হাইপারপ্যারামিটার হল ভেরিয়েবল যা প্রশিক্ষণের বিভিন্ন দিক নিয়ন্ত্রণ করে। তিনটি সাধারণ হাইপারপ্যারামিটার হল:
বিপরীতে, প্যারামিটারগুলি হল ভেরিয়েবল, যেমন ওজন এবং পক্ষপাত, যা মডেলেরই অংশ। অন্য কথায়, হাইপারপ্যারামিটার হল এমন মান যা আপনি নিয়ন্ত্রণ করেন; প্যারামিটার হল সেই মান যা মডেল প্রশিক্ষণের সময় গণনা করে।
শেখার হার
শেখার হার হল আপনার সেট করা একটি ফ্লোটিং পয়েন্ট নম্বর যা মডেলটি কত দ্রুত একত্রিত হয় তা প্রভাবিত করে। শেখার হার খুব কম হলে, মডেলটি একত্রিত হতে দীর্ঘ সময় নিতে পারে। যাইহোক, যদি শেখার হার খুব বেশি হয়, মডেলটি কখনই একত্রিত হয় না, বরং ওজন এবং পক্ষপাতের চারপাশে বাউন্স করে যা ক্ষতি কমিয়ে দেয়। লক্ষ্য হল একটি শেখার হার বাছাই করা যা খুব বেশি বা খুব কম নয় যাতে মডেলটি দ্রুত একত্রিত হয়।
শেখার হার গ্রেডিয়েন্ট ডিসেন্ট প্রক্রিয়ার প্রতিটি ধাপে ওজন এবং পক্ষপাতের পরিবর্তনের মাত্রা নির্ধারণ করে। মডেলটি পরবর্তী পুনরাবৃত্তির জন্য মডেলের প্যারামিটার (ওজন এবং পক্ষপাতের মান) নির্ধারণ করতে শেখার হার দ্বারা গ্রেডিয়েন্টকে গুণ করে। গ্রেডিয়েন্ট ডিসেন্টের তৃতীয় ধাপে, নেতিবাচক ঢালের দিকে যাওয়ার জন্য "ছোট পরিমাণ" শেখার হারকে বোঝায়।
পুরানো মডেলের পরামিতি এবং নতুন মডেলের পরামিতিগুলির মধ্যে পার্থক্যটি ক্ষতি ফাংশনের ঢালের সমানুপাতিক। উদাহরণস্বরূপ, যদি ঢাল বড় হয়, মডেলটি একটি বড় পদক্ষেপ নেয়। ছোট হলে, এটি একটি ছোট পদক্ষেপ নেয়। উদাহরণস্বরূপ, যদি গ্রেডিয়েন্টের মাত্রা 2.5 হয় এবং শেখার হার 0.01 হয়, তাহলে মডেলটি 0.025 দ্বারা পরামিতি পরিবর্তন করবে।
আদর্শ শিক্ষার হার মডেলটিকে যুক্তিসঙ্গত সংখ্যক পুনরাবৃত্তির মধ্যে একত্রিত হতে সাহায্য করে। চিত্র 20-এ, ক্ষতির বক্ররেখা দেখায় যে মডেলটি একত্রিত হতে শুরু করার আগে প্রথম 20টি পুনরাবৃত্তির সময় উল্লেখযোগ্যভাবে উন্নতি করছে:
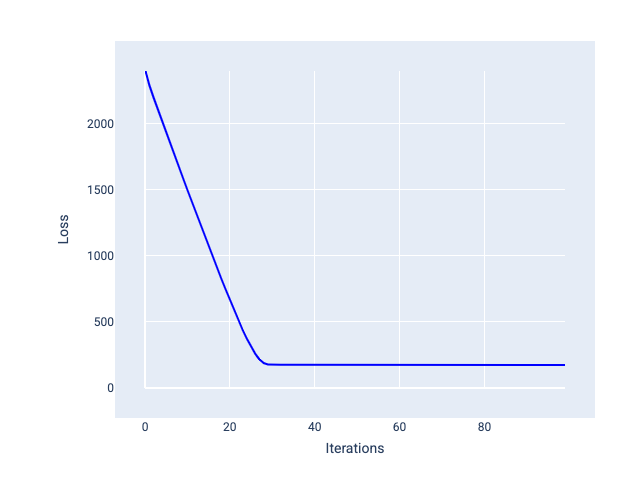
চিত্র 20 । ক্ষতির গ্রাফ একটি শেখার হার সহ প্রশিক্ষিত একটি মডেল দেখাচ্ছে যা দ্রুত একত্রিত হয়।
বিপরীতে, একটি শেখার হার যা খুব কম তা একত্রিত হতে অনেকগুলি পুনরাবৃত্তি নিতে পারে। চিত্র 21-এ, ক্ষতির বক্ররেখা দেখায় যে মডেলটি প্রতিটি পুনরাবৃত্তির পরে শুধুমাত্র ছোটখাটো উন্নতি করে:
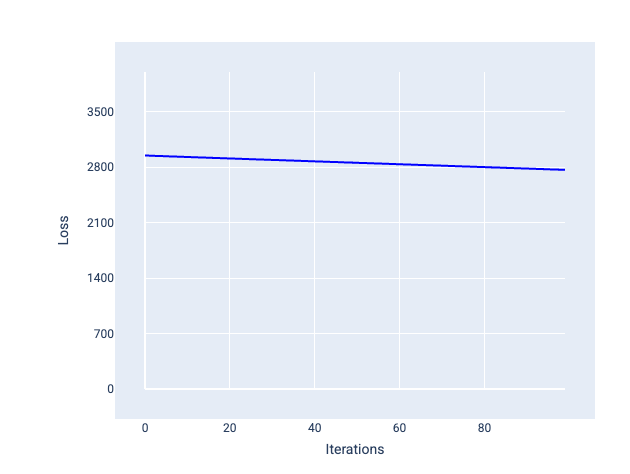
চিত্র 21 । একটি ছোট শেখার হার সহ প্রশিক্ষিত একটি মডেল দেখানো ক্ষতির গ্রাফ।
একটি শেখার হার যেটি খুব বেশি তা কখনই একত্রিত হয় না কারণ প্রতিটি পুনরাবৃত্তি হয় ক্ষতির চারপাশে বাউন্স করে বা ক্রমাগত বৃদ্ধি পায়। চিত্র 22-এ, ক্ষতির বক্ররেখা দেখায় যে মডেলটি হ্রাস পাচ্ছে এবং তারপরে প্রতিটি পুনরাবৃত্তির পরে ক্ষতি বাড়ছে, এবং চিত্র 23-এ পরবর্তী পুনরাবৃত্তিতে ক্ষতি বাড়ে:
চিত্র 22 । ক্ষতির গ্রাফটি খুব বড় একটি শেখার হার সহ প্রশিক্ষিত একটি মডেল দেখায়, যেখানে ক্ষতির বক্ররেখা অত্যধিক ওঠানামা করে, পুনরাবৃত্তি বৃদ্ধির সাথে সাথে উপরে এবং নিচে যায়।
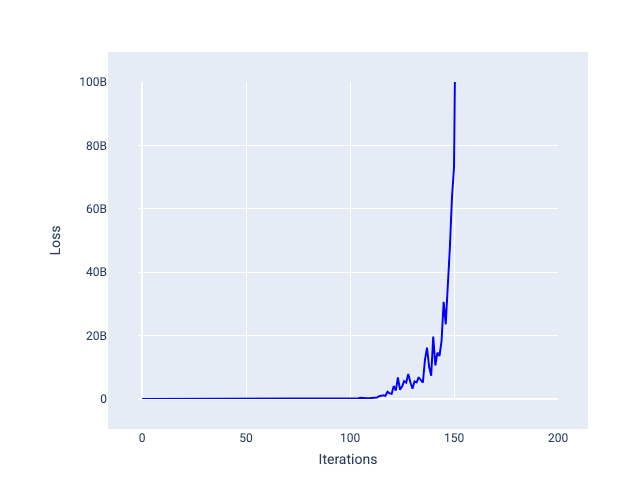
চিত্র 23 । ক্ষতির গ্রাফ একটি শেখার হারের সাথে প্রশিক্ষিত একটি মডেল দেখাচ্ছে যা খুব বড়, যেখানে ক্ষতির বক্ররেখা পরবর্তী পুনরাবৃত্তিতে ব্যাপকভাবে বৃদ্ধি পায়।
অনুশীলন: আপনার বোঝার পরীক্ষা করুন
ব্যাচের আকার
ব্যাচের আকার হল একটি হাইপারপ্যারামিটার যা মডেলটি তার ওজন এবং পক্ষপাত আপডেট করার আগে প্রসেস করে এমন উদাহরণের সংখ্যা নির্দেশ করে। আপনি ভাবতে পারেন যে মডেলটির ওজন এবং পক্ষপাত আপডেট করার আগে ডেটাসেটের প্রতিটি উদাহরণের জন্য ক্ষতি গণনা করা উচিত। যাইহোক, যখন একটি ডেটাসেটে কয়েক হাজার বা এমনকি লক্ষ লক্ষ উদাহরণ থাকে, তখন সম্পূর্ণ ব্যাচ ব্যবহার করা ব্যবহারিক হয় না।
ওজন এবং পক্ষপাত আপডেট করার আগে ডেটাসেটের প্রতিটি উদাহরণ না দেখে গড়ে সঠিক গ্রেডিয়েন্ট পেতে দুটি সাধারণ কৌশল হল স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট এবং মিনি-ব্যাচ স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট :
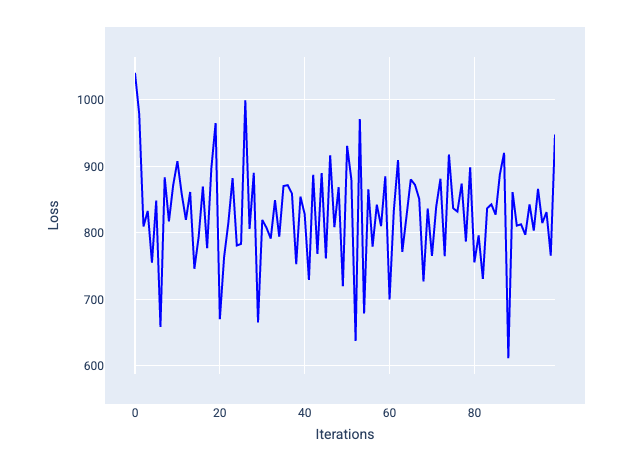
স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট (SGD) : স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট প্রতি পুনরাবৃত্তিতে শুধুমাত্র একটি একক উদাহরণ (একটির ব্যাচের আকার) ব্যবহার করে। পর্যাপ্ত পুনরাবৃত্তি দেওয়া, SGD কাজ করে কিন্তু খুব কোলাহলপূর্ণ। "গোলমাল" বলতে প্রশিক্ষণের সময় পরিবর্তনগুলি বোঝায় যা পুনরাবৃত্তির সময় হ্রাসের পরিবর্তে ক্ষতি বৃদ্ধি করে। "স্টোকাস্টিক" শব্দটি নির্দেশ করে যে প্রতিটি ব্যাচ সমন্বিত একটি উদাহরণ এলোমেলোভাবে বেছে নেওয়া হয়েছে।
নিম্নলিখিত চিত্রটিতে লক্ষ্য করুন যে মডেলটি SGD ব্যবহার করে তার ওজন এবং পক্ষপাত আপডেট করার সাথে সাথে ক্ষতি কিছুটা ওঠানামা করে, যা ক্ষতির গ্রাফে গোলমাল হতে পারে:
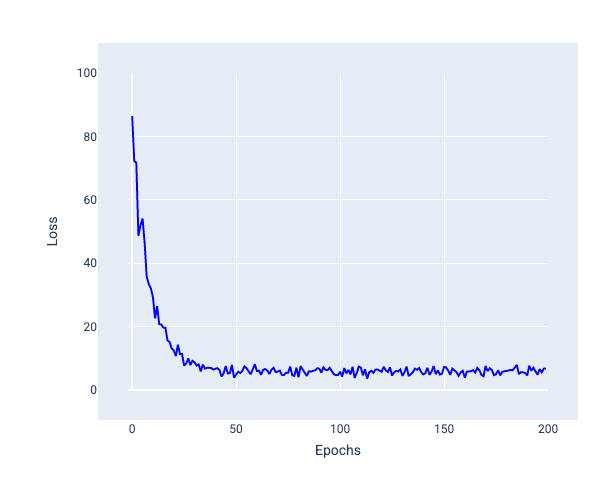
চিত্র 24 । স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট (SGD) সহ প্রশিক্ষিত মডেল ক্ষতির বক্ররেখায় শব্দ দেখাচ্ছে।
মনে রাখবেন যে স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট ব্যবহার করলে পুরো ক্ষতি বক্ররেখা জুড়ে শব্দ উৎপন্ন হতে পারে, শুধু অভিসারের কাছাকাছি নয়।
মিনি-ব্যাচ স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট (মিনি-ব্যাচ SGD) : মিনি-ব্যাচ স্টকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট হল ফুল-ব্যাচ এবং SGD এর মধ্যে একটি আপস। $N$ সংখ্যক ডেটা পয়েন্টের জন্য, ব্যাচের আকার 1-এর বেশি এবং $N$-এর চেয়ে কম যেকোনো সংখ্যা হতে পারে। মডেলটি এলোমেলোভাবে প্রতিটি ব্যাচে অন্তর্ভুক্ত উদাহরণগুলি বেছে নেয়, তাদের গ্রেডিয়েন্টের গড় করে এবং তারপর প্রতি পুনরাবৃত্তিতে একবার ওজন এবং পক্ষপাত আপডেট করে।
প্রতিটি ব্যাচের উদাহরণের সংখ্যা নির্ধারণ করা ডেটাসেট এবং উপলব্ধ গণনা সংস্থানগুলির উপর নির্ভর করে। সাধারণভাবে, ছোট ব্যাচের আকারগুলি SGD-এর মতো আচরণ করে এবং বড় ব্যাচের আকারগুলি সম্পূর্ণ-ব্যাচ গ্রেডিয়েন্ট ডিসেন্টের মতো আচরণ করে।
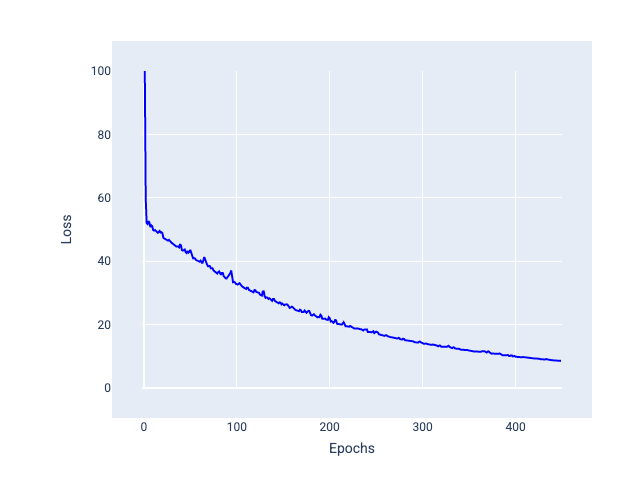
চিত্র 25 । মিনি-ব্যাচ SGD সহ প্রশিক্ষিত মডেল।
একটি মডেলকে প্রশিক্ষণ দেওয়ার সময়, আপনি মনে করতে পারেন যে গোলমাল একটি অবাঞ্ছিত বৈশিষ্ট্য যা বাদ দেওয়া উচিত। যাইহোক, একটি নির্দিষ্ট পরিমাণ শব্দ একটি ভাল জিনিস হতে পারে। পরবর্তী মডিউলগুলিতে, আপনি শিখবেন কীভাবে শব্দ একটি মডেলকে আরও ভালোভাবে সাধারণীকরণ করতে এবং একটি নিউরাল নেটওয়ার্কে সর্বোত্তম ওজন এবং পক্ষপাত খুঁজে পেতে সাহায্য করতে পারে।
যুগ
প্রশিক্ষণের সময়, একটি যুগ মানে যে মডেলটি প্রশিক্ষণ সেটের প্রতিটি উদাহরণ একবার প্রক্রিয়া করেছে। উদাহরণস্বরূপ, 1,000টি উদাহরণ সহ একটি প্রশিক্ষণ সেট এবং 100টি উদাহরণের একটি মিনি-ব্যাচ আকার দেওয়া হলে, এটি একটি যুগ সম্পূর্ণ করতে মডেলটি 10 টি পুনরাবৃত্তি করবে৷
প্রশিক্ষণের জন্য সাধারণত অনেক যুগের প্রয়োজন হয়। অর্থাৎ, সিস্টেমটিকে প্রশিক্ষণের প্রতিটি উদাহরণ একাধিকবার প্রক্রিয়া করতে হবে।
যুগের সংখ্যা হল একটি হাইপারপ্যারামিটার যা আপনি মডেলটি প্রশিক্ষণ শুরু করার আগে সেট করেন। অনেক ক্ষেত্রে, মডেলটিকে একত্রিত হতে কতগুলি যুগ লাগে তা নিয়ে আপনাকে পরীক্ষা করতে হবে। সাধারণভাবে, আরও বেশি যুগ একটি ভাল মডেল তৈরি করে, তবে প্রশিক্ষণের জন্য আরও সময় নেয়।
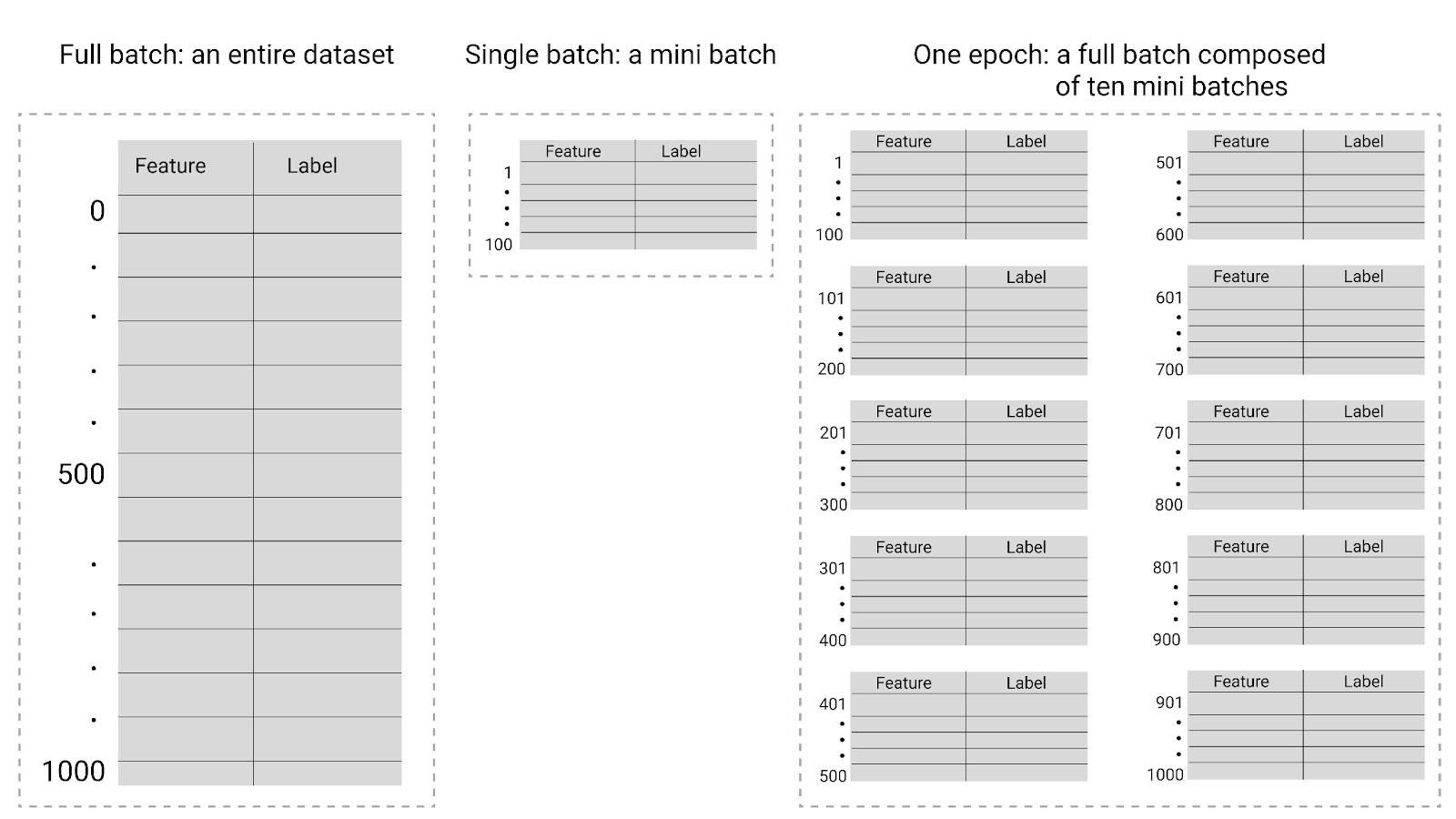
চিত্র 26 । সম্পূর্ণ ব্যাচ বনাম মিনি ব্যাচ।
নিম্নলিখিত সারণীটি বর্ণনা করে যে কিভাবে ব্যাচের আকার এবং যুগগুলি একটি মডেল তার পরামিতিগুলিকে কতবার আপডেট করে তার সাথে সম্পর্কিত।
| ব্যাচ টাইপ | যখন ওজন এবং পক্ষপাত আপডেট হয় |
|---|---|
| সম্পূর্ণ ব্যাচ | মডেলটি ডেটাসেটের সমস্ত উদাহরণ দেখার পরে। উদাহরণস্বরূপ, যদি একটি ডেটাসেটে 1,000টি উদাহরণ থাকে এবং মডেলটি 20টি যুগের জন্য ট্রেন করে, মডেলটি প্রতি যুগে একবার ওজন এবং পক্ষপাত 20 বার আপডেট করে। |
| স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট | মডেল ডেটাসেট থেকে একটি একক উদাহরণ দেখায় পরে. উদাহরণস্বরূপ, যদি একটি ডেটাসেটে 20টি যুগের জন্য 1,000টি উদাহরণ এবং ট্রেন থাকে, মডেলটি 20,000 বার ওজন এবং পক্ষপাত আপডেট করে। |
| মিনি-ব্যাচ স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট | মডেল প্রতিটি ব্যাচে উদাহরণ দেখায় পরে. উদাহরণস্বরূপ, যদি একটি ডেটাসেটে 1,000টি উদাহরণ থাকে এবং ব্যাচের আকার 100টি হয় এবং মডেলটি 20টি যুগের জন্য ট্রেন করে, মডেলটি ওজন এবং পক্ষপাত 200 বার আপডেট করে। |