المعلَمات الفائقة هي متغيرات تتحكّم في جوانب مختلفة من التدريب. في ما يلي ثلاث معلَمات فائقة شائعة:
في المقابل، المَعلمات هي المتغيّرات، مثل الأوزان والانحياز، التي تشكّل جزءًا من النموذج نفسه. بعبارة أخرى، مُدخلات الضبط هي قيم يمكنك التحكّم فيها، بينما المعلمات هي قيم يحتسبها النموذج أثناء التدريب.
معدّل التعلّم
معدّل التعلّم هو عدد ذو فاصلة عشرية تحدّده ويؤثر في سرعة تقارب النموذج. إذا كان معدّل التعلّم منخفضًا جدًا، قد يستغرق النموذج وقتًا طويلاً للوصول إلى النتيجة المطلوبة. ومع ذلك، إذا كان معدّل التعلّم مرتفعًا جدًا، لن يتقارب النموذج أبدًا، بل سيتأرجح بين القيم التي تقلّل الخسارة. والهدف هو اختيار معدّل تعلّم ليس مرتفعًا جدًا ولا منخفضًا جدًا، وذلك لكي يتقارب النموذج بسرعة.
يحدّد معدّل التعلّم حجم التغييرات التي يجب إجراؤها على الأوزان والانحياز خلال كل خطوة من خطوات عملية "النزول التدريجي". يضرب النموذج التدرّج بمعدّل التعلّم لتحديد مَعلمات النموذج (قيم الوزن والانحياز) للتكرار التالي. في الخطوة الثالثة من النزول التدريجي، يشير "المبلغ الصغير" الذي يجب الانتقال إليه في اتجاه الميل السالب إلى معدل التعلّم.
ويكون الفرق بين مَعلمات النموذج القديم ومَعلمات النموذج الجديد متناسبًا مع ميل دالة الخسارة. على سبيل المثال، إذا كان الانحدار كبيرًا، يتخذ النموذج خطوة كبيرة. وإذا كان صغيرًا، فسيتم اتخاذ خطوة صغيرة. على سبيل المثال، إذا كانت قيمة التدرّج 2.5 ومعدّل التعلّم 0.01، سيغيّر النموذج المَعلمة بمقدار 0.025.
يساعد معدّل التعلّم المثالي النموذج على التقارب خلال عدد معقول من التكرارات. في الشكل 20، يوضّح منحنى الخسارة أنّ النموذج يتحسّن بشكل كبير خلال أول 20 تكرارًا قبل أن يبدأ في التقارب:
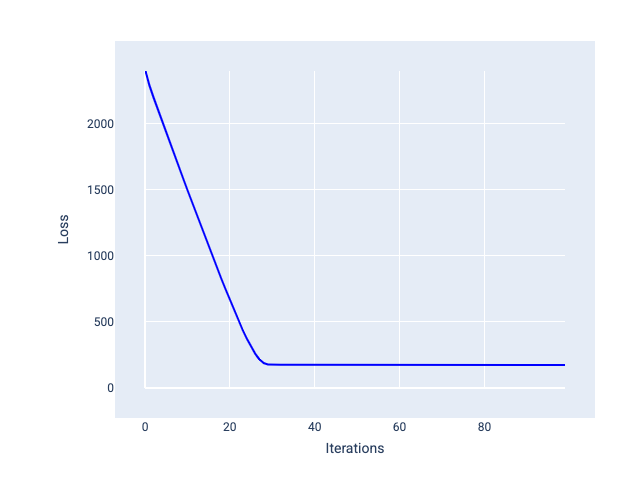
الشكل 20 رسم بياني للخسارة يعرض نموذجًا تم تدريبه بمعدّل تعلّم يتقارب بسرعة.
في المقابل، قد يستغرق معدّل التعلّم الصغير جدًا عددًا كبيرًا جدًا من التكرارات للوصول إلى النتيجة المطلوبة. في الشكل 21، يوضّح منحنى الخسارة أنّ النموذج يحقّق تحسينات طفيفة فقط بعد كل تكرار:
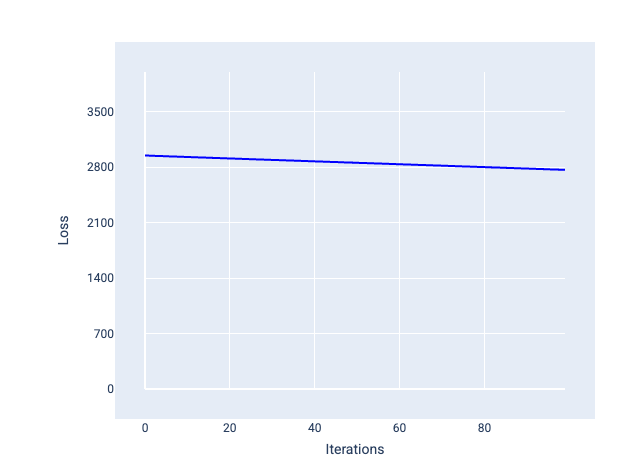
الشكل 21 رسم بياني للخسارة يعرض نموذجًا تم تدريبه بمعدّل تعلّم منخفض
لا يمكن أبدًا أن يتقارب معدّل التعلّم الكبير جدًا لأنّ كل تكرار إما يتسبّب في تذبذب الخسارة أو زيادتها باستمرار. في الشكل 22، يوضّح منحنى الخسارة أنّ النموذج يقلّل الخسارة ثم يزيدها بعد كل تكرار، وفي الشكل 23، تزداد الخسارة في التكرارات اللاحقة:
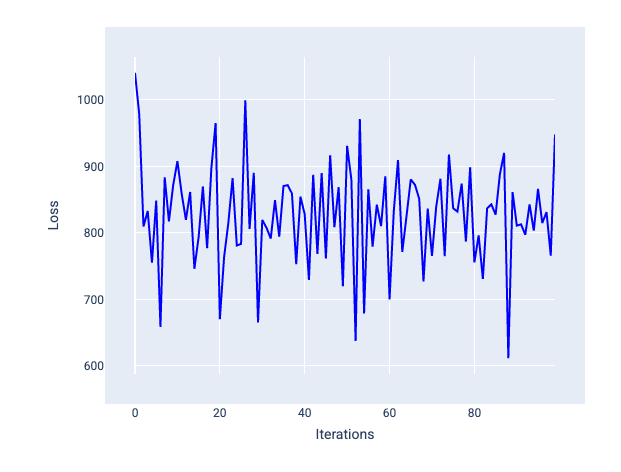
الشكل 22 رسم بياني للخسارة يعرض نموذجًا تم تدريبه بمعدل تعلّم كبير جدًا، حيث يتذبذب منحنى الخسارة بشكل كبير، ويرتفع وينخفض مع زيادة عدد التكرارات.
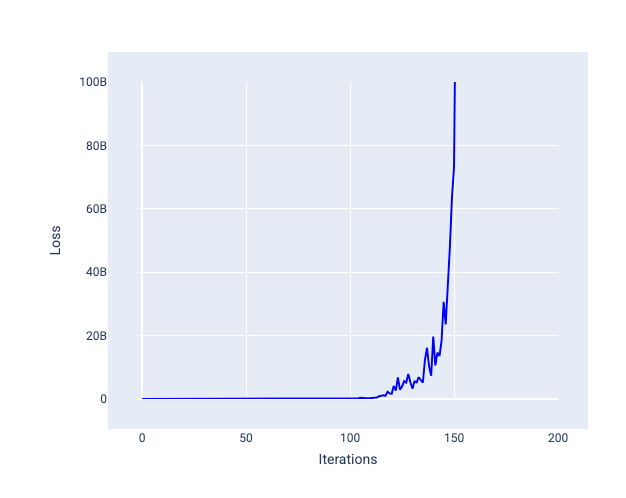
الشكل 23 رسم بياني للخسارة يعرض نموذجًا تم تدريبه بمعدّل تعلّم كبير جدًا، حيث يزداد منحنى الخسارة بشكل كبير في التكرارات اللاحقة.
تمرين: التحقّق من فهمك
حجم الدفعة
حجم الدُفعة هو وسيط فائق يشير إلى عدد الأمثلة التي يعالجها النموذج قبل تعديل الأوزان والانحياز. قد تعتقد أنّ النموذج يجب أن يحسب الخسارة لكل مثال في مجموعة البيانات قبل تعديل الأوزان والانحياز. ومع ذلك، عندما تحتوي مجموعة البيانات على مئات الآلاف أو حتى الملايين من الأمثلة، لا يكون استخدام الدفعة الكاملة عمليًا.
هناك أسلوبان شائعان للحصول على التدرّج الصحيح المتوسط بدون الحاجة إلى فحص كل مثال في مجموعة البيانات قبل تعديل الأوزان والانحياز، وهما التدرّج الهبوطي العشوائي والتدرّج الهبوطي العشوائي المصغّر:
النزول المتدرّج العشوائي (SGD): لا يستخدم النزول المتدرّج العشوائي سوى مثال واحد (حجم الدفعة هو واحد) لكل تكرار. مع توفّر عدد كافٍ من التكرارات، تعمل طريقة SGD ولكنها تتضمّن الكثير من الضوضاء. يشير مصطلح "التشويش" إلى التغيّرات التي تحدث أثناء التدريب وتؤدي إلى زيادة الخسارة بدلاً من انخفاضها خلال عملية التكرار. يشير مصطلح "عشوائي" إلى أنّه يتم اختيار المثال الواحد الذي يتضمّنه كل دفعة بشكل عشوائي.
لاحظ في الصورة التالية كيف يتأرجح معدّل الخطأ قليلاً أثناء تعديل النموذج للأوزان والانحياز باستخدام SGD، ما قد يؤدي إلى حدوث تشويش في الرسم البياني لمعدّل الخطأ:
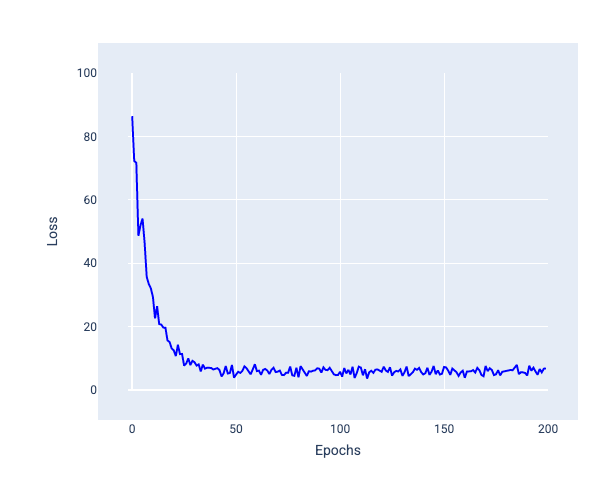
الشكل 24 نموذج تم تدريبه باستخدام خوارزمية النزول المتدرّج العشوائي (SGD) يعرض تشويشًا في منحنى الخسارة.
يُرجى العِلم أنّ استخدام طريقة "النزول التدريجي العشوائي" يمكن أن يؤدي إلى حدوث تشويش في منحنى الخسارة بأكمله، وليس فقط بالقرب من نقطة التقارب.
النزول المتدرّج العشوائي ضمن دفعة صغيرة: يشكّل النزول المتدرّج العشوائي ضمن دفعة صغيرة حلاً وسطًا بين النزول المتدرّج العشوائي الكامل والنزول المتدرّج العشوائي. بالنسبة إلى عدد $ N $ من نقاط البيانات، يمكن أن يكون حجم الدفعة أي عدد أكبر من 1 وأقل من $ N $. يختار النموذج الأمثلة المضمّنة في كل دفعة بشكل عشوائي، ويحسب متوسطات تدرّجاتها، ثم يعدّل الأوزان والانحياز مرة واحدة لكل تكرار.
يعتمد تحديد عدد الأمثلة لكل مجموعة على مجموعة البيانات وموارد الحوسبة المتاحة. بشكل عام، تتصرف أحجام الدُفعات الصغيرة مثل SGD، وتتصرف أحجام الدُفعات الأكبر مثل الانحدار التدريجي الكامل للدُفعات.
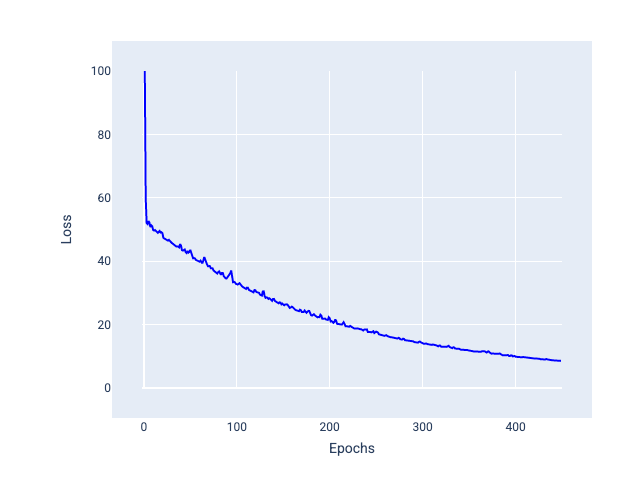
الشكل 25 نموذج تم تدريبه باستخدام نزول متدرّج عشوائي ضمن دفعة صغيرة
عند تدريب نموذج، قد تعتقد أنّ الضوضاء هي سمة غير مرغوب فيها يجب التخلص منها. ومع ذلك، يمكن أن يكون بعض الضوضاء أمرًا جيدًا. في الوحدات اللاحقة، ستتعرّف على كيف يمكن أن تساعد الضوضاء النموذج في التعميم بشكل أفضل والعثور على الأوزان والانحياز الأمثل في شبكة عصبية.
Epochs
أثناء التدريب، يشير العصر إلى أنّ النموذج قد عالج كل مثال في مجموعة التدريب مرة واحدة. على سبيل المثال، إذا كانت مجموعة التدريب تتضمّن 1,000 مثال وكان حجم الدفعة الصغيرة 100 مثال، سيستغرق النموذج 10 تكرارات لإكمال حقبة واحدة.
يتطلّب التدريب عادةً العديد من الحِقب. أي أنّ النظام يحتاج إلى معالجة كل مثال في مجموعة التدريب عدة مرات.
عدد الدورات التدريبية هو معلَمة فائقة تحدّدها قبل أن يبدأ النموذج في التدريب. في كثير من الحالات، عليك تجربة عدد الفترات اللازمة لتقارب النموذج. بشكل عام، يؤدي استخدام المزيد من الحِقب إلى إنشاء نموذج أفضل، ولكن يستغرق تدريبه وقتًا أطول.
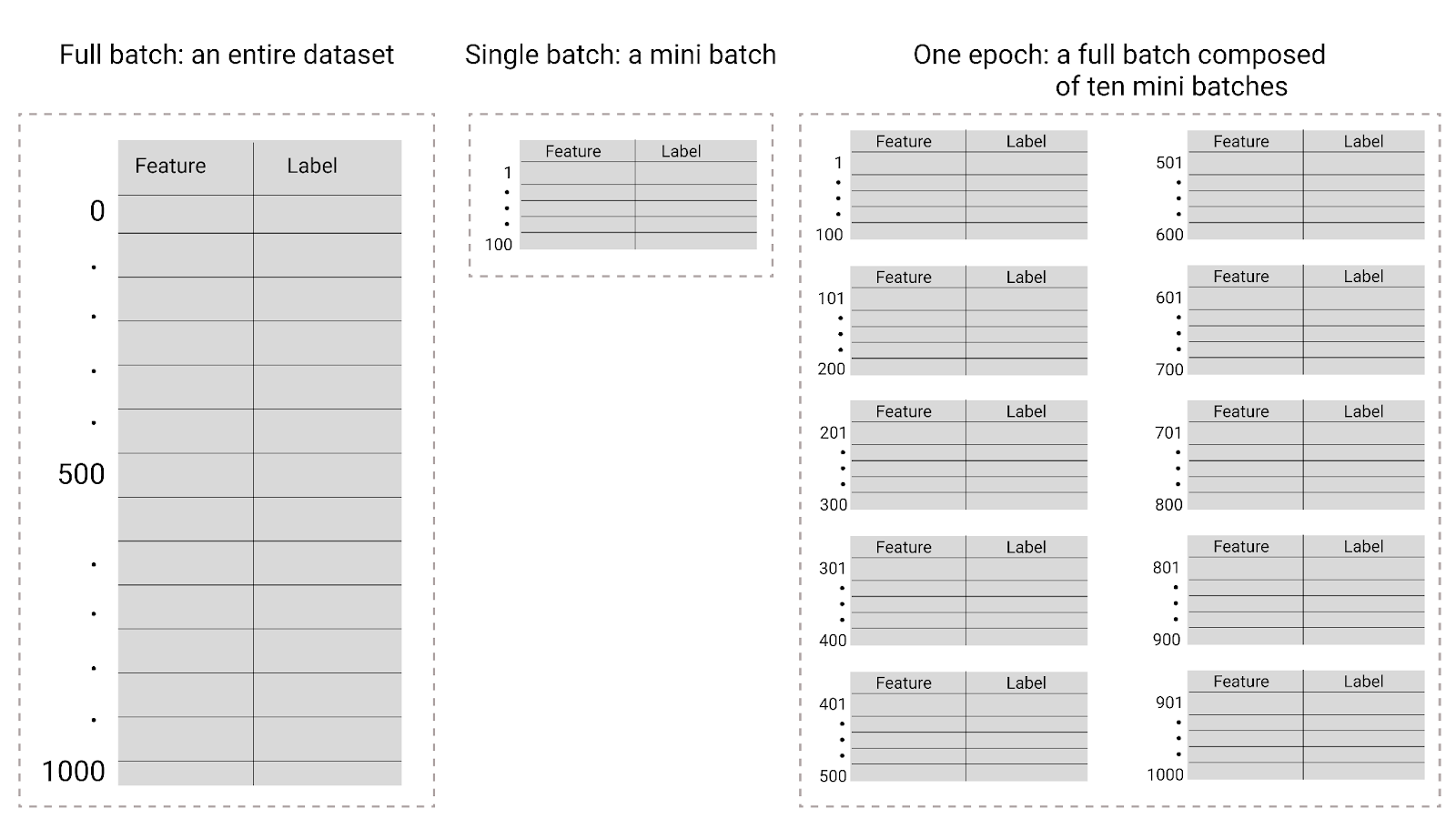
الشكل 26 الدفعة الكاملة مقابل الدفعة الصغيرة
يوضّح الجدول التالي العلاقة بين حجم الدفعة وعدد الدورات التدريبية وعدد المرات التي يعدّل فيها النموذج مَعلماته.
| نوع الدفعة | عندما يتم تعديل الأوزان والانحيازات |
|---|---|
| دفعة كاملة | بعد أن يطّلع النموذج على جميع الأمثلة في مجموعة البيانات على سبيل المثال، إذا كانت مجموعة البيانات تحتوي على 1,000 مثال وتم تدريب النموذج على 20 حقبة، سيعدّل النموذج الأوزان والانحياز 20 مرة، مرة واحدة لكل حقبة. |
| النزول المتدرج العشوائي | بعد أن يطّلع النموذج على مثال واحد من مجموعة البيانات على سبيل المثال، إذا كانت مجموعة البيانات تحتوي على 1,000 مثال وتم التدريب لمدة 20 حقبة، سيعدّل النموذج الأوزان والانحياز 20,000 مرة. |
| نزول متدرّج عشوائي ضمن دفعة صغيرة | بعد أن يطّلع النموذج على الأمثلة في كل دفعة. على سبيل المثال، إذا كانت مجموعة البيانات تحتوي على 1,000 مثال، وكان حجم الدفعة 100، وتم تدريب النموذج لمدة 20 حقبة، سيعدّل النموذج الأوزان والانحياز 200 مرة. |