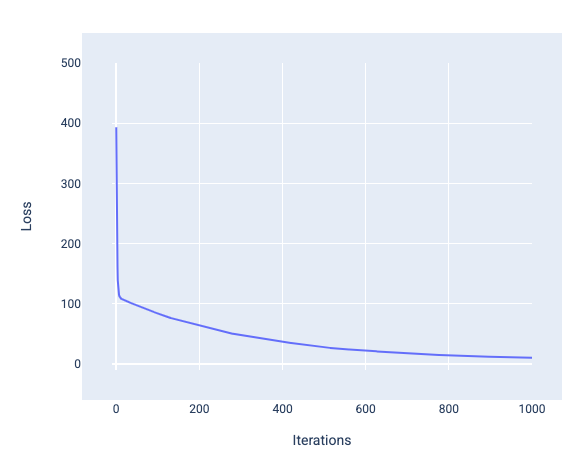
Beim Trainieren eines Modells wird häufig eine Verlustkurve betrachtet, um festzustellen, ob das Modell konvergiert ist. Die Verlustkurve zeigt, wie sich der Verlust während des Trainings des Modells ändert. So sieht eine typische Verlustkurve aus: Der Verlust ist auf der Y-Achse und die Iterationen auf der X-Achse dargestellt:
Abbildung 12. Verlustkurve, die zeigt, dass das Modell um die 1.000. Iteration herum konvergiert.
Sie sehen, dass der Verlust in den ersten Iterationen drastisch abnimmt,dann allmählich sinkt und sich um die 1.000. Iteration herum stabilisiert. Nach 1.000 Iterationen können wir uns ziemlich sicher sein, dass das Modell konvergiert ist.
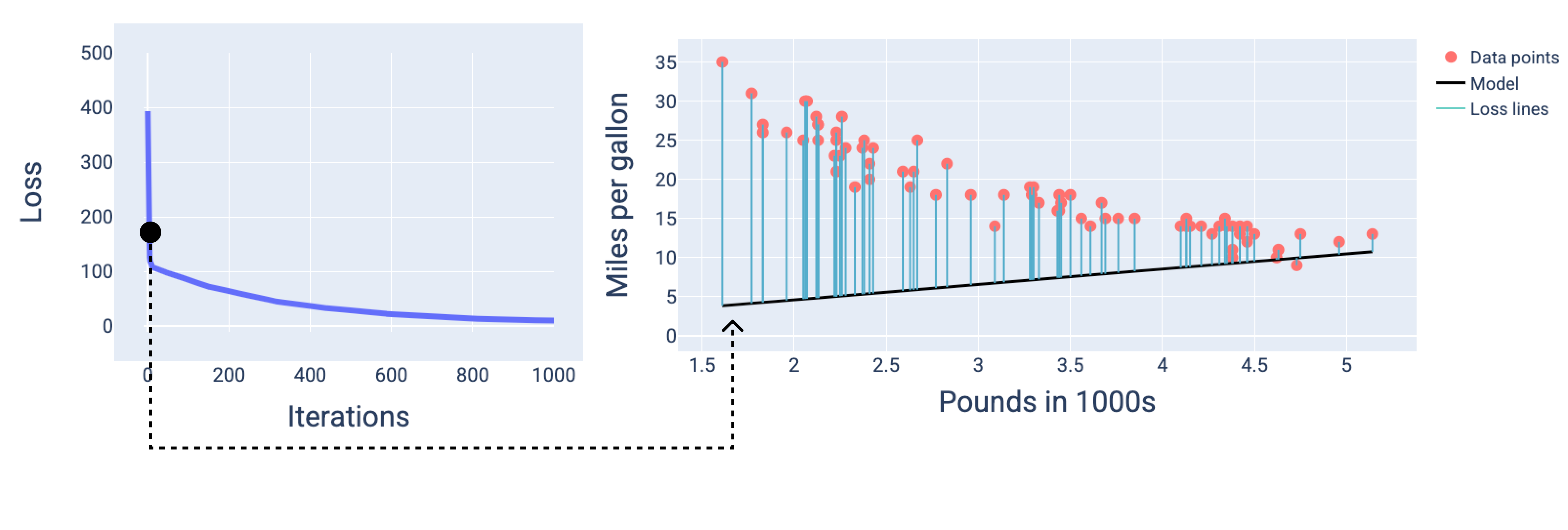
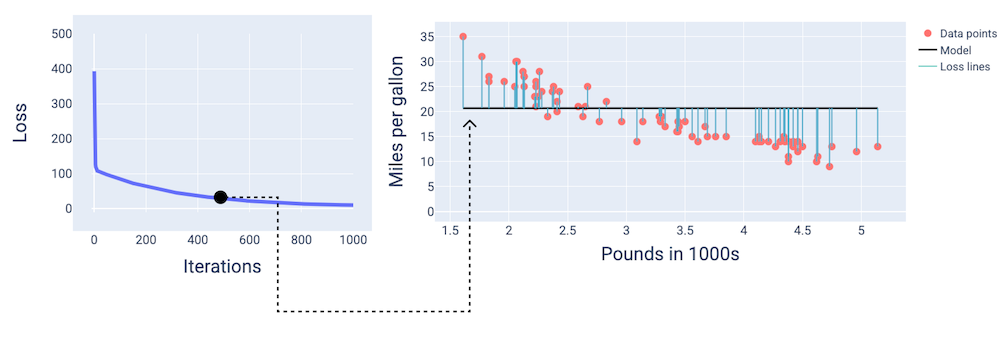
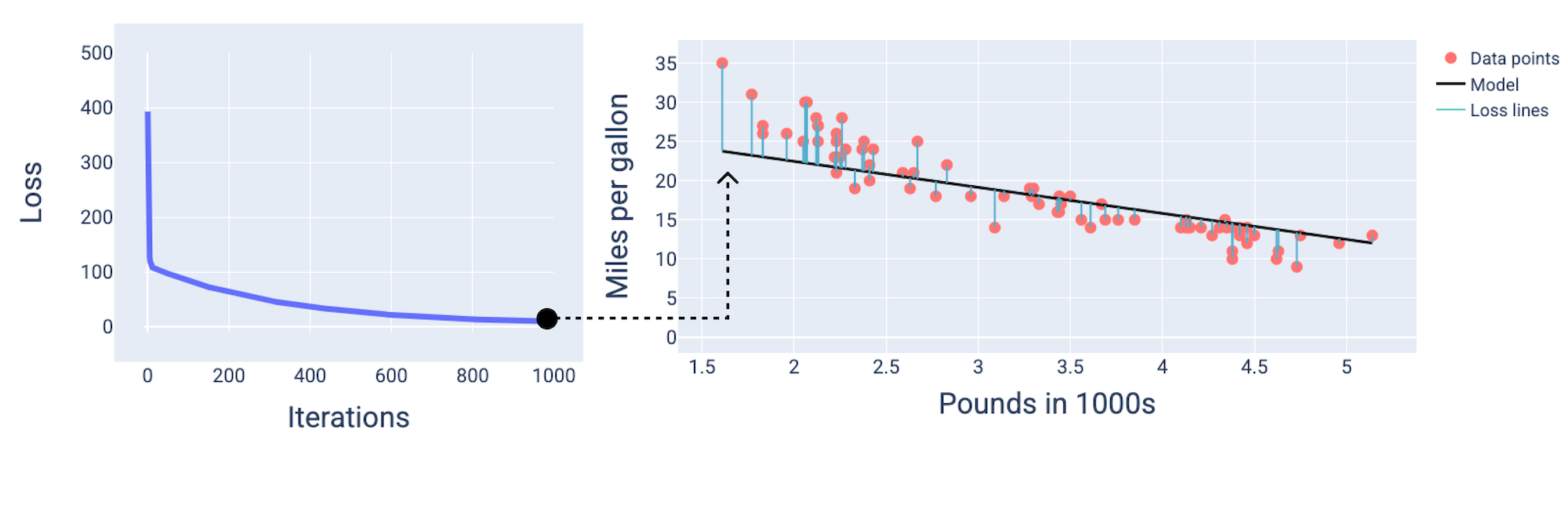
In den folgenden Abbildungen wird das Modell an drei Punkten während des Trainingsprozesses dargestellt: am Anfang, in der Mitte und am Ende. Wenn Sie den Zustand des Modells in Momentaufnahmen während des Trainingsprozesses visualisieren, wird die Verbindung zwischen dem Aktualisieren der Gewichte und des Bias, dem Reduzieren des Verlusts und der Modellkonvergenz verdeutlicht.
In den Abbildungen verwenden wir die abgeleiteten Gewichte und den Bias in einer bestimmten Iteration, um das Modell darzustellen. Im Diagramm mit den Datenpunkten und dem Modell-Snapshot zeigen blaue Verlustlinien vom Modell zu den Datenpunkten den Verlust an. Je länger die Leitungen sind, desto höher ist der Verlust.
In der folgenden Abbildung sehen wir, dass das Modell um die zweite Iteration herum aufgrund des hohen Verlusts keine guten Vorhersagen mehr treffen kann.
Abbildung 13. Verlustkurve und Snapshot des Modells zu Beginn des Trainingsprozesses.
Nach etwa 400 Iterationen hat der Gradientenabstieg das Gewicht und den Bias gefunden, mit denen sich ein besseres Modell erstellen lässt.
Abbildung 14. Verlustkurve und Momentaufnahme des Modells etwa in der Mitte des Trainings.
Nach etwa 1.000 Iteration ist das Modell konvergiert und hat den niedrigstmöglichen Verlust.
Abbildung 15. Verlustkurve und Momentaufnahme des Modells gegen Ende des Trainingsprozesses.
Übung: Wissen testen
Welche Rolle spielt der Gradientenabstieg bei der linearen Regression?
Der Gradientenabstieg ist ein iterativer Prozess, bei dem die besten Gewichte und der beste Bias ermittelt werden, um den Verlust zu minimieren.
Der Gradientenabstieg hilft dabei, den Typ des Verlusts zu bestimmen, der beim Trainieren eines Modells verwendet werden soll, z. B. L1 oder L2.
Der Gradientenabstieg spielt bei der Auswahl einer Verlustfunktion für das Modelltraining keine Rolle.
Beim Gradientenabstieg werden Ausreißer aus dem Dataset entfernt, damit das Modell bessere Vorhersagen treffen kann.
Durch den Gradientenabstieg wird das Dataset nicht geändert.
Konvergenz und konvexe Funktionen
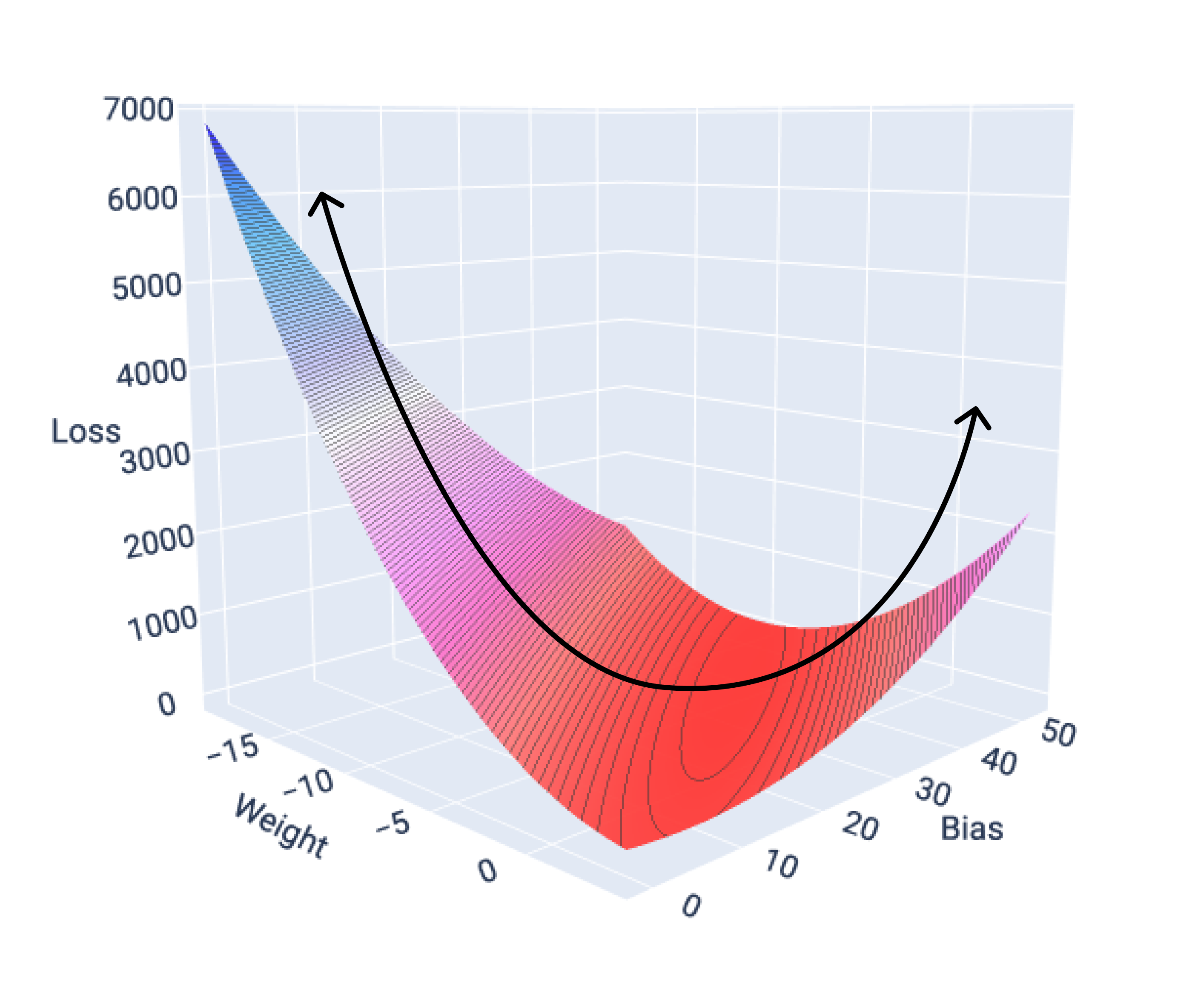
Die Verlustfunktionen für lineare Modelle ergeben immer eine konvexe Oberfläche. Wenn ein lineares Regressionsmodell konvergiert, wissen wir, dass das Modell die Gewichte und den Bias gefunden hat, die den geringsten Verlust erzeugen.
Wenn wir die Verlustoberfläche für ein Modell mit einem Merkmal grafisch darstellen, sehen wir die konvexe Form. Das folgende Diagramm zeigt die Verlustoberfläche für einen hypothetischen Datensatz mit Meilen pro Gallone. Das Gewicht ist auf der x-Achse, der Bias auf der y-Achse und der Verlust auf der z-Achse:
Abbildung 16. Verlustoberfläche mit konvexer Form.
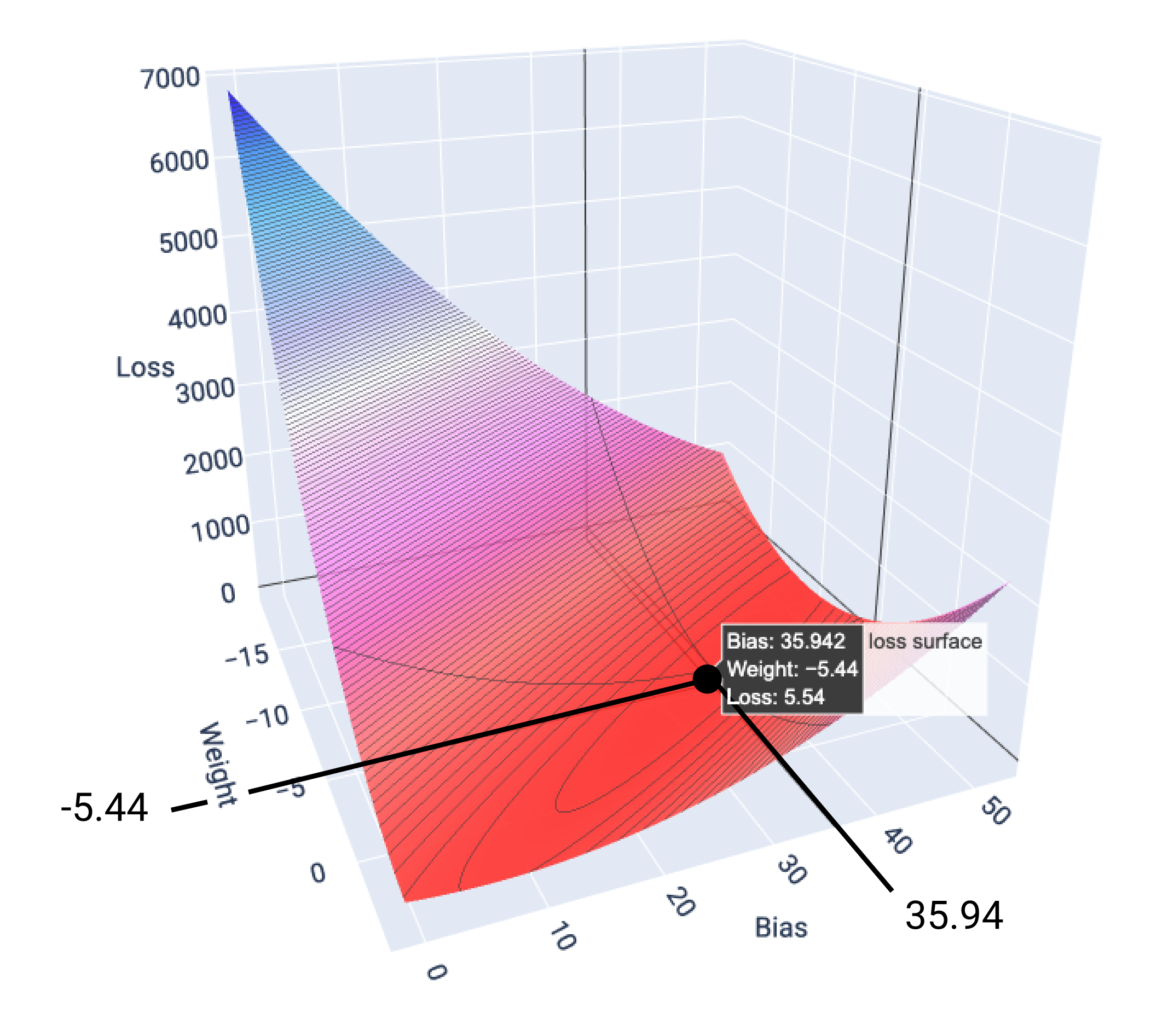
In diesem Beispiel führen ein Gewicht von -5,44 und ein Bias von 35,94 zum niedrigsten Verlust bei 5,54:
Abbildung 17. Verlustoberfläche mit den Gewichts- und Bias-Werten, die den niedrigsten Verlust ergeben.
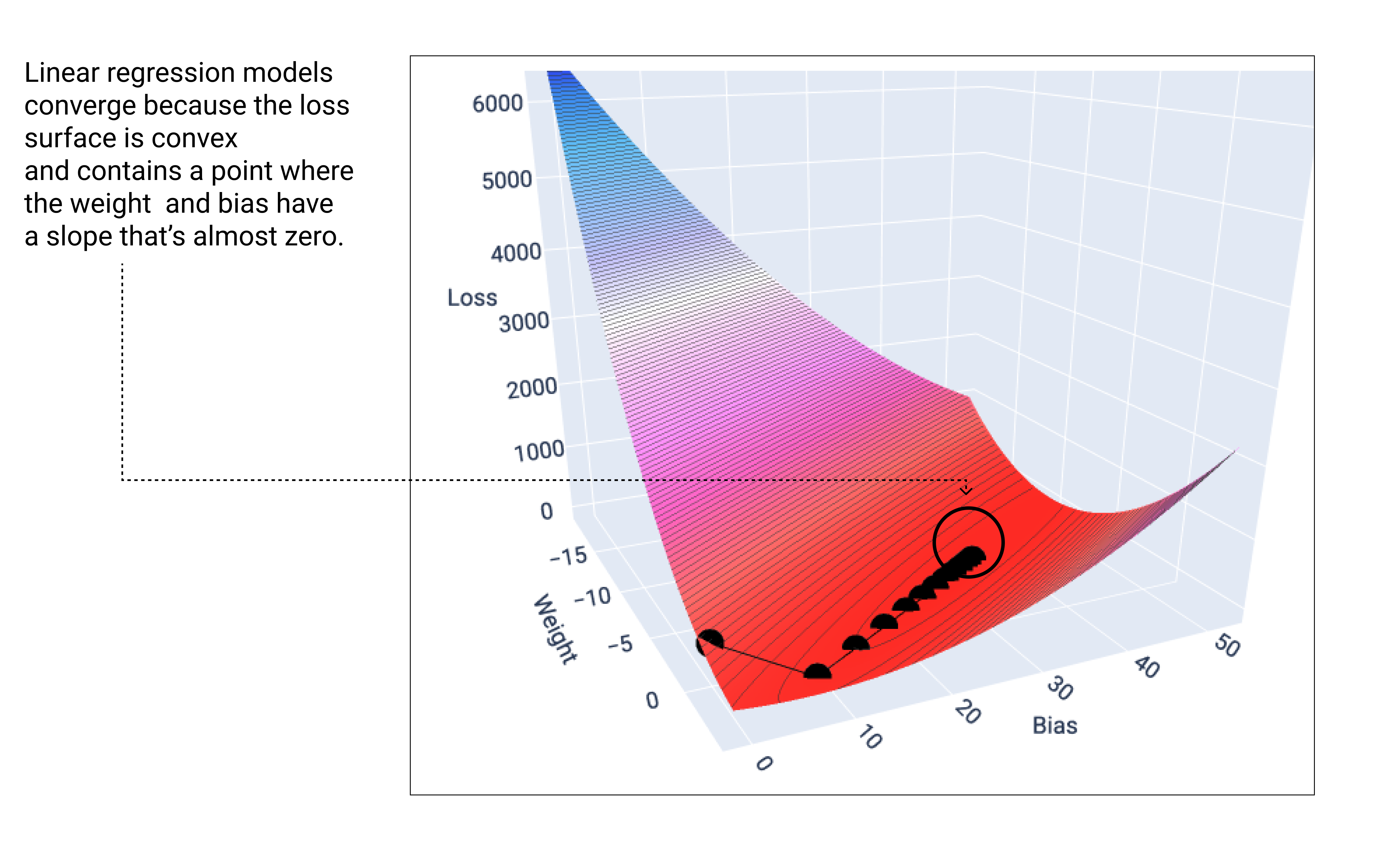
Ein lineares Modell konvergiert, wenn der minimale Verlust erreicht ist. Wenn wir die Gewichte und Bias-Punkte während des Gradientenabstiegs grafisch darstellen, würden die Punkte wie ein Ball aussehen, der einen Hügel hinunterrollt und schließlich an dem Punkt anhält, an dem es keine Abwärtsneigung mehr gibt.
Abbildung 18. Verlustdiagramm mit Punkten für den Gradientenabstieg, die am niedrigsten Punkt des Diagramms enden.
Die schwarzen Verlustpunkte bilden die genaue Form der Verlustkurve: ein steiler Abfall, bevor sie allmählich abfällt, bis sie den niedrigsten Punkt auf der Verlustoberfläche erreicht hat.
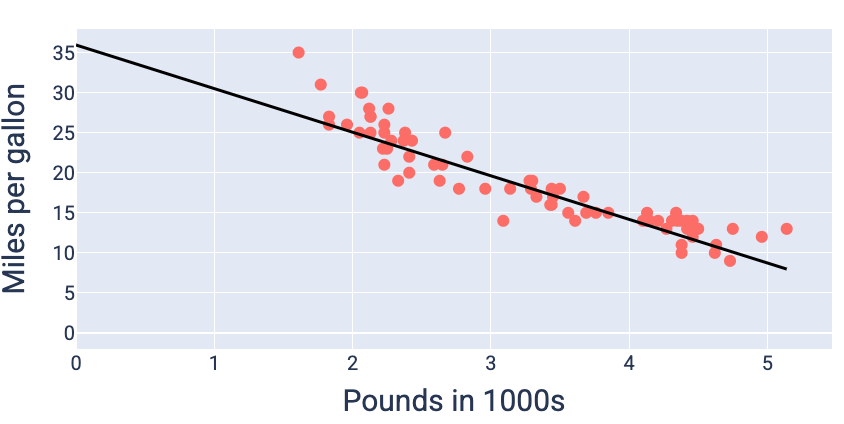
Mithilfe der Gewichts- und Bias-Werte, die den geringsten Verlust ergeben (in diesem Fall ein Gewicht von -5,44 und ein Bias von 35,94), können wir das Modell grafisch darstellen, um zu sehen, wie gut es zu den Daten passt:
Abbildung 19. Modell, das mit den Gewichtungs- und Bias-Werten dargestellt wird, die den niedrigsten Verlust ergeben.
Dies ist das beste Modell für diesen Datensatz, da keine anderen Gewichts- und Bias-Werte ein Modell mit geringerem Verlust ergeben.