초매개변수는 학습의 다양한 측면을 제어하는 변수입니다. 일반적인 세 가지 하이퍼파라미터는 다음과 같습니다.
반면 매개변수는 가중치 및 편향과 같이 모델 자체에 속하는 변수입니다. 즉, 초매개변수는 사용자가 제어하는 값이고 매개변수는 모델이 학습 중에 계산하는 값입니다.
학습률
학습률은 모델이 수렴하는 속도에 영향을 미치는 부동 소수점 숫자입니다. 학습률이 너무 낮으면 모델이 수렴하는 데 시간이 오래 걸릴 수 있습니다. 하지만 학습률이 너무 높으면 모델이 수렴하지 않고 손실을 최소화하는 가중치와 편향을 중심으로 바운스합니다. 목표는 모델이 빠르게 수렴할 수 있도록 너무 높지도 너무 낮지도 않은 학습률을 선택하는 것입니다.
학습률은 경사하강법 프로세스의 각 단계에서 가중치와 편향에 적용할 변경사항의 크기를 결정합니다. 모델은 경사에 학습률을 곱하여 다음 반복의 모델 매개변수 (가중치 및 편향 값)를 결정합니다. 경사 하강법의 세 번째 단계에서 음의 기울기 방향으로 이동하는 '소량'은 학습률을 의미합니다.
이전 모델 매개변수와 새 모델 매개변수의 차이는 손실 함수의 기울기에 비례합니다. 예를 들어 경사가 크면 모델이 큰 단계를 취합니다. 작은 경우 작은 단계를 취합니다. 예를 들어 그라데이션의 크기가 2.5이고 학습률이 0.01이면 모델은 매개변수를 0.025만큼 변경합니다.
이상적인 학습률은 모델이 적절한 수의 반복 내에 수렴하도록 지원합니다. 그림 20에서 손실 곡선은 모델이 처음 20번의 반복 동안 크게 개선된 후 수렴하기 시작하는 것을 보여줍니다.
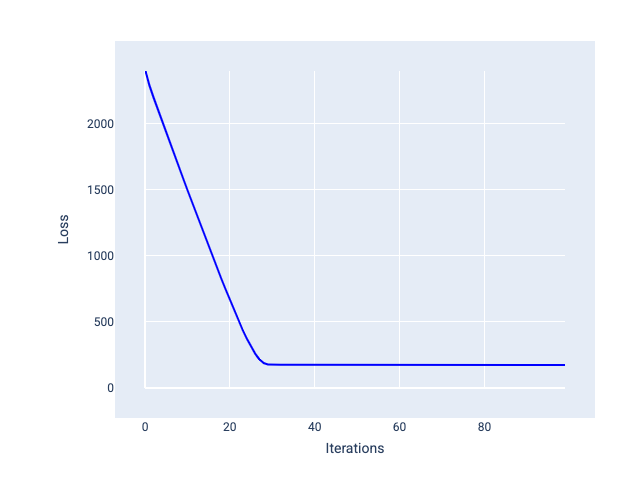
그림 20. 학습률이 빠르게 수렴되도록 학습된 모델을 보여주는 손실 그래프
반대로 학습률이 너무 작으면 수렴하는 데 너무 많은 반복이 필요할 수 있습니다. 그림 21에서 손실 곡선은 모델이 각 반복 후 약간만 개선됨을 보여줍니다.
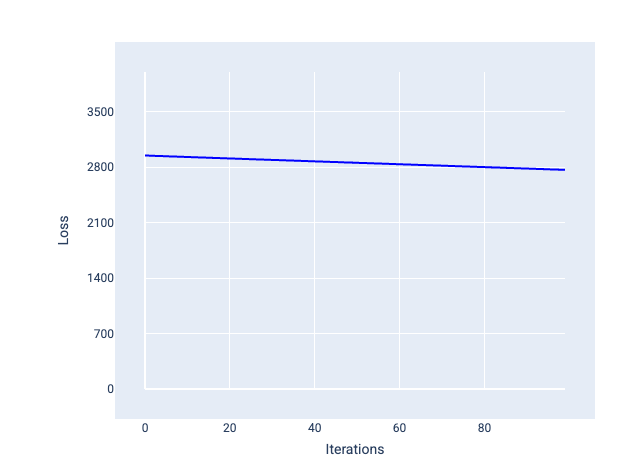
그림 21. 작은 학습률로 학습된 모델을 보여주는 손실 그래프
학습률이 너무 크면 각 반복으로 인해 손실이 튀거나 계속 증가하므로 수렴되지 않습니다. 그림 22에서 손실 곡선은 각 반복 후 모델의 손실이 감소했다가 증가하는 것을 보여주고, 그림 23에서는 후반 반복에서 손실이 증가합니다.
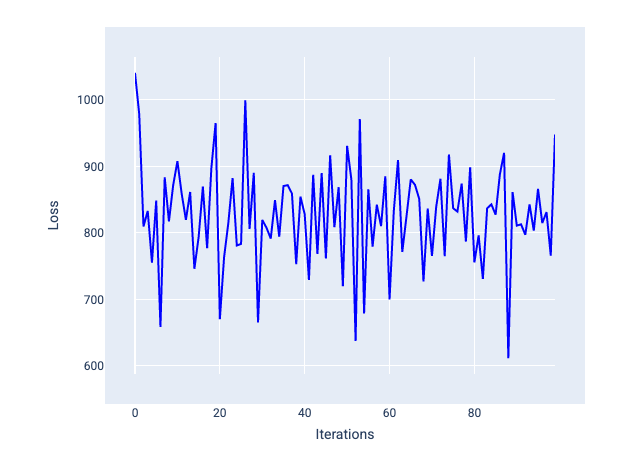
그림 22. 학습률이 너무 커서 학습된 모델을 보여주는 손실 그래프로, 반복이 증가함에 따라 손실 곡선이 위아래로 크게 변동합니다.
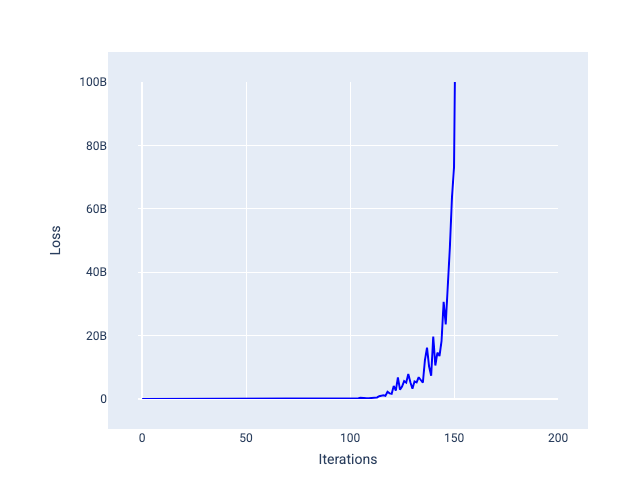
그림 23. 학습률이 너무 커서 학습된 모델을 보여주는 손실 그래프로, 후반 반복에서 손실 곡선이 급격히 증가합니다.
연습: 학습 내용 점검하기
배치 크기
배치 크기는 모델이 가중치와 편향을 업데이트하기 전에 처리하는 예의 수를 나타내는 하이퍼파라미터입니다. 가중치와 편향을 업데이트하기 전에 데이터 세트의 모든 예에 대한 손실을 모델이 계산해야 한다고 생각할 수 있습니다. 하지만 데이터 세트에 수십만 또는 수백만 개의 예가 포함된 경우 전체 배치를 사용하는 것은 실용적이지 않습니다.
가중치와 편향을 업데이트하기 전에 데이터 세트의 모든 예시를 살펴보지 않고도 평균에 적합한 기울기를 얻는 두 가지 일반적인 기법은 확률적 경사 하강법과 미니 배치 확률적 경사 하강법입니다.
확률적 경사하강법 (SGD): 확률적 경사하강법은 반복당 하나의 예 (배치 크기 1)만 사용합니다. 반복 횟수가 충분하면 SGD가 작동하지만 노이즈가 매우 많습니다. '노이즈'는 반복 중에 손실이 감소하지 않고 증가하도록 하는 학습 중 변동을 의미합니다. '확률적'이라는 용어는 각 배치로 구성된 하나의 예가 무작위로 선택됨을 나타냅니다.
다음 이미지에서 모델이 SGD를 사용하여 가중치와 편향을 업데이트할 때 손실이 약간 변동되어 손실 그래프에 노이즈가 발생할 수 있습니다.
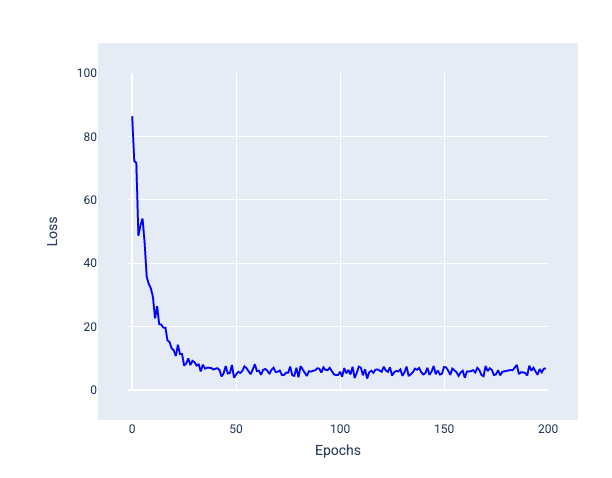
그림 24. 손실 곡선에 노이즈가 표시된 확률적 경사하강법 (SGD)으로 학습된 모델
확률적 경사 하강법을 사용하면 수렴 근처뿐만 아니라 전체 손실 곡선에 걸쳐 노이즈가 발생할 수 있습니다.
미니 배치 확률적 경사하강법 (미니 배치 SGD): 미니 배치 확률적 경사하강법은 전체 배치와 SGD의 절충안입니다. $ N $ 개의 데이터 포인트의 경우 배치 크기는 1보다 크고 $ N $보다 작은 숫자일 수 있습니다. 모델은 각 배치에 포함된 예시를 무작위로 선택하고, 경사를 평균화한 다음, 반복당 한 번씩 가중치와 편향을 업데이트합니다.
각 배치에 대한 예시 수는 데이터 세트와 사용 가능한 컴퓨팅 리소스에 따라 달라집니다. 일반적으로 배치 크기가 작으면 SGD와 유사하게 작동하고 배치 크기가 크면 전체 배치 경사 하강법과 유사하게 작동합니다.
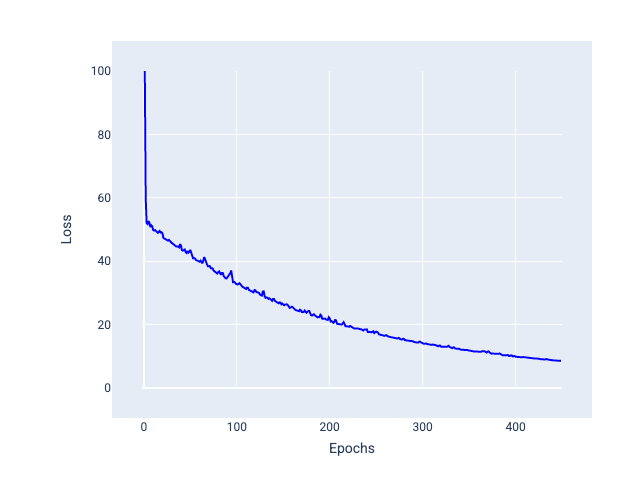
그림 25. 미니 배치 SGD로 학습된 모델
모델을 학습할 때 노이즈는 제거해야 하는 바람직하지 않은 특성이라고 생각할 수 있습니다. 하지만 어느 정도의 노이즈는 좋은 것일 수 있습니다. 후반 모듈에서는 노이즈가 모델의 일반화를 개선하고 신경망에서 최적의 가중치와 편향을 찾는 데 어떻게 도움이 되는지 알아봅니다.
에포크
학습 중에 에포크는 모델이 학습 세트의 모든 예시를 한 번 처리했음을 의미합니다. 예를 들어 1,000개의 예시가 있는 학습 세트와 100개의 예시가 있는 미니 배치 크기가 주어지면 모델이 한 에포크를 완료하는 데 10개의 반복이 필요합니다.
학습에는 일반적으로 많은 에포크가 필요합니다. 즉, 시스템은 학습 세트의 모든 예시를 여러 번 처리해야 합니다.
에포크 수는 모델이 학습을 시작하기 전에 설정하는 하이퍼파라미터입니다. 모델이 수렴하는 데 필요한 에포크 수를 실험해야 하는 경우가 많습니다. 일반적으로 에포크 수가 많을수록 모델이 더 좋아지지만 학습 시간도 더 오래 걸립니다.
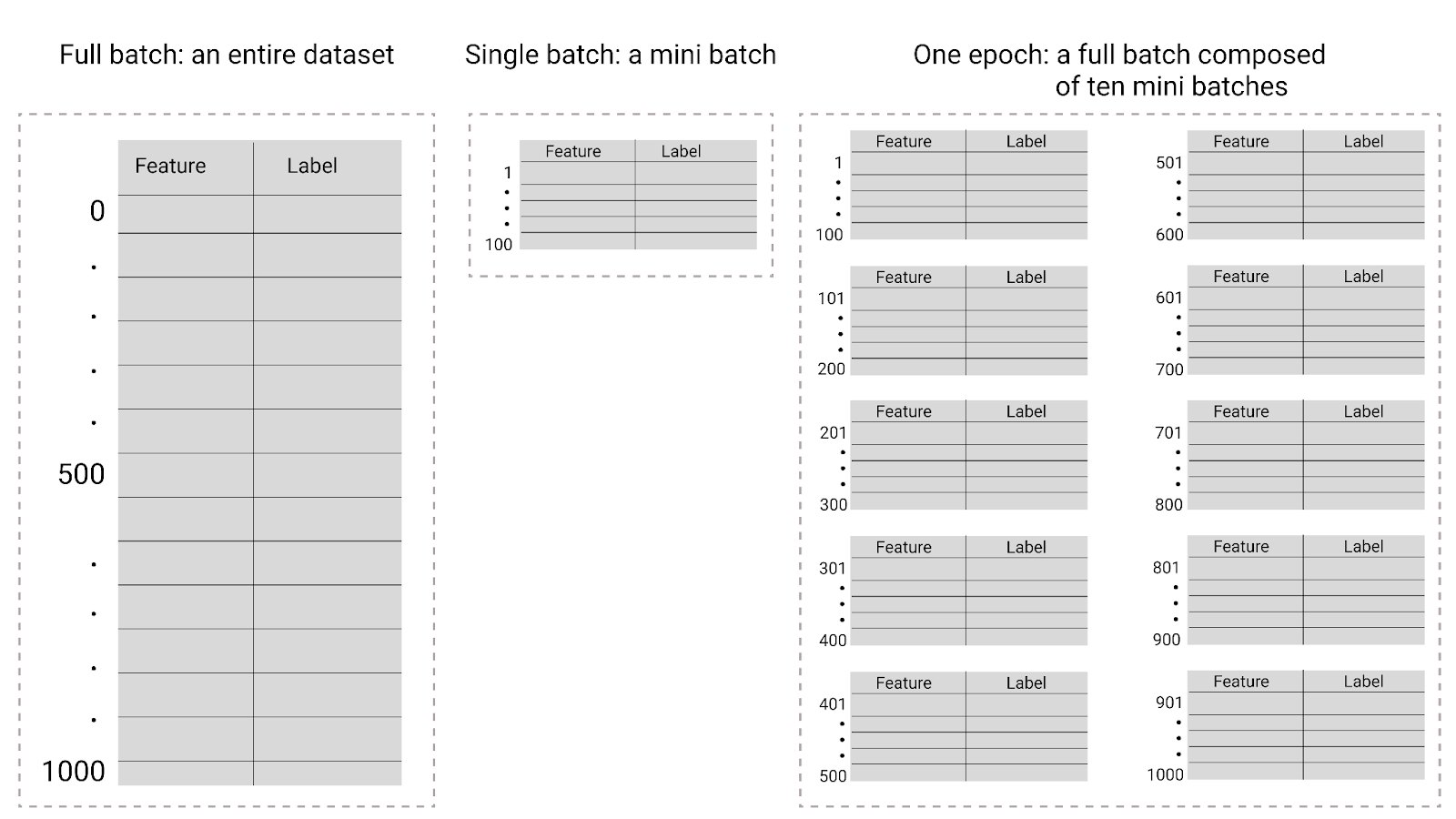
그림 26. 전체 배치와 미니 배치
다음 표에서는 배치 크기와 에포크가 모델이 매개변수를 업데이트하는 횟수와 어떤 관련이 있는지 설명합니다.
| 일괄 유형 | 가중치 및 편향 업데이트가 발생하는 경우 |
|---|---|
| 전체 배치 | 모델이 데이터 세트의 모든 예시를 살펴본 후 예를 들어 데이터 세트에 1,000개의 예가 포함되어 있고 모델이 20번의 에포크 동안 학습하는 경우 모델은 에포크당 한 번씩 가중치와 편향을 20번 업데이트합니다. |
| 확률적 경사하강법 | 모델이 데이터 세트의 단일 예시를 살펴본 후 예를 들어 데이터 세트에 1,000개의 예가 포함되어 있고 20에포크 동안 학습하는 경우 모델은 가중치와 편향을 20,000번 업데이트합니다. |
| 미니 배치 확률적 경사하강법 | 모델이 각 배치에 있는 예시를 살펴본 후 예를 들어 데이터 세트에 1,000개의 예시가 있고 배치 크기가 100이며 모델이 20에포크 동안 학습하는 경우 모델은 가중치와 편향을 200회 업데이트합니다. |