Hyperparameter adalah variabel yang mengontrol berbagai aspek pelatihan. Tiga hyperparameter umum adalah:
Sebaliknya, parameter adalah variabel, seperti bobot dan bias, yang merupakan bagian dari model itu sendiri. Dengan kata lain, hyperparameter adalah nilai yang Anda kontrol; parameter adalah nilai yang dihitung model selama pelatihan.
Kecepatan pembelajaran
Kecepatan pembelajaran adalah angka floating point yang Anda tetapkan dan memengaruhi seberapa cepat model berkonvergensi. Jika kecepatan pembelajaran terlalu rendah, model dapat memerlukan waktu yang lama untuk melakukan konvergensi. Namun, jika kecepatan pembelajaran terlalu tinggi, model tidak akan pernah melakukan konvergensi, tetapi akan berfluktuasi di sekitar bobot dan bias yang meminimalkan kerugian. Tujuannya adalah memilih kecepatan pembelajaran yang tidak terlalu tinggi maupun terlalu rendah agar model menyatu dengan cepat.
Kecepatan pembelajaran menentukan besarnya perubahan yang harus dilakukan pada bobot dan bias selama setiap langkah proses penurunan gradien. Model mengalikan gradien dengan kecepatan pembelajaran untuk menentukan parameter model (nilai bobot dan bias) untuk iterasi berikutnya. Pada langkah ketiga penurunan gradien, "jumlah kecil" yang harus dipindahkan ke arah kemiringan negatif mengacu pada kecepatan pemelajaran.
Perbedaan antara parameter model lama dan parameter model baru sebanding dengan kemiringan fungsi kerugian. Misalnya, jika kemiringannya besar, model akan mengambil langkah besar. Jika kecil, ia akan mengambil langkah kecil. Misalnya, jika magnitudo gradien adalah 2,5 dan kecepatan pembelajaran adalah 0,01, model akan mengubah parameter sebesar 0,025.
Learning rate yang ideal membantu model menyatu dalam jumlah iterasi yang wajar. Pada Gambar 20, kurva kerugian menunjukkan peningkatan signifikan pada model selama 20 iterasi pertama sebelum mulai menyatu:
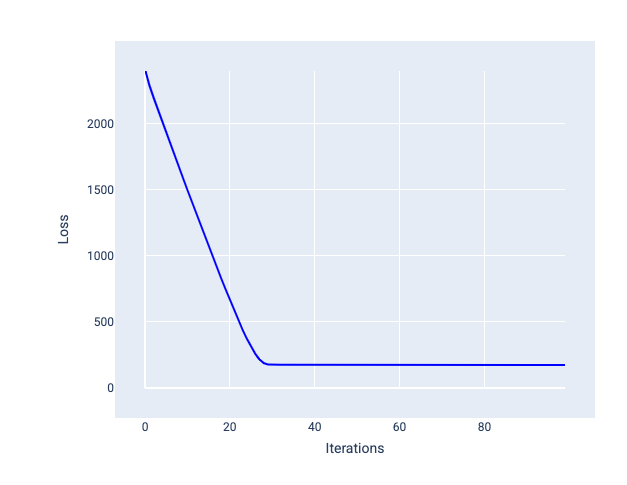
Gambar 20. Grafik kerugian yang menunjukkan model yang dilatih dengan laju pembelajaran yang berkonvergensi dengan cepat.
Sebaliknya, kecepatan pembelajaran yang terlalu kecil dapat memerlukan terlalu banyak iterasi untuk berkonvergensi. Pada Gambar 21, kurva kerugian menunjukkan bahwa model hanya mengalami peningkatan kecil setelah setiap iterasi:
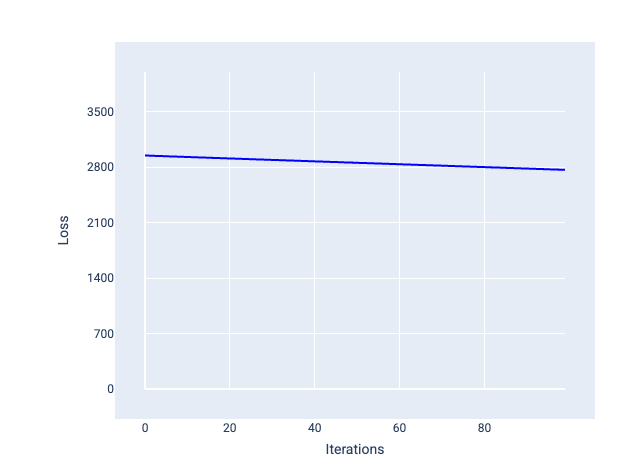
Gambar 21. Grafik kerugian yang menunjukkan model yang dilatih dengan kecepatan pembelajaran kecil.
Kecepatan pemelajaran yang terlalu besar tidak akan pernah menyatu karena setiap iterasi menyebabkan kerugian berfluktuasi atau terus meningkat. Pada Gambar 22, kurva kerugian menunjukkan penurunan, lalu peningkatan kerugian model setelah setiap iterasi, dan pada Gambar 23, kerugian meningkat pada iterasi berikutnya:
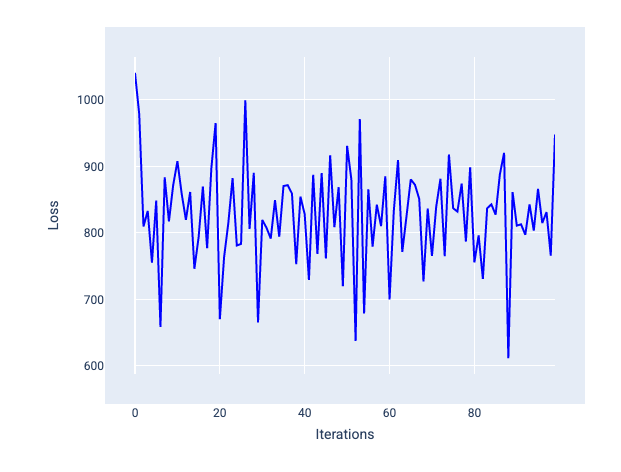
Gambar 22. Grafik kerugian yang menunjukkan model yang dilatih dengan laju pembelajaran yang terlalu besar, di mana kurva kerugian berfluktuasi secara liar, naik dan turun seiring bertambahnya iterasi.
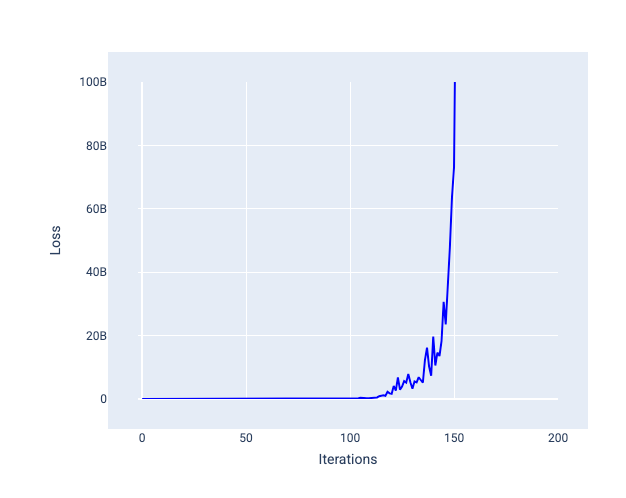
Gambar 23. Grafik kerugian yang menunjukkan model yang dilatih dengan laju pembelajaran yang terlalu besar, dengan kurva kerugian yang meningkat secara drastis pada iterasi berikutnya.
Latihan: Periksa pemahaman Anda
Ukuran batch
Ukuran batch adalah hyperparameter yang mengacu pada jumlah contoh yang diproses model sebelum memperbarui bobot dan biasnya. Anda mungkin berpikir bahwa model harus menghitung kerugian untuk setiap contoh dalam set data sebelum memperbarui bobot dan bias. Namun, jika set data berisi ratusan ribu atau bahkan jutaan contoh, penggunaan batch penuh tidak praktis.
Dua teknik umum untuk mendapatkan gradien yang tepat pada rata-rata tanpa perlu melihat setiap contoh dalam set data sebelum memperbarui bobot dan bias adalah stochastic gradient descent dan mini-batch stochastic gradient descent:
Penurunan gradien stokastik (SGD): Penurunan gradien stokastik hanya menggunakan satu contoh (ukuran tumpukan satu) per iterasi. Dengan iterasi yang cukup, SGD berfungsi, tetapi sangat berisik. "Derau" mengacu pada variasi selama pelatihan yang menyebabkan kerugian meningkat, bukan menurun selama iterasi. Istilah "stokastik" menunjukkan bahwa satu contoh yang terdiri dari setiap batch dipilih secara acak.
Perhatikan pada gambar berikut bagaimana kerugian sedikit berfluktuasi saat model memperbarui bobot dan biasnya menggunakan SGD, yang dapat menyebabkan derau dalam grafik kerugian:
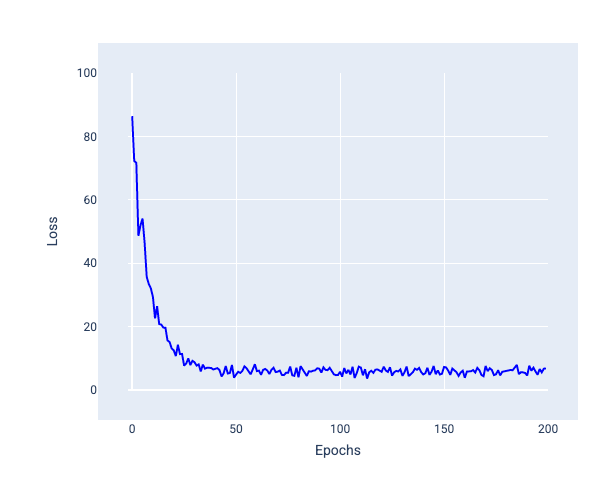
Gambar 24. Model yang dilatih dengan penurunan gradien stokastik (SGD) yang menunjukkan derau dalam kurva kerugian.
Perhatikan bahwa penggunaan penurunan gradien stokastik dapat menghasilkan derau di seluruh kurva kerugian, bukan hanya di dekat konvergensi.
Penurunan gradien stokastik tumpukan mini (mini-batch SGD): Penurunan gradien stokastik tumpukan mini adalah kompromi antara penurunan gradien stokastik tumpukan penuh dan SGD. Untuk jumlah titik data $ N $, ukuran batch dapat berupa angka apa pun yang lebih besar dari 1 dan kurang dari $ N $. Model memilih contoh yang disertakan dalam setiap batch secara acak, menghitung rata-rata gradiennya, lalu memperbarui bobot dan bias satu kali per iterasi.
Menentukan jumlah contoh untuk setiap batch bergantung pada set data dan sumber daya komputasi yang tersedia. Secara umum, ukuran batch kecil berperilaku seperti SGD, dan ukuran batch yang lebih besar berperilaku seperti penurunan gradien batch penuh.
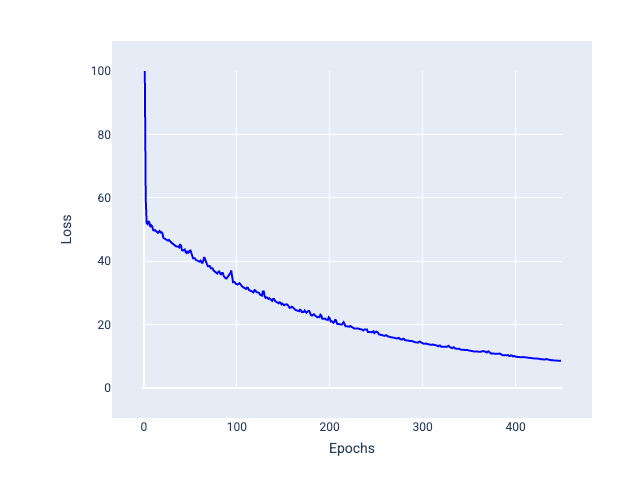
Gambar 25. Model dilatih dengan SGD tumpukan mini.
Saat melatih model, Anda mungkin berpikir bahwa derau adalah karakteristik yang tidak diinginkan dan harus dihilangkan. Namun, sejumlah derau dapat bermanfaat. Di modul selanjutnya, Anda akan mempelajari cara noise dapat membantu model melakukan generalisasi dengan lebih baik dan menemukan bobot dan bias yang optimal dalam jaringan neural.
Epoch
Selama pelatihan, epoch berarti model telah memproses setiap contoh dalam set pelatihan satu kali. Misalnya, dengan set pelatihan yang berisi 1.000 contoh dan ukuran mini-batch 100 contoh, model akan memerlukan 10 iterasi untuk menyelesaikan satu epoch.
Pelatihan biasanya memerlukan banyak epoch. Artinya, sistem perlu memproses setiap contoh dalam set pelatihan beberapa kali.
Jumlah iterasi pelatihan adalah hyperparameter yang Anda tetapkan sebelum model mulai pelatihan. Dalam banyak kasus, Anda perlu bereksperimen dengan jumlah epoch yang diperlukan agar model dapat melakukan konvergensi. Secara umum, makin banyak epoch akan menghasilkan model yang lebih baik, tetapi juga memerlukan waktu pelatihan yang lebih lama.
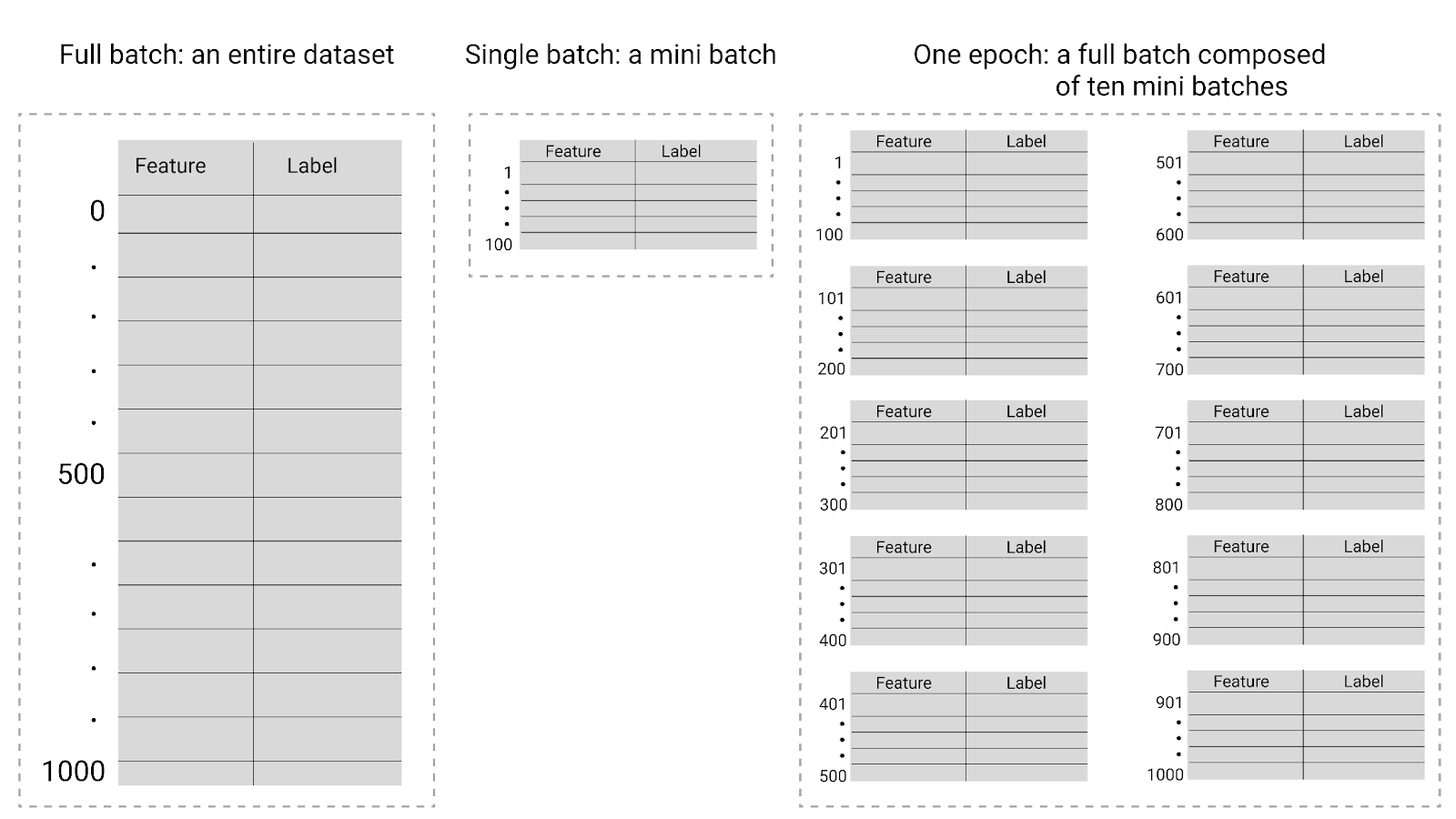
Gambar 26. Batch penuh versus batch mini.
Tabel berikut menjelaskan hubungan antara ukuran batch dan epoch dengan jumlah waktu model memperbarui parameternya.
| Jenis batch | Saat pembaruan bobot dan bias terjadi |
|---|---|
| Batch lengkap | Setelah model melihat semua contoh dalam set data. Misalnya, jika set data berisi 1.000 contoh dan model dilatih selama 20 epoch, model akan memperbarui bobot dan bias 20 kali, sekali per epoch. |
| Penurunan gradien stokastik | Setelah model melihat satu contoh dari set data. Misalnya, jika set data berisi 1.000 contoh dan dilatih selama 20 epoch, model akan memperbarui bobot dan bias sebanyak 20.000 kali. |
| Penurunan gradien stokastik tumpukan mini | Setelah model melihat contoh di setiap batch. Misalnya, jika set data berisi 1.000 contoh, dan ukuran batch adalah 100, dan model dilatih selama 20 epoch, model akan memperbarui bobot dan bias sebanyak 200 kali. |